
调优
MySQL的一些调优经验
EXPLAIN
什么是explain
使用explain可以模拟优化器执行SQL查询语句,从而知道MySQL怎么处理你的SQL语句的,分析你的查询语句和表结构的性能瓶颈。
explain能够干什么
- 读取表的顺序
- 哪些索引能够被使用
- 数据读取操作的操作类型
- 哪些索引能够被实际使用
- 表之间的引用
- 每张表有多少行被物理查询
创建一个学习用的数据库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mydb` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `mydb`;
/*Table structure for table `course` */
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8;
/*Data for the table `course` */
insert into `course`(`id`,`name`) values
(1,'语文'),(2,'高等数学'),(3,'视听说'),(4,'体育'),(5,'马克思概况'),(6,'民族理论'),(7,'毛中特'),(8,'计算机基础'),(9,'深度学习'),(10,'Java程序设计'),(11,'c语言程序设计'),(12,'操作系统'),(13,'计算机网络'),(14,'计算机组成原理'),(15,'数据结构'),(16,'数据分析'),(17,'大学物理'),(18,'数字逻辑'),(19,'嵌入式开发'),(20,'需求工程');
/*Table structure for table `stu_course` */
DROP TABLE IF EXISTS `stu_course`;
CREATE TABLE `stu_course` (
`sid` int(10) NOT NULL,
`cid` int(10) NOT NULL,
PRIMARY KEY (`sid`,`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `stu_course` */
insert into `stu_course`(`sid`,`cid`) values
(1,2),(1,4),(1,14),(1,16),(1,19),(2,4),(2,8),(2,9),(2,14),(3,13),(3,14),(3,20),(4,5),(4,8),(4,9),(4,11),(4,16),(5,4),(5,8),(5,9),(5,11),(5,12),(5,16),(6,2),(6,14),(6,17),(7,1),(7,8),(7,15),(8,2),(8,3),(8,7),(8,17),(9,1),(9,7),(9,16),(9,20),(10,4),(10,12),(10,14),(10,20),(11,3),(11,9),(11,16),(12,3),(12,7),(12,9),(12,12),(13,1),(13,5),(13,13),(14,1),(14,3),(14,18),(15,1),
(15,9),(15,15),(16,2),(16,7);
/*Table structure for table `student` */
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`age` int(2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`),
KEY `name_age` (`name`,`age`),
KEY `id_name_age` (`id`,`name`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=31 DEFAULT CHARSET=utf8;
/*Data for the table `student` */
insert into `student`(`id`,`name`,`age`) values
(25,'乾隆',17),(14,'关羽',43),(13,'刘备',12),(28,'刘永',12),(21,'后裔',12),(30,'吕子乔',28),(18,'嬴政',76),(22,'孙悟空',21),(4,'安其拉',24),(6,'宋江',22),(26,'康熙',51),(29,'张伟',26),(20,'张郃',12),(12,'张飞',32),(27,'朱元璋',19),(11,'李世民',54),(9,'李逵',12),(8,'林冲',43),(5,'橘右京',43),(24,'沙和尚',25),(23,'猪八戒',22),(15,'王与',21),(19,'王建',23),(10,'王莽',43),(16,'秦叔宝',43),(17,'程咬金',65),(3,'荆轲',21),(2,'诸葛亮',71),(7,'钟馗',23),(1,'鲁班',21);
这个数据库实际上的业务是:学生表 - 选课表 - 课程表
如何使用explain
使用而explain很简单就是,在你书写的SQL语句加一个单词 - explain,然后将 explain + SQL执行后会出现一个表,这个表会告诉你MySQL优化器是怎样执行你的SQL的。
就比如执行下面一句语句:
EXPLAIN SELECT * FROM student
MySQL会给你反馈下面一个信息:
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
------ ----------- ------- ---------- ------ ------------- -------- ------- ------ ------ -------- -------------
1 SIMPLE student (NULL) index (NULL) name_age 68 (NULL) 30 100.00 Using index
具体这些信息是干什么的,会对你有什么帮助,会在下面告诉你。
explain各个字段代表的意思
- id :select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- select_type :查询类型 或者是 其他操作类型
- table :正在访问哪个表
- partitions :匹配的分区
- type :访问的类型
- possible_keys :显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到
- key :实际使用到的索引,如果为NULL,则没有使用索引
- key_len :表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
- ref :显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值
- rows :根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数
- filtered :查询的表行占表的百分比
- Extra :包含不适合在其它列中显示但十分重要的额外信息
上面介绍了每个字段的意思,可以大体看一下,下面会逐一介绍每个字段表示的啥?该关注什么?
id与table字段
为什么要将id和table放在一起讲呢?因为通过这两个字段可以完全判断出你的每一条SQL语句的执行顺序和表的查询顺序。
先看id后看table,id和table在SQL执行判断过程中的关系就像是足球联赛的积分榜,首先一个联赛的球队排名应该先看积分,积分越高的球队排名越靠前,当两支或多只球队的积分一样高怎么办呢?那我们就看净胜球,净胜球越多的球队,排在前面。而在explain中你可以把id看作是球队积分,table当作是净胜球。
比如说我们explain一下这一条SQL:
EXPLAIN
SELECT
S.id,S.name,S.age,C.id,C.name
FROM course C JOIN stu_course SC ON C.id = SC.cid
JOIN student S ON S.id = SC.sid
结果是这样:
id select_type table partitions type possible_keys key key_len ref
------ ----------- ------ ---------- ------ ------------------- ------- ------- -----------
1 SIMPLE SC (NULL) index PRIMARY PRIMARY 8 (NULL)
1 SIMPLE C (NULL) eq_ref PRIMARY PRIMARY 4 mydb.SC.cid
1 SIMPLE S (NULL) eq_ref PRIMARY,id_name_age PRIMARY 4 mydb.SC.sid
我们看到id全是1,那就说明光看id这个值是看不出来每个表的读取顺序的,那我们就来看table这一行,它的读取顺序是自上向下的,所以,这三个表的读取顺序应当是:SC - C - S。
再来看一条SQL
EXPLAIN
SELECT *
FROM course AS C
WHERE C.`id` = (
SELECT SC.`cid`
FROM stu_course AS SC
WHERE SC.`sid` =
(
SELECT
S.`id`
FROM student AS S
WHERE S.`name` = "安其拉"
) ORDER BY SC.`cid` LIMIT 1
)
这条语句是查询结果是:一个叫安其拉的学生选的课里面,课程id最小的一门课的信息,然后来看一下explain的结果吧!
id select_type table partitions type possible_keys key key_len ref
------ ----------- ------ ---------- ------ ------------- ------- ------- ------
1 PRIMARY C (NULL) const PRIMARY PRIMARY 4 const
2 SUBQUERY SC (NULL) ref PRIMARY PRIMARY 4 const
3 SUBQUERY S (NULL) ref name,name_age name 63 const
此时我们发现id是不相同的,所以我们很容易就看出表读取的顺序了是吧!C - SC - S
注意!!!!!!你仔细看一下最里面的子查询是查询的哪个表,是S这张表,然后外面一层呢?是SC这张表,最外面这一层呢?是C这张表,所以执行顺序应该是啥呢?是....是.....难道是S - SC - C吗?是id越大的table读取越在前面吗?是的!这就像刚才说的足球联赛积分,分数越高的球队的排序越靠前。
当然还有下面这种情况
EXPLAIN
SELECT *
FROM course AS C
WHERE C.`id` IN (
SELECT SC.`cid`
FROM stu_course AS SC
WHERE SC.`sid` =
(
SELECT
S.`id`
FROM student AS S
WHERE S.`name` = "安其拉"
)
)
这个查询是:查询安其拉选课的课程信息
id select_type table partitions type possible_keys key key_len ref
------ ----------- ------ ---------- ------ ------------- ------- ------- -----------
1 PRIMARY SC (NULL) ref PRIMARY PRIMARY 4 const
1 PRIMARY C (NULL) eq_ref PRIMARY PRIMARY 4 mydb.SC.cid
3 SUBQUERY S (NULL) ref name,name_age name 63 const
结果很明确:先看id应该是S表最先被读取,SC和C表id相同,然后table中SC更靠上,所以第二张读取的表应当是SC,最后读取C。
select_type字段
SIMPLE简单查询,不包括子查询和union查询EXPLAIN SELECT * FROM student JOIN stu_course ON student.`id` = sidid select_type table partitions type possible_keys key ------ ----------- ---------- ---------- ------ ------------------- -------- 1 SIMPLE student (NULL) index PRIMARY,id_name_age name_age 1 SIMPLE stu_course (NULL) ref PRIMARY PRIMARYPRIMARY当存在子查询时,最外面的查询被标记为主查询SUBQUERY子查询EXPLAIN SELECT SC.`cid` FROM stu_course AS SC WHERE SC.`sid` = ( SELECT S.`id` FROM student AS S WHERE S.`name` = "安其拉" )id select_type table partitions type possible_keys key key_len ref ------ ----------- ------ ---------- ------ ------------- ------- ------- ------ 1 PRIMARY SC (NULL) ref PRIMARY PRIMARY 4 const 2 SUBQUERY S (NULL) ref name,name_age name 63 constUNION当一个查询在UNION关键字之后就会出现UNIONUNION RESULT连接几个表查询后的结果EXPLAIN SELECT * FROM student WHERE id = 1 UNION SELECT * FROM student WHERE id = 2id select_type table partitions type possible_keys key ------ ------------ ---------- ---------- ------ ------------------- ------- 1 PRIMARY student (NULL) const PRIMARY,id_name_age PRIMARY 2 UNION student (NULL) const PRIMARY,id_name_age PRIMARY (NULL) UNION RESULT <union1,2> (NULL) ALL (NULL) (NULL)上面可以看到第三行
table的值是<union1,2>DERIVED在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL 会递归执行这些子查询,把结果放在临时表中 MySQL5.7+ 进行优化了,增加了derived_merge(派生合并),默认开启,可加快查询效率当你的MySQL是5.7及以上版本时你要将derived_merge关闭后才能看到
DERIVED状态set session optimizer_switch='derived_merge=off'; set global optimizer_switch='derived_merge=off';EXPLAIN SELECT * FROM ( SELECT * FROM student AS S JOIN stu_course AS SC ON S.`id` = SC.`sid` ) AS SSCid select_type table partitions type possible_keys key ------ ----------- ---------- ---------- ------ ------------------- -------- 1 PRIMARY \<derived2\> (NULL) ALL (NULL) (NULL) 2 DERIVED S (NULL) index PRIMARY,id_name_age name_age 2 DERIVED SC (NULL) ref PRIMARY PRIMARY上面我们观察,最外层的主查询的表是<derived2>,而S和SC表的
select_type都是DERIVED,这说明S和SC都被用来做衍生查询,而这两张表查询的结果组成了名为<derived2>的衍生表,而衍生表的命名就是<select_type + id>。
partitions字段
该列显示的为分区表命中的分区情况。非分区表该字段为空(null)。
type字段
type所显示的是查询使用了哪种类型,所有type按照从好到坏的顺序排列如下:
system > const > eq_ref > ref > range > index > all
system:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计;
const:表示通过索引一次就找到了,const用于primary key或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where语句中,MySQL就能将该查询转换为一个常量;
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描;
ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体;
range:只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引,一般就是在你的where语句中出现between, <, >, in等的查询,这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引;
index:全表扫描,index与all区别为index类型只遍历索引树。这通常比all快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘读取的);
all:全表扫描,将遍历全表以找到匹配的行,避免 all
possible_keys字段
这个表里面存在且可能会被使用的索引,可能会在这个字段下面出现,但是一般都以key为准。
key字段
实际使用的索引,如果为null,则没有使用索引,否则会显示你使用了哪些索引,查询中若使用了覆盖索引(查询的列刚好是索引),则该索引仅出现在key列表。
ref字段
显示哪些列被使用了,如果可能的话,最好是一个常数。哪些列或常量被用于查找索引列上的值。
rows字段和Filter字段
rows是根据表的统计信息和索引的选用情况,优化器大概帮你估算出你执行这行函数所需要查询的行数。
Filter是查询的行数与总行数的比值。其实作用与rows差不多,都是数值越小,效率越高。
Extra字段
这一字段包含不适合在其他列显示,但是也非常重要的额外信息。
Using filesort表示当SQL中有一个地方需要对一些数据进行排序的时候,优化器找不到能够使用的索引,所以只能使用外部的索引排序,外部排序就不断的在磁盘和内存中交换数据,这样就摆脱不了很多次磁盘IO,以至于SQL执行的效率很低。反之呢?由于索引的底层是B+Tree实现的,他的叶子节点本来就是有序的,这样的查询能不爽吗?EXPLAIN SELECT * FROM course AS C ORDER BY C.`name`type possible_keys key key_len ref rows filtered Extra ------ ------------- ------ ------- ------ ------ -------- ---------------- ALL (NULL) (NULL) (NULL) (NULL) 20 100.00 Using filesort没有给
C.name建立索引,所以在根据C.name排序的时候,他就使用了外部排序Using tempporary表示在对MySQL查询结果进行排序时,使用了临时表,,这样的查询效率是比外部排序更低的,常见于order by和group by。EXPLAIN SELECT C.`name` FROM course AS C GROUP BY C.`name`possible_keys key key_len ref rows filtered Extra ------------- ------ ------- ------ ------ -------- --------------------------------- (NULL) (NULL) (NULL) (NULL) 20 100.00 Using temporary; Using filesort上面这个查询就是同时触发了
Using temporary和Using filesort,可谓是雪上加霜。Using index表示使用了索引,很优秀👍。Using where使用了where但是好像没啥用。Using join buffer表明使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓冲区的join buffer调大一些。impossible where筛选条件没能筛选出任何东西distinct优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
MySQL数据库CPU飙升如何定位分析
使用top观察mysqld的cpu利用率(确认问题是由mysqld产生的)
切换到常用的数据库
使用 show full processlist 查看会话
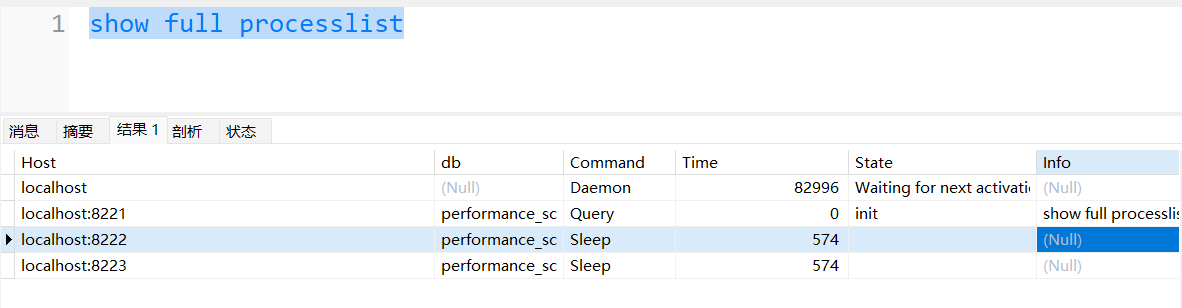
观察是哪些sql消耗了资源,其中重点观察state指标
定位到具体sql
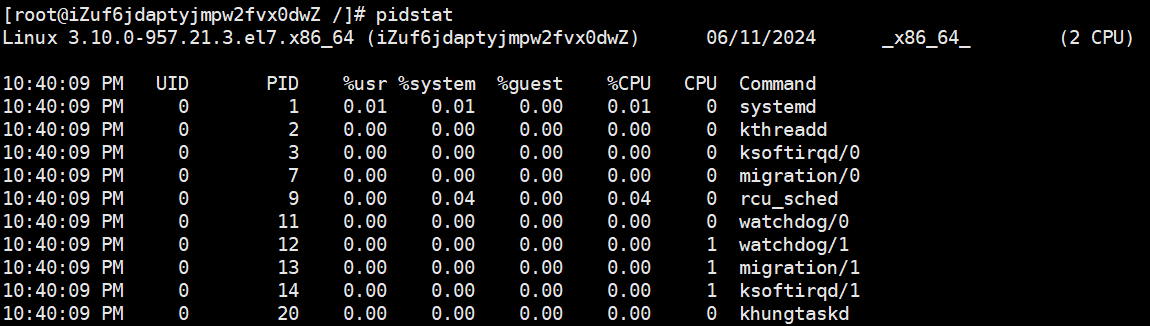
使用pidstate
定位到线程
在数据库 performance_schema.threads 中记录了 thread_os_id 找到执行的sql
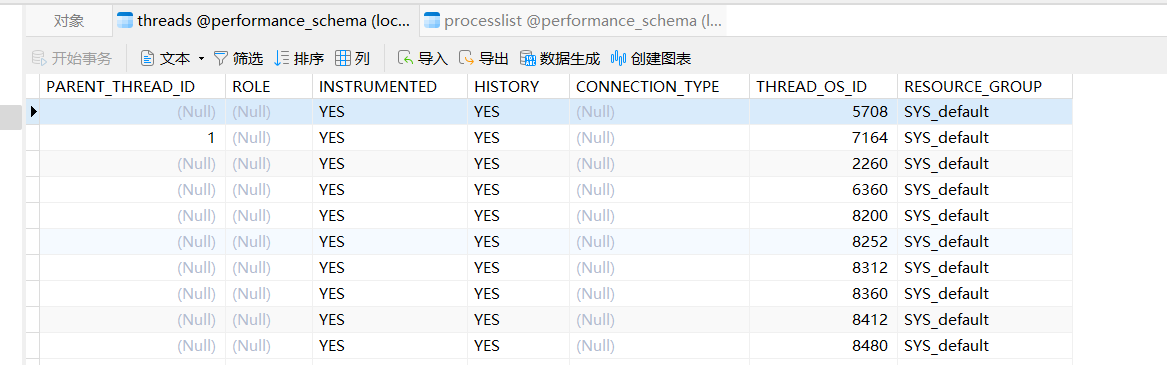
根据操作系统id可以到 performance_schema.processlist 表找到对应的会话

在会话中即可定位到问题sql