RAG概述
大约 2 分钟
什么是RAG
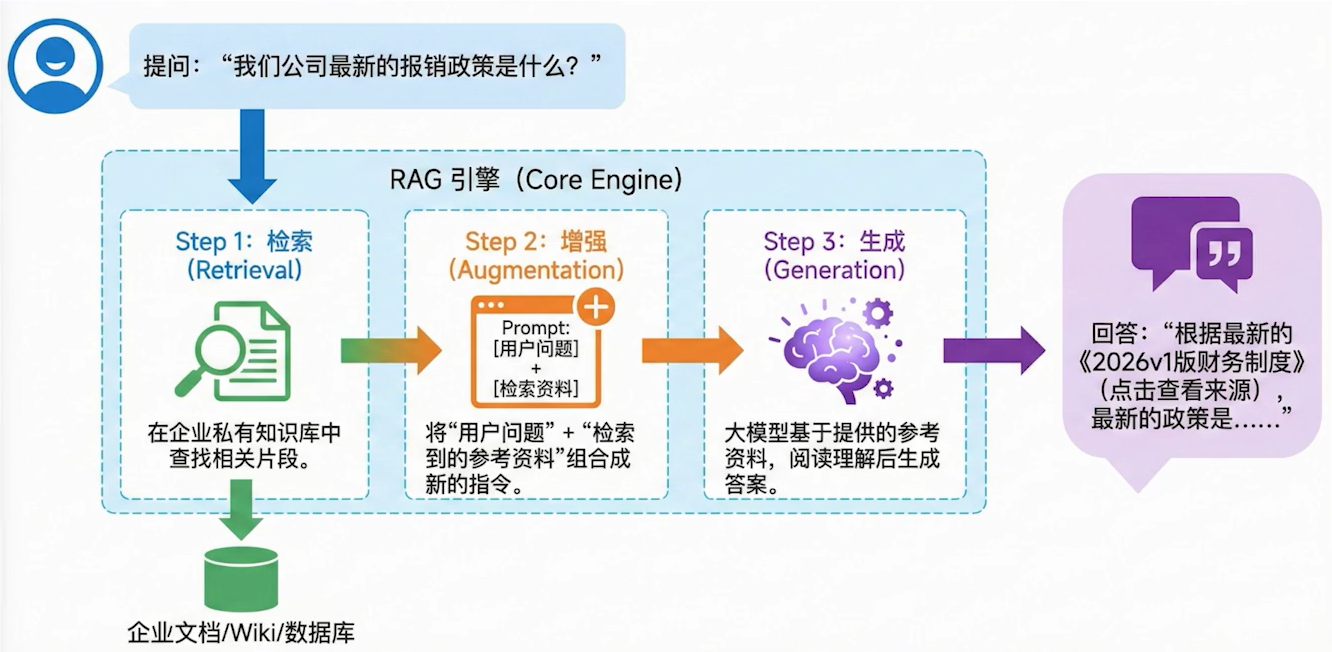
RAG(retrieval-augmented generation)直译为检索增强生成,简单来说就是增强大模型的能力,让大模型可以检索用户提供的文本资料,而不需要每次都将这些文本资料通过token传递给大模型。
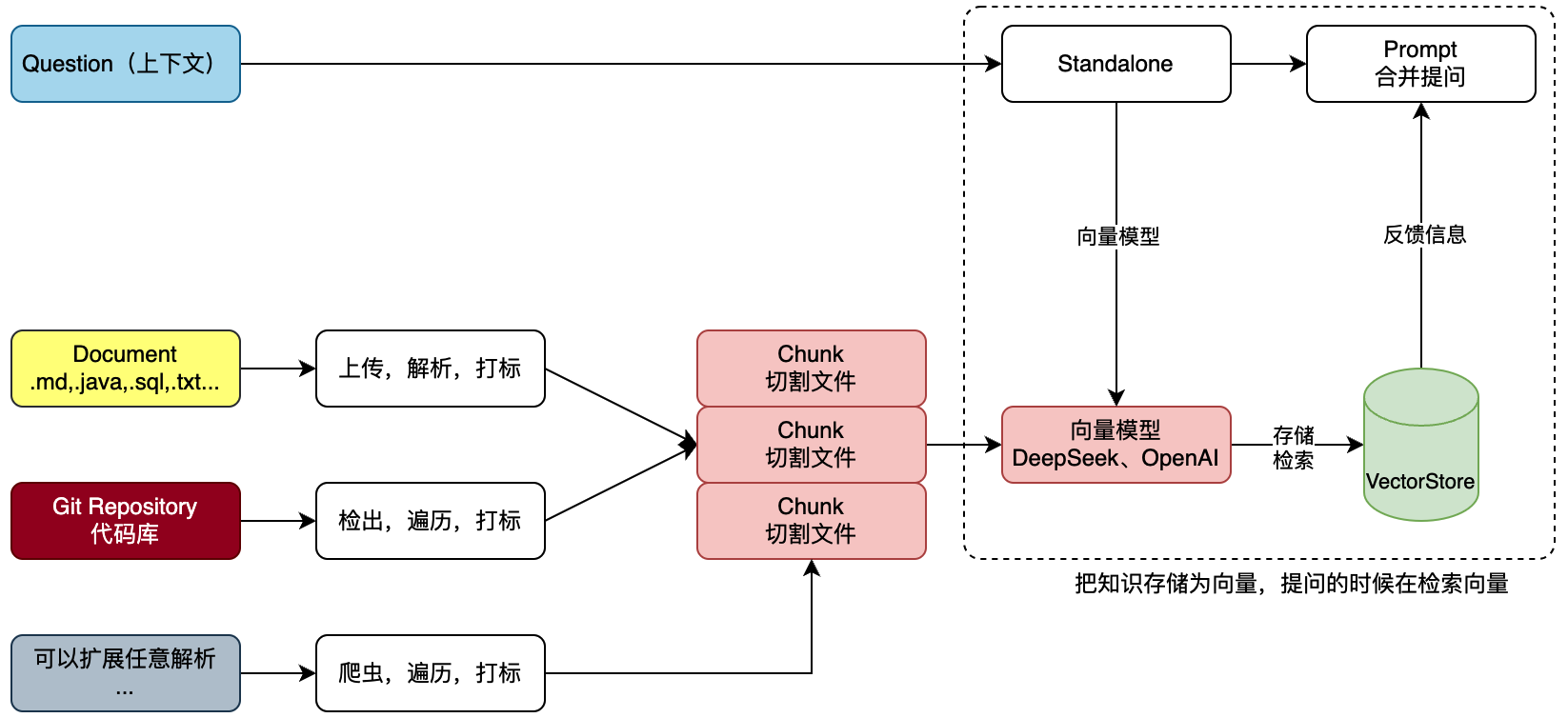
主要使用的计算是嵌入大模型,将用户上传的文本资料进行文件切割、打标最后转为向量数据存储在向量数据库,进行提问的时候去向量数据库进行检索,这样问的信息能够更加正确,并且可以让大模型读取到公司内部的资料。
为什么需要RAG
- 知识边界
- 时效性限制:训练数据截止于过去,无法回答今天的问题。
- 私密性限制:模型只学习过公网数据,不懂行业内的私域数据。
- 信任危机
- 幻觉问题:一本正经的胡说八道,无法自证。
- 不可追溯:内容是黑盒推理,无法提供信息的具体出处。
- 更新成本
- 再训练成本高昂:为了更新一条知识去重新训练/微调模型,成本与收益不成正比。
向量
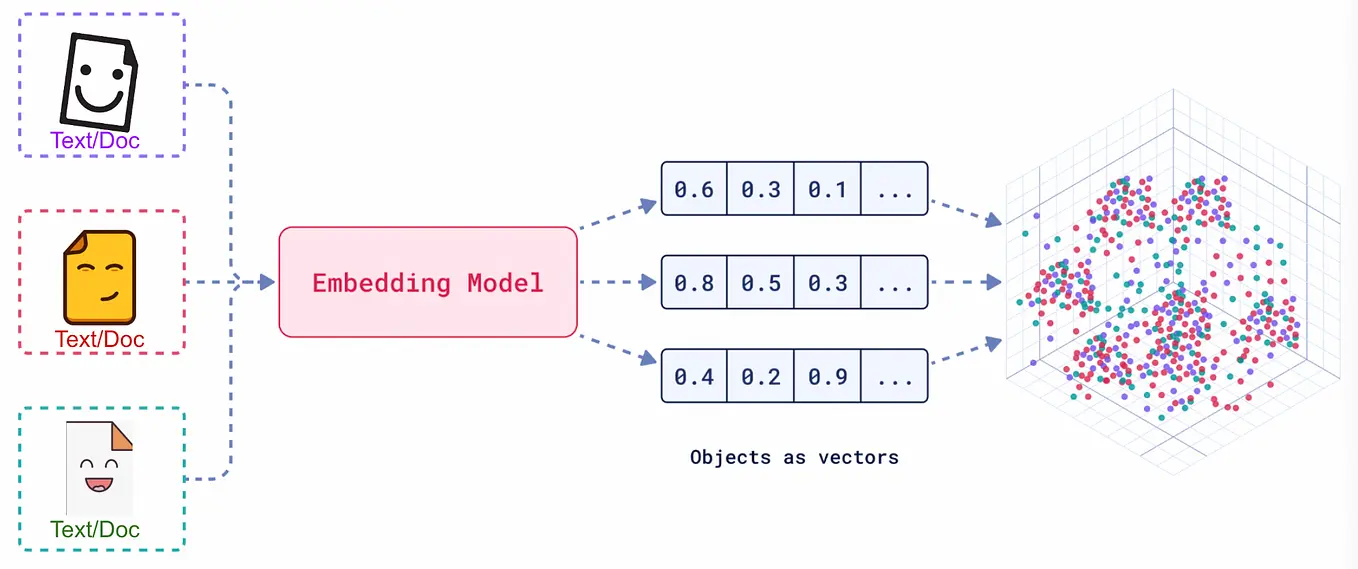
向量嵌入(Embedding)是一种将真实世界中复杂、高维的数据对象(如文本、图像、音频、视频等)转换为数学上易于处理的、低维、稠密的连续数值向量的技术。
想象一下,我们将每一个词、每一段话、每一张图片都放在一个巨大的多维空间里,并给它一个独一无二的坐标。这个坐标就是一个向量,它“嵌入”了原始数据的所有关键信息。这个过程,就是 Embedding。
- 数据对象:任何信息,如文本“你好世界”,或一张猫的图片。
- Embedding 模型:一个深度学习模型,负责接收数据对象并进行转换。
- 输出向量:一个固定长度的一维数组,例如
[0.16, 0.29, -0.88, ...]。这个向量的维度(长度)通常在几百到几千之间。
RAG工作流程
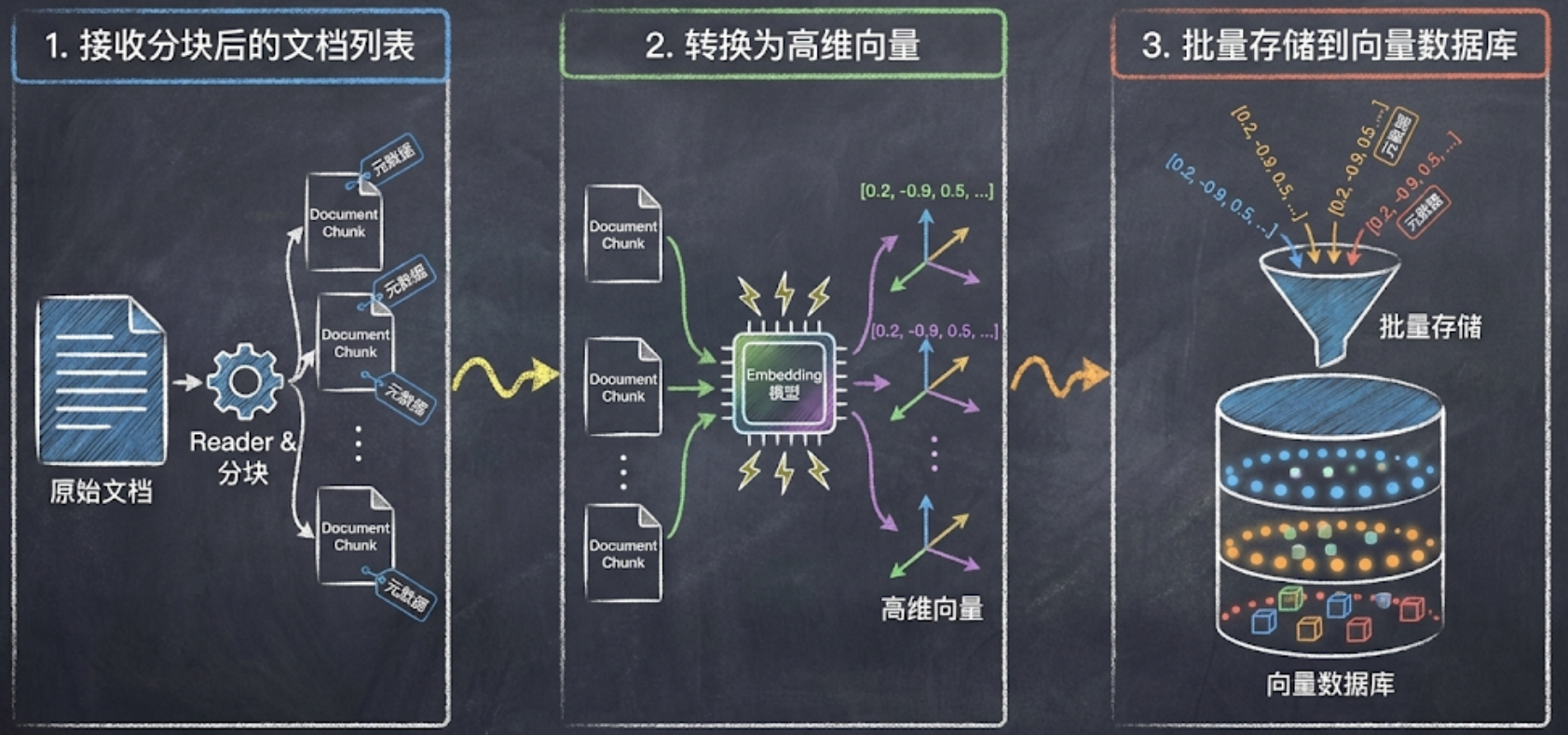
Indexing
- 接收由 Reader 读取并分块后的Document列表。
- 调用 Embedding 模型(如text-embedding-v3)将文档块转换为高维向量。
- 将向量及文档元数据批量存储到向量数据库。
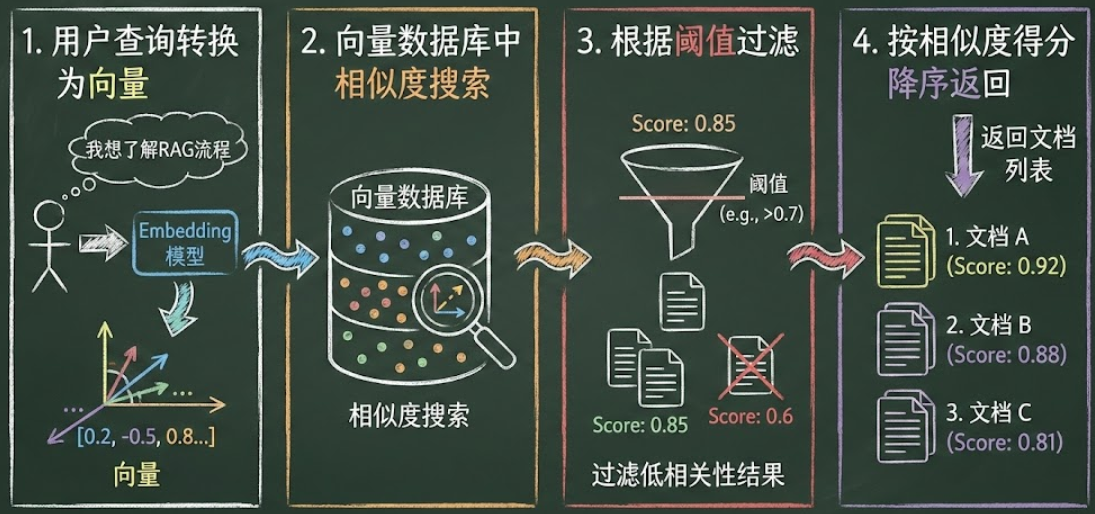
Retrieval
- 使用 Embedding 模型将用户查询转换为向量。
- 在向量数据库中执行相似度搜索。
- 根据阈值过滤低相关性结果。
- 按相似度得分降序返回文档列表。