
一致性协议
Gossip 协议
集群往往是由多个节点共同组成的,当一个节点加入集群或者一个节点从集群中下线的时候,都需要让集群中其他的节点知道,这样才能将数据信息分享给新节点而忽略下线节点。
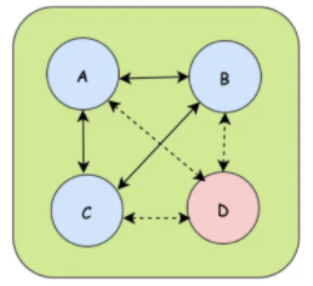
如上图,A、B、C 节点之间可以互相传递消息,但是D节点在下线之后会被广播告诉其他存活节点。这样的广播协议就是今天要说Gossip协议,Gossip协议也叫Epidemic协议(流行病协议),当一个消息到来时,通过Gossip协议就可以像病毒一样感染全部集群节点。Gossip的过程是由一个种子节点发起的,当一个种子节点有信息需要同步到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,所以不能保证某个时间点所有的节点都有该条消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
Gossip协议的特点:
Gossip协议是周期性散播消息,每隔一段时间传播一次
被感染的节点,每次可以继续散播N个节点
每次散播消息时,都会选择尚未发送过的节点进行散播,不会向发送的节点散播
同一个节点可能会收到重复的消息,因为可能同时多个节点正好向它散播
集群是去中心化的,节点之间都是平等的
消息的散播不用等接收节点的 ack,即消息可能会丢失,但是最终应该会被感染
下面我们来看个例子:
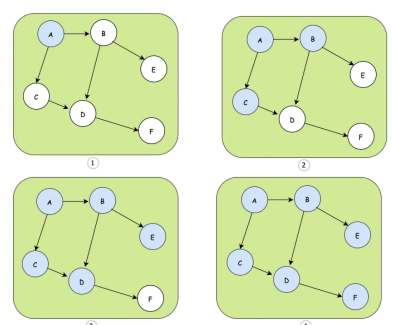
- ① 种子节点是A
- ② A节点选择B、C节点进行散播
- ③ C散播到D,B散播D和E,可以发现D收到两次
- ④ D散播到F,最终整个网络都同步到了消息
Gossip有点类似图的广度优先遍历算法,一般用于网络拓扑结构信息的分享和维护,比如 Redis 集群中节点的运行状态就是使用 Gossip 协议进行传递的。
Raft一致性协议
超详细解析|一致性协议算法-2PC、3PC、Paxos、Raft、ZAB、NWR
分布式协议的难点之一就是数据的一致性,当由多个节点组成的集群中只有一个节点收到数据,我们就算成功的话,风险太大,当要求所有节点都收到数据才响应成功,性能又太差,所以一般会在数据的安全和性能之间做个折中,只要保证绝大部分节点同步数据成功,我们就算成功。比较知名的一致性算法有Raft算法,被广泛应用于许多中间件中,接下来我们就看看Raft算法是实现分布式系统的不同节点间的数据一致性的,也就是说客户端发送请求到任何一个节点都能收到一致的返回,当一个节点出故障后,其他节点仍然能以已有的数据正常进行。
首先介绍下在Raft算法中,几种情况下每个节点对应的角色:
- Leader节点:同大多数分布式中的Leader节点一样,所有数据的变更都需要先经过Leader
- Follower节点:Leader节点的追随者,负责复制数据并且在选举时候投票的节点
- Candidate候选节点:参与选举的节点,就是Follower节点参与选举时会切换的角色
Raft算法将一致性问题分解为两个的子问题,Leader选举 + 数据日志的复制:
Leader 选举
系统在刚开始的时候,所有节点都是Follower节点,这时都有机会参与选举,将自己变成Candidate,变成Candidate的节点会先投自己1票,同时告诉其它节点,让它们来投票,当拿到超过半数以上的投票时,当前Candidate就会变成Leader节点。但是如果每个Follower节点都变成Candidate那么就会陷入无限的死循环,于是每个Follower都一个定时器,并且定时器的时间是随机的,当某个Follower的定时器时间走完之后,会确认当前是否存在Leader节点,如果不存在再把自己变成Candidate。
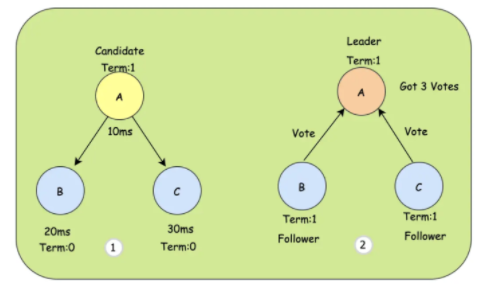
① 由于A节点的定时器时间最短(10ms),所以A会成为Candidate。
② A投自己一票,并告诉B、C来投票,B、C也投出自己的同意票后,A就会变成Leader节点,同时会记录是第M任。这个M是做版本校验的,比如一个编号是10的节点,收到了一个编号是9的节点的投票请求,那么就会拒绝这个请求。
在Leader节点选举出来以后,Leader节点会不断的发送心跳给其它Follower节点证明自己是活着的,其他Follower节点在收到心跳后会清空自己的定时器,并回复给Leader,因为此时没必要触发选举了。
如果Leader节点在某一刻挂了,那么Follower节点就不会收到心跳,因此在定时器到来时就会触发新一轮的选举,流程还是一样。但是如果恰巧两个Follower都变成了Candidate,并且都得到了同样的票数,那么此时就会陷入僵局,为了打破僵局,这时每个Candidate都会随机推迟一段时间再次请求投票,当然一般情况下,就是先来先得,优先跑完定时器的Candidate理论成为Leader的概率更大。
选举流程大致如上,接下来我们来看看数据日志的复制。
数据日志的复制
当Leader节点收到客户端Client的请求变更时,会把变更记录到log中,然后Leader会将这个变更随着下一次的心跳通知给Follower节点,收到消息的Follower节点把变更同样写入日志中,然后回复Leader节点,当Leader收到大多数的回复后,就把变更写入自己的存储空间,同时回复client,并告诉Follower应用此log。至此,集群就变更达成了共识。
正常情况下的日志复制:
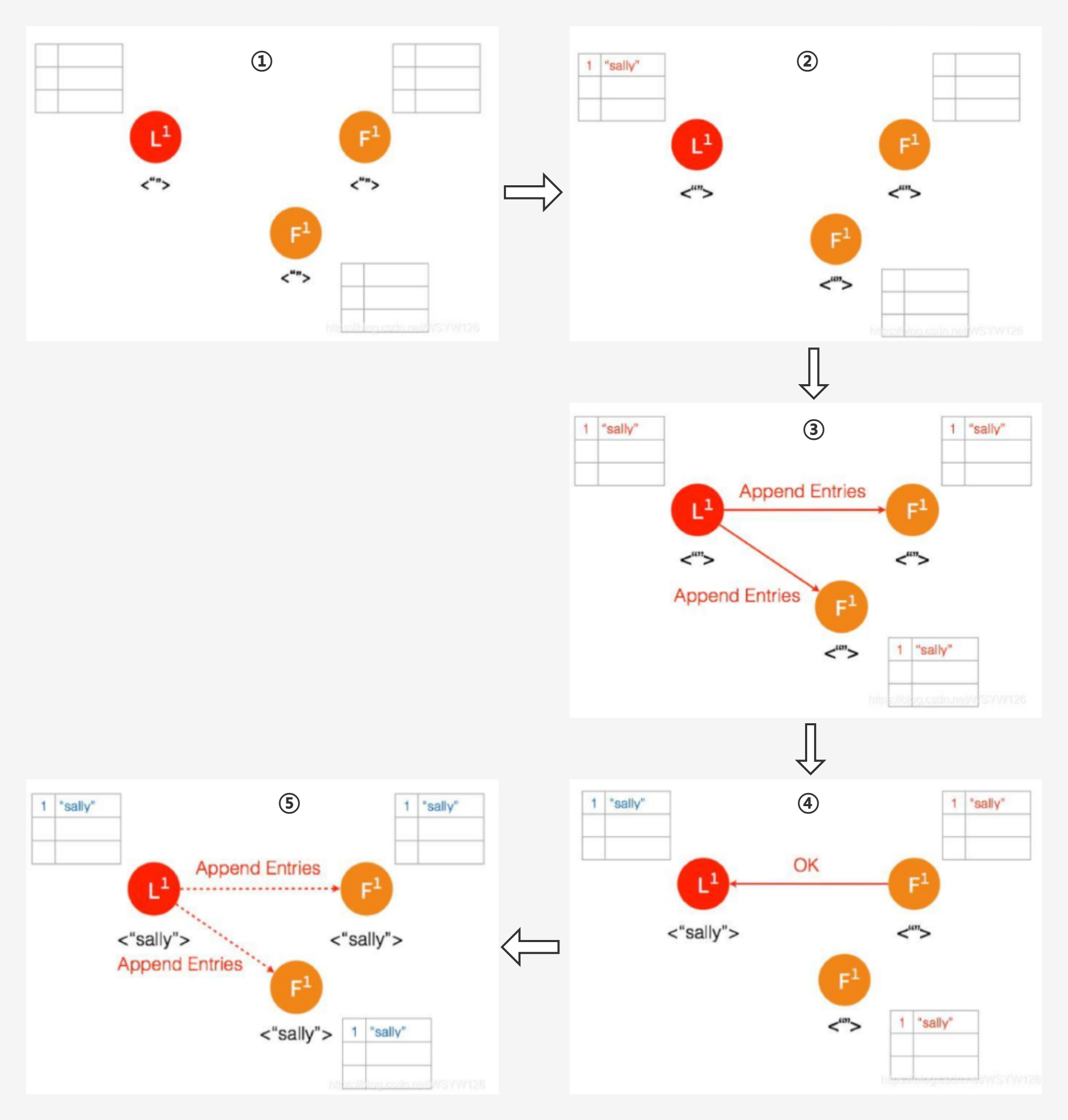
① 一开始,Leader 和两个 Follower 都没有任何数据。
② 客户端发送请求给 Leader,储存数据 “sally”,Leader 先将数据写在本地日志,这时候数据状态还是 Uncommitted (还没最终确认,使用红色表示)
③ Leader 给两个 Follower 节点发送 AppendEntries 请求,数据在 Follower 上没有冲突,则将数据暂时写在本地日志,Follower 的数据也还是 Uncommitted
④ Follower 将数据写到本地后,返回 OK。Leader 收到后成功返回,只要收到的成功的返回数量超过半数 (包含Leader),Leader 将数据 “sally” 的状态改成 Committed。( 这个时候 Leader 就可以返回给客户端了)
⑤ Leader 再次给 Follower 发送 AppendEntries 请求,收到请求后,Follower 将本地日志里 Uncommitted 数据改成 Committed。这样就完成了整个复制日志的过程,三个节点的数据是一致的,
Network Partition 网络分区情况下日志复制:
在 Network Partition 的情况下,部分节点之间没办法互相通信,Raft 也能保证这种情况下数据的一致性
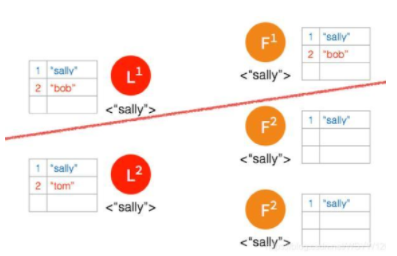
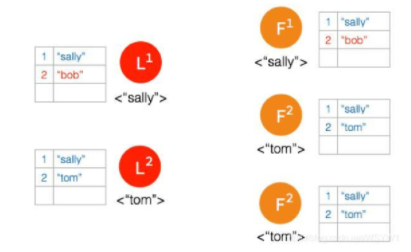
- 一开始有 5 个节点处于同一网络状态下,如下图:
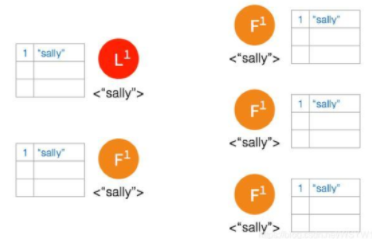
Network Partition 将节点分成两边,一边有两个节点,一边三个节点:
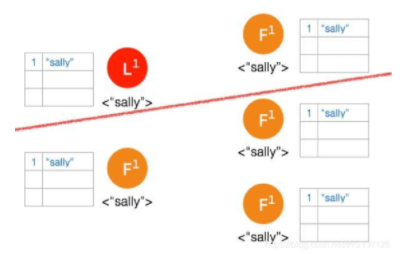
两个节点这边已经有 Leader 了,来自客户端的数据 “bob” 通过 Leader 同步到 Follower
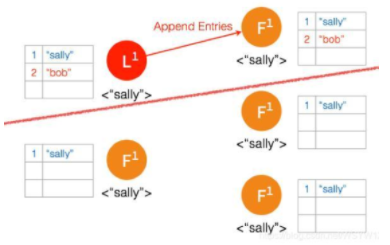
只有两个节点,少于3个节点,所以 “bob” 的状态仍是 Uncommitted。所以在这里,服务器会返回错误给客户端
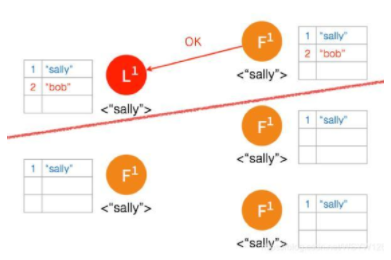
另外一个 Partition 有三个节点,进行重新选主
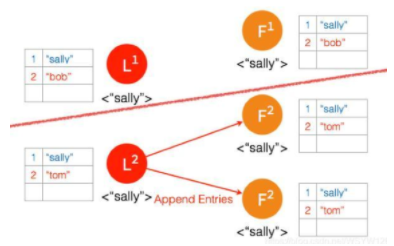
客户端数据 “tom” 发到新的 Leader2,并通过和上节网络状态下相似的过程,同步到另外两个 Follower;但因为这个 Partition 有3个节点,超过半数,所以数据 “tom” 都 Commit 了
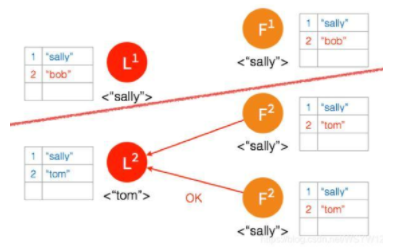
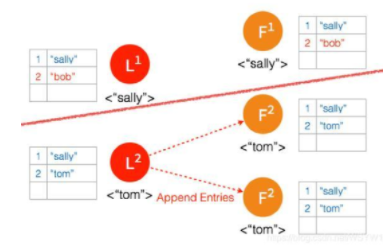
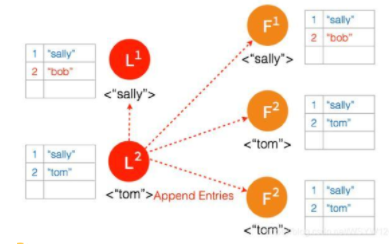
网络状态恢复,5个节点再次处于同一个网络状态下。但是这里出现了数据冲突 “bob" 和 “tom"
三个节点的 Leader2 广播 AppendEntries
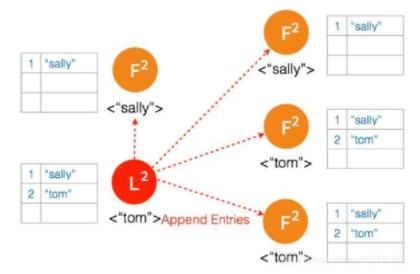
两个节点 Partition 的 Leader 自动降级为 Follower,因为这个 Partition 的数据 “bob” 没有 Commit,返回给客户端的是错误,客户端知道请求没有成功,所以 Follower 在收到 AppendEntries 请求时,可以把 “bob“ 删除,然后同步 ”tom”,通过这么一个过程,就完成了在 Network Partition 情况下的复制日志,保证了数据的一致性。
相关文章:
常见的服务器架构入门:从单体架构、EAI 到 SOA 再到微服务和 ServiceMesh
常见分布式理论(CAP、BASE)和一致性协议(Gosssip协议、Raft一致性算法)
SpringCloud OpenFeign 远程HTTP服务调用用法与原理
Sentinel-Dashboard 与 apollo 规则的相互同步
Spring Cloud Gateway 服务网关的部署与使用详细介绍
Spring Cloud Gateway 整合 sentinel 实现流控熔断
Spring Cloud Gateway 整合 knife4j 聚合接口文档