
Lua脚本
Lua脚本是一种轻量级的脚本语言,常嵌入到Redis等数据库中,用于执行复杂的、原子性的操作序列,通过一次性执行多个命令来减少网络开销并避免并发问题,增强数据处理的安全性和效率。
简介
从 Redis 2.6.0 版本开始,通过内置的 Lua 解释器,可以使用 EVAL 命令对 Lua 脚本进行求值。在lua脚本中可以通过两个不同的函数调用redis命令,分别是:redis.call() 和 redis.pcall()
脚本的原子性
Redis 使用单个 Lua 解释器去运行所有脚本,并且, Redis 也保证脚本会以原子性**(atomic)的方式执行:当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。**这和使用 MULTI / EXEC 包围的事务很类似。在其他别的客户端看来,脚本的效果(effect)要么是不可见的(not visible),要么就是已完成的(already completed)。
另一方面,这也意味着,执行一个运行缓慢的脚本并不是一个好主意。写一个跑得很快很顺溜的脚本并不难,因为脚本的运行开销(overhead)非常少,但是当你不得不使用一些跑得比较慢的脚本时,请小心,因为当这些蜗牛脚本在慢吞吞地运行的时候,其他客户端会因为服务器正忙而无法执行命令。
错误处理
redis.call() 和 redis.pcall() 的唯一区别在于它们对错误处理的不同。
当 redis.call() 在执行命令的过程中发生错误时,脚本会停止执行,并返回一个脚本错误,错误的输出信息会说明错误造成的原因
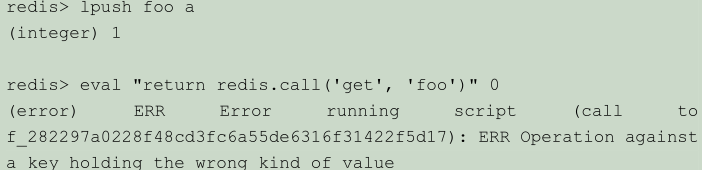
redis.pcall() 出错时并不引发(raise)错误,而是返回一个带 err 域的 Lua 表(table),用于表示错误

带宽和EVALSHA
EVAL 命令要求你在每次执行脚本的时候都发送一次脚本主体(script body)。Redis 有一个内部的缓存机制,因此它不会每次都重新编译脚本,不过在很多场合,付出无谓的带宽来传送脚本主体并不是最佳选择。
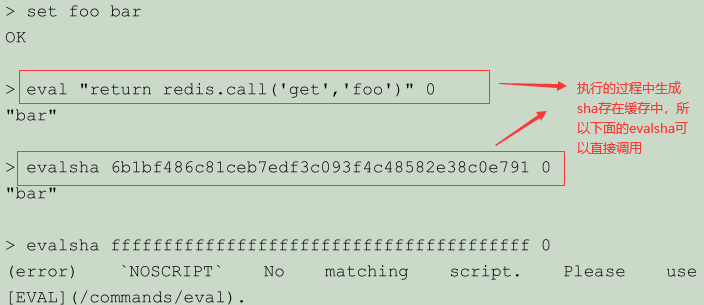
为了减少带宽的消耗, Redis 实现了 EVALSHA 命令,它的作用和 EVAL 一样,都用于对脚本求值,但它接受的第一个参数不是脚本,而是脚本的 SHA1 校验和(sum)。
客户端库的底层实现可以一直乐观地使用 EVALSHA 来代替 EVAL ,并期望着要使用的脚本已经保存在服务器上了,只有当 NOSCRIPT 错误发生时,才使用 EVAL 命令重新发送脚本,这样就可以最大限度地节省带宽。
这也说明了执行 EVAL 命令时,使用正确的格式来传递键名参数和附加参数的重要性:因为如果将参数硬写在脚本中,那么每次当参数改变的时候,都要重新发送脚本,即使脚本的主体并没有改变,相反,通过使用正确的格式来传递键名参数和附加参数,就可以在脚本主体不变的情况下,直接使用 EVALSHA 命令对脚本进行复用,免去了无谓的带宽消耗。
脚本缓存
- Redis 保证所有被运行过的脚本都会被永久保存在脚本缓存当中,这意味着,当 EVAL命令在一个 Redis 实例上成功执行某个脚本之后,随后针对这个脚本的所有 EVALSHA 命令都会成功执行。
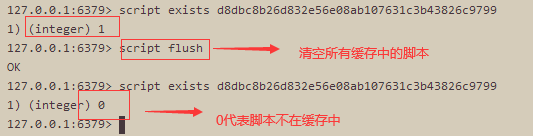
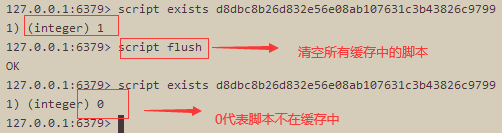
- 刷新脚本缓存的唯一办法是显式地调用 SCRIPT FLUSH 命令,这个命令会清空运行过的所有脚本的缓存。通常只有在云计算环境中,Redis 实例被改作其他客户或者别的应用程序的实例时,才会执行这个命令。
- 缓存可以长时间储存而不产生内存问题的原因是,它们的体积非常小,而且数量也非常少,即使脚本在概念上类似于实现一个新命令,即使在一个大规模的程序里有成百上千的脚本,即使这些脚本会经常修改,即便如此,储存这些脚本的内存仍然是微不足道的。
- 事实上,用户会发现 Redis 不移除缓存中的脚本实际上是一个好主意。比如说,对于一个和 Redis 保持持久化链接(persistent connection)的程序来说,它可以确信,执行过一次的脚本会一直保留在内存当中,因此它可以在流水线中使用 EVALSHA 命令而不必担心因为找不到所需的脚本而产生错误(稍候我们会看到在流水线中执行脚本的相关问题)。
全局变量保护
为了防止不必要的数据泄漏进 Lua 环境, Redis 脚本不允许创建全局变量。如果一个脚本需要在多次执行之间维持某种状态,它应该使用 Redis key 来进行状态保存。
实现全局变量保护并不难,不过有时候还是会不小心而为之。一旦用户在脚本中混入了Lua 全局状态,那么 AOF 持久化和复制(replication)都会无法保证,所以,请不要使用全局变量。避免引入全局变量的一个诀窍是:将脚本中用到的所有变量都使用 local 关键字定义为局部变量。

脚本指令
eval
#格式
eval script numkeys key [key ...] arg [arg ...]
#参数说明
#script:是一段 Lua 5.1 脚本程序,它会被运行在 Redis 服务器上下文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
#numkeys:用于指定键名参数的个数。
#key:键名参数,表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问( KEYS[1] ,KEYS[2] ,以此类推)。
#arg:全局变量,可以在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)

在lua脚本中可以通过两个不同的函数调用redis命令,分别是:redis.call() 和 redis.pcall()
#写法1
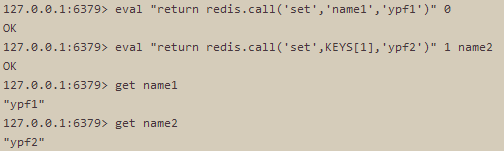
eval "return redis.call('set','name1','ypf1')" 0
#写法2 (推荐!!)
eval "return redis.call('set',KEYS[1],'ypf2')" 1 name2
剖析:
写法1违反了EVAL 命令的语义,因为脚本里使用的所有键都应该由 KEYS 数组来传递。
要求使用正确的形式来传递键(key)是有原因的,因为不仅仅是 EVAL 这个命令,所有的 Redis 命令,在执行之前都会被分析,以此来确定命令会对哪些键进行操作。因此,对于 EVAL 命令来说,必须使用正确的形式来传递键,才能确保分析工作正确地执行。除此之外,使用正确的形式来传递键还有很多其他好处,它的一个特别重要的用途就是确保 Redis 集群可以将你的请求发送到正确的集群节点。(对 Redis 集群的工作还在进行当中,但是脚本功能被设计成可以与集群功能保持兼容。)不过,这条规矩并不是强制性的,从而使得用户有机会滥用(abuse) Redis 单实例配置(single instance configuration),代价是这样写出的脚本不能被 Redis 集群所兼容。
evalsha
根据给定的 sha1 校验码,对缓存在服务器中的脚本进行求值
#格式
evalsha sha1 numkeys key [key ...] arg [arg ...]
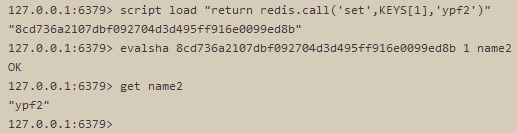
script load
将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。
EVAL 命令也会将脚本添加到脚本缓存中,但是它会立即对输入的脚本进行求值。如果给定的脚本已经在缓存里面了,那么不做动作。在脚本被加入到缓存之script exists后,通过 EVALSHA 命令,可以使用脚本的 SHA1 校验和来调用这个脚本。脚本可以在缓存中保留无限长的时间,直到执行 SCRIPT FLUSH 为止。

script exists
判断脚本是否已经添加到缓存中去了,1代表已经添加,0代表没有添加。
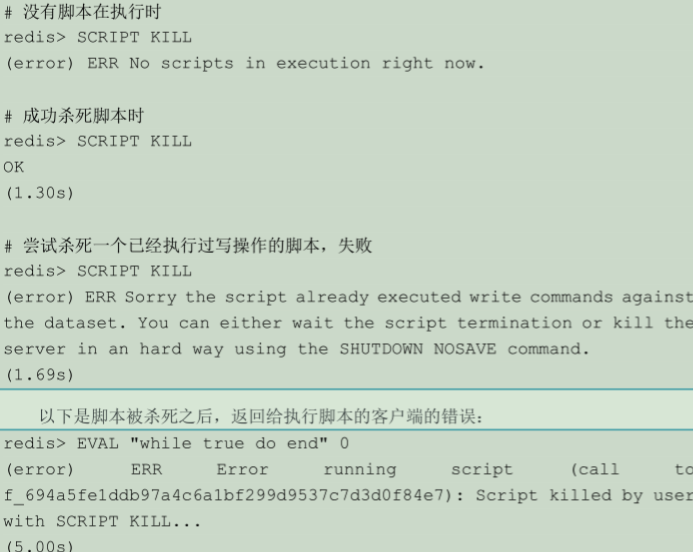
script kill
杀死当前正在运行的 Lua 脚本,当且仅当这个脚本没有执行过任何写操作时,这个命令才生效。
这个命令主要用于终止运行时间过长的脚本,比如一个因为 BUG 而发生无限 loop 的脚本,诸如此类。SCRIPT KILL 执行之后,当前正在运行的脚本会被杀死,执行这个脚本的客户端会从EVAL 命令的阻塞当中退出,并收到一个错误作为返回值。
另一方面,假如当前正在运行的脚本已经执行过写操作,那么即使执行 SCRIPT KILL ,也无法将它杀死,因为这是违反 Lua 脚本的原子性执行原则的。在这种情况下,唯一可行的办法是使用 SHUTDOWN NOSAVE 命令,通过停止整个 Redis 进程来停止脚本的运行,并防止不完整(half-written)的信息被写入数据库中。
script flush
清除所有 Lua 脚本缓存
Lua语法
介绍
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。常见的数据类型如下:

redis和lua之间的数据类型存在一一对应关系:


好处
- 减少网络开销:本来多次网络请求的操作,可以用一个请求完成,原先多次次请求的逻辑都放在redis服务器上完成,使用脚本,减少了网络往返时延。
- 原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。
- 复用:客户端发送的脚本会永久存储在Redis中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑。
- 替代redis的事务功能:redis自带的事务功能很鸡肋,报错不支持回滚,而redis的lua脚本几乎实现了常规的事务功能,支持报错回滚操作,官方推荐如果要使用redis的事务功能可以用redis lua替代。
官网原话
A Redis script is transactional by definition, so everything you can do with a Redis transaction, you can also do with a script, and usually the script will be both simpler and faster.
注:lua整合一系列redis操作, 是为了保证原子性, 即redis在处理这个lua脚本期间不能执行其它操作, 但是lua脚本自身假设中间某条指令出错,并不会回滚的,会继续往下执行或者报错了。
基本语法
- 基本结构,类似于js,前面声明方法,后面调用方法。
- 获取传过来的参数:ARGV[1]、ARGV[2] 依次类推,获取传过来的Key,用KEYS[1]来获取。
- 调用redis的api,用redis.call( )方法调用。
- int类型转换 tonumber
参考代码
1.设计思路
A.编写Lua脚本,将单品限流、购买商品限制、方法幂等、扩建库存整合在一个lua脚本中,程序通过相关的Api调用即可。
B.启动项目的是加载读取Lua脚本并转换→转换后的结果存到服务器缓存中→业务中调用的时候直接从缓存中读取传给Redis的Api。
2.分析
A. 整合在一个脚本中,程序相当于只链接了一次Redis,提高了性能,解决以上四个业务相互之间可能存在的并发问题
B. 在集群环境中,能替代分布式锁吗?
3.代码分享
lua整合脚本
--[[本脚本主要整合:单品限流、购买的商品数量限制、方法幂等、扣减库存的业务]]
--[[
一. 方法声明
]]--
--1. 单品限流--解决缓存覆盖问题
local function seckillLimit()
--(1).获取相关参数
-- 限制请求数量
local tLimits=tonumber(ARGV[1]);
-- 限制秒数
local tSeconds =tonumber(ARGV[2]);
-- 受限商品key
local limitKey = ARGV[3];
--(2).执行判断业务
local myLimitCount = redis.call('INCR',limitKey);
-- 仅当第一个请求进来设置过期时间
if (myLimitCount ==1)
then
redis.call('expire',limitKey,tSeconds) --设置缓存过期
end; --对应的是if的结束
-- 超过限制数量,返回失败
if (myLimitCount > tLimits)
then
return 0; --失败
end; --对应的是if的结束
end; --对应的是整个代码块的结束
--2. 限制一个用户商品购买数量(这里假设一次购买一件,后续改造)
local function userBuyLimit()
--(1).获取相关参数
local tGoodBuyLimits = tonumber(ARGV[5]);
local userBuyGoodLimitKey = ARGV[6];
--(2).执行判断业务
local myLimitCount = redis.call('INCR',userBuyGoodLimitKey);
if (myLimitCount > tGoodBuyLimits)
then
return 0; --失败
else
redis.call('expire',userBuyGoodLimitKey,600) --10min过期
return 1; --成功
end;
end; --对应的是整个代码块的结束
--3. 方法幂等(防止网络延迟多次下单)
local function recordOrderSn()
--(1).获取相关参数
local requestId = ARGV[7]; --请求ID
--(2).执行判断业务
local requestIdNum = redis.call('INCR',requestId);
--表示第一次请求
if (requestIdNum==1)
then
redis.call('expire',requestId,600) --10min过期
return 1; --成功
end;
--第二次及第二次以后的请求
if (requestIdNum>1)
then
return 0; --失败
end;
end; --对应的是整个代码块的结束
--4、扣减库存
local function subtractSeckillStock()
--(1) 获取相关参数
--local key =KEYS[1]; --传过来的是ypf12345没有什么用处
--local arg1 = tonumber(ARGV[1]);--购买的商品数量
-- (2).扣减库存
-- local lastNum = redis.call('DECR',"sCount");
local lastNum = redis.call('DECRBY',ARGV[8],tonumber(ARGV[4])); --string类型的自减
-- (3).判断库存是否完成
if lastNum < 0
then
return 0; --失败
else
return 1; --成功
end
end
--[[
二. 方法调用 返回值1代表成功,返回:0,2,3,4 代表不同类型的失败
]]--
--1. 单品限流调用
local status1 = seckillLimit();
if status1 == 0 then
return 2; --失败
end
--2. 限制购买数量
local status2 = userBuyLimit();
if status2 == 0 then
return 3; --失败
end
--3. 方法幂等
local status3 = recordOrderSn();
if status3 == 0 then
return 4; --失败
end
--4.扣减秒杀库存
local status4 = subtractSeckillStock();
if status4 == 0 then
return 0; --失败
end
return 1; --成功
lua回滚脚本
--[[本脚本主要整合:单品限流、购买的商品数量限制、方法幂等、扣减库存的业务的回滚操作]]
--[[
一. 方法声明
]]--
--1.单品限流恢复
local function RecoverSeckillLimit()
local limitKey = ARGV[1];-- 受限商品key
redis.call('INCR',limitKey);
end;
--2.恢复用户购买数量
local function RecoverUserBuyNum()
local userBuyGoodLimitKey = ARGV[2];
local goodNum = tonumber(ARGV[5]); --商品数量
redis.call("DECRBY",userBuyGoodLimitKey,goodNum);
end
--3.删除方法幂等存储的记录
local function DelRequestId()
local userRequestId = ARGV[3]; --请求ID
redis.call('DEL',userRequestId);
end;
--4. 恢复订单原库存
local function RecoverOrderStock()
local stockKey = ARGV[4]; --库存中的key
local goodNum = tonumber(ARGV[5]); --商品数量
redis.call("INCRBY",stockKey,goodNum);
end;
详细语法参考菜鸟教程:https://www.runoob.com/lua/lua-tutorial.html