
主要结构
主要结构
Lucene
Lucene 索引文件结构主要如下
| Name | Extension | Description |
|---|---|---|
| Term Index | .tip | 词典索引(需要加载进内存) |
| Term dictionary | .tim | 倒排表数据 |
| Frequencies | .doc | 包含 Trem 和频率的文档列表(倒排表) Term Frequency (TF):一个词项在文档中出现的次数。 Document Frequency (DF):一个词项在整个索引中出现的文档数量。 |
| Fields | .fnm | Field 数据元信息 |
| Field Index | .fdx | 文档位置索引(虚加载进内存) |
| Field Data | .fdt | 文档值 |
| Per-Document Values | .dvd .dvm | .dvm 为 DocValues 元信息 .dvd 为 DocValue 值(默认情况下 Elasticsearch 开启该功能用于快速排序、聚合操作等) |
Inverted Index(倒排索引)
倒排索引是 Lucene 的核心,用于快速定位文档中的关键词。其结构包括:
- Term Dictionary(词项字典):所有文档中出现过的唯一词项(Term)的集合,按字典序排序。
- Postings List(倒排列表):每个词项对应的文档列表(DocID 列表),包含以下信息:
- DocID:文档的唯一标识。
- Term Frequency(TF):词项在文档中出现的次数。
- Positions:词项在文档中的位置(用于短语查询)。
- Payloads(可选):附加的元数据(如权重)。
一段文本进行分词后存储在 Term dictionary 按照顺序排列(可以二分查找),Postings list 存储对应的文档ID,由于 Term dictionary 数据量大所以不适合存储内存中。
| Term dictionary | Posting list |
|---|---|
| follow | 1 |
| forward | 2 |
| link | 0、1、2 |
| like | 0 |
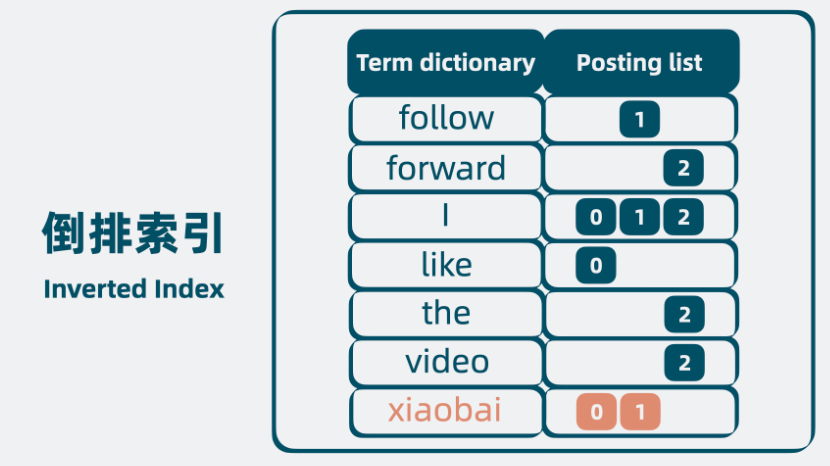
Term Index
lucene 中出现了另外一个结构 Term Index 这是一个前缀树,通过提取 Term dictionary 的前缀减少存储的数据,记录 Term dictionary 中的偏移量, Term Index 该结构存在内存中。查询的时候先通过 Term Index 定位到大概的位置,在去 Term dictionary 中遍历,可以提升查找的效率
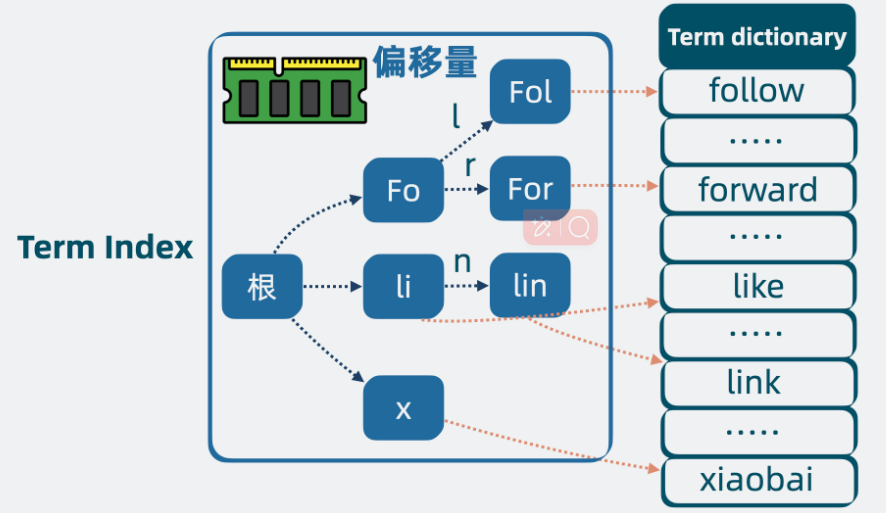
Stored Fields
存储原始文档的字段值,用于搜索结果中直接返回原始内容(如
_source)。存储方式:按文档存储(行式存储),适合按 Doc ID 快速读取。
默认行为: 默认情况下,
stored属性为false,这意味着 Elasticsearch 不会单独存储该字段的原始值。但用户仍然可以通过_source字段获取原始值(因为整个文档的原始 JSON 存储在_source中)。显式启用
stored: 如果显式设置"store": true,则 Elasticsearch 会将该字段的原始值(如"192.168.1.1")独立存储在 Lucene 的存储字段中。此时可以通过fieldsAPI(如fields["ip_field"])直接获取该值,无需解析_source。

通过 ID 可以从 Stored Fields 取出文档内容
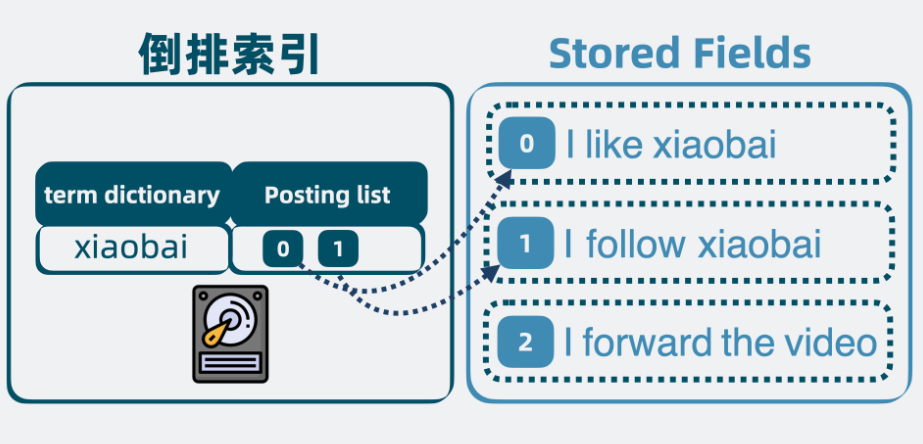
Doc Values
按照某个字段排序的文档,功能类似MySQL的索引
- 列式存储:按字段存储所有文档的值,用于排序、聚合、脚本计算等。
- 文件格式:
.dvd:数据文件(压缩存储)。.dvm:元数据文件(记录数据格式、偏移量)。
- 支持类型:数值(Numeric)、二进制(Binary)、SortedSet 等。
- 默认行为:
doc_values默认启用(true)。对于ip类型字段,Elasticsearch 会将其转换为一种高效的数值形式(如 IPv4 转换为long,IPv6 转换为binary或两个 long),并以列式结构存储在磁盘上。这种优化支持以下操作:- 快速排序(
sort) - 聚合(
terms、ip_range聚合等) - 脚本访问(如 Painless 脚本中的
doc['client_ip'].value)
- 快速排序(
- 禁用 Doc Values: 如果手动设置
"doc_values": false,将无法进行排序、聚合或脚本访问,但可能会略微减少磁盘占用(通常不建议禁用)
Segment
由上面四种结构组成,具备完整搜索功能的最小单元。

随着不断地插入数据会出现多个 segment,Segment一旦生成就不能修改,只能进行合并 Segment Merging(段合并)
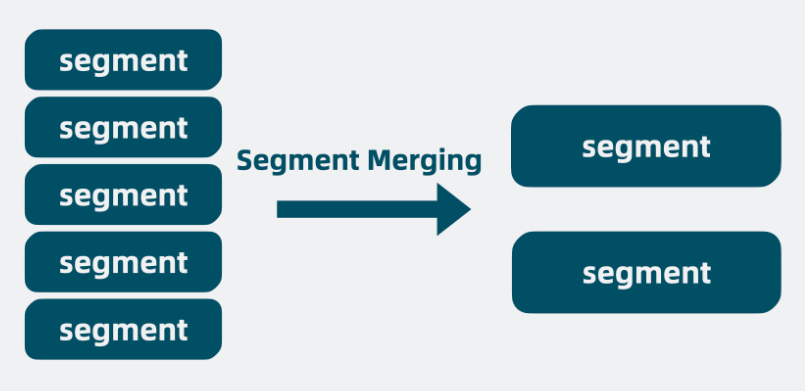
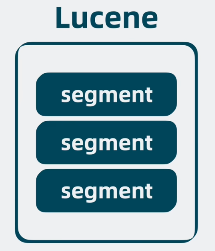
上面提到的多个 segment,就共同构成了一个单机文本检索库,它其实就是非常有名的开源基础搜索库 lucene。
Analysis(分词与分析)
- Tokenizer:将文本拆分为词项(Token),如空格分词、中文分词。
- TokenFilter:对词项进行处理,如转小写、停用词过滤、同义词扩展。
- Analyzer:组合 Tokenizer 和 TokenFilter 的管道,如
StandardAnalyzer
上述结构执行过程
以下是一个插入文档和查询的例子,解释这些结构在背后是如何工作的。
插入文档示例
假设我们在 library 索引中插入一本书的信息:
POST /library/_doc/1
{
"title": "Elasticsearch: The Definitive Guide",
"author": "Clinton Gormley",
"published_year": 2015
}
步骤解析:
- 解析文档:解析 JSON 文档,提取字段
title、author和published_year。 - 分词:对
title字段进行分词,如 "Elasticsearch"、"The"、"Definitive"、"Guide"。 - 更新倒排索引:将词项添加到倒排索引中。
Term Dictionary:记录词项 "Elasticsearch"、"The"、"Definitive"、"Guide"。Term Index:记录词项的位置。Frequencies:记录每个词项在文档中的出现频率。
- 存储字段值:存储字段值用于后续的排序、聚合和返回结果。
- Doc Values:为
published_year字段存储数值用于快速范围查询和排序。
查询所有文档
GET /library/_search
{
"query": {
"match_all": {}
}
}
步骤解析:
- 解析查询:解析
match_all查询,获取所有文档。 - 读取倒排索引:读取所有文档的索引。
- 返回结果:返回存储的字段值。
按标题关键字查询
GET /library/_search
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
步骤解析:
- 解析查询:解析
match查询,提取查询词项 "Elasticsearch"。 - 查找词项:在
Term Dictionary中查找 "Elasticsearch"。 - 读取倒排索引:获取包含 "Elasticsearch" 的文档列表及词频信息。
- 计算相关性:根据词频和其他因素计算文档的相关性得分。
- 返回结果:根据相关性得分排序并返回结果。
通过这些步骤,可以看到 Elasticsearch 如何利用 Term Index、Term Dictionary、Frequencies、Fields、Field Index、Field Data 和 Per-Document Values 来实现高效的文档插入和查询。了解这些底层结构有助于优化索引和查询性能。
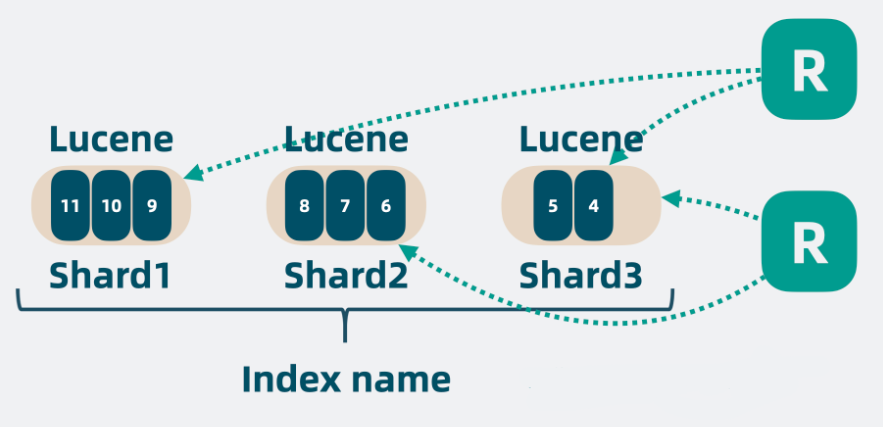
高性能
将数据分为多个 index,每个 index 可以有多个 shard,每个 shard 是一个独立的 lucene 库,这样可以将读写操作分摊到多个分片中去,大大降低了争抢,提升了系统性能。
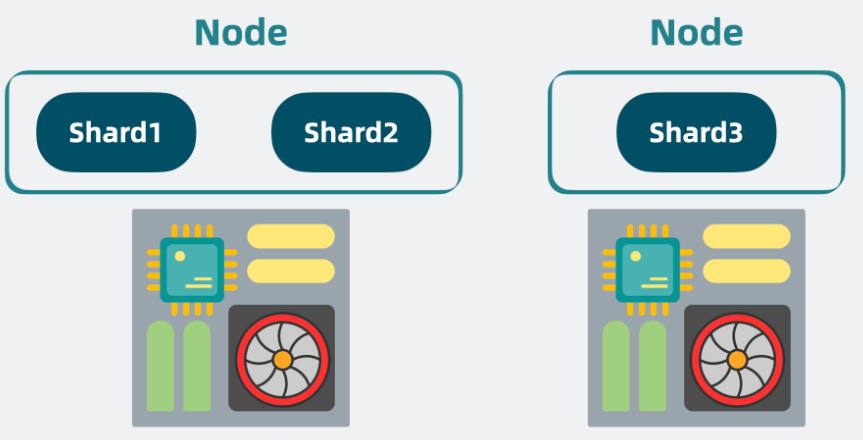
高扩展性
可以通过增加机器来缓解 CPU 过高带来的性能问题,每一个机器就是一个 Node
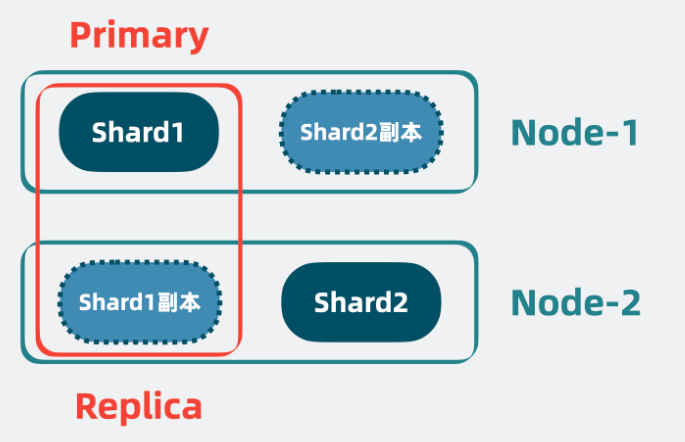
高可用
我们可以给分片多加几个副本。将分片分为 Primary shard 和 Replica shard,也就是主分片和副本分片 。主分片会将数据同步给副本分片,副本分片既可以同时提供读操作,还能在主分片挂了的时候,升级成新的主分片让系统保持正常运行,提高性能的同时,还保证了系统的高可用。这样如果其中一个 Node 挂了,仍然可以对外提供服务。
Node 角色分化
搜索架构需要支持的功能很多,既要负责管理集群,又要存储管理数据,还要处理客户端的搜索请求。如果每个 Node 都支持这几类功能,那当集群有数据压力,需要扩容 Node 时,就会顺带把其他能力也一起扩容,但其实其他能力完全够用,不需要跟着扩容,这就有些浪费了。 因此我们可以将这几类功能拆开,给集群里的 Node 赋予角色身份,不同的角色负责不同的功能。 比如负责管理集群的,叫主节点(Master Node), 负责存储管理数据的,叫数据节点(Data Node), 负责接受客户端搜索查询请求的叫协调节点(Coordinate Node)。 集群规模小的时候,一个 Node 可以同时充当多个角色,随着集群规模变大,可以让一个 Node 一个角色。
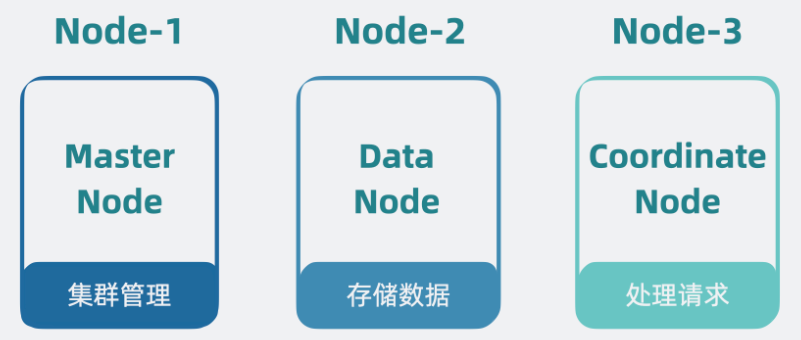
- node.master:false和node.data:true,该node服务器只作为一个数据节点,只用于存储索引数据,使该node服务器功能单一,只用于数据存储和数据查询,降低其资源消耗率。
- node.master:true和node.data:false,该node服务器只作为一个主节点,但不存储任何索引数据,该node服务器将使用自身空闲的资源,来协调各种创建索引请求或者查询请求,并将这些请求合理分发到相关的node服务器上。
- node.master:false和node.data:false,该node服务器即不会被选作主节点,也不会存储任何索引数据,只作为一个协调节点。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个node服务器上查询数据,并将请求分发到多个指定的node服务器,并对各个node服务器返回的结果进行一个汇总处理,最终返回给客户端
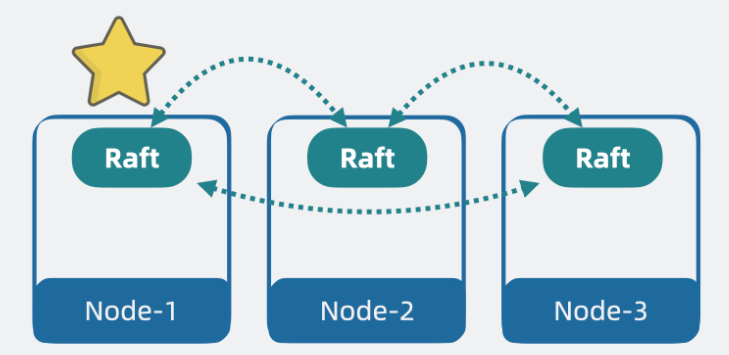
去中心化
上面提到了主节点,那就意味着还有个选主的过程,但现在每个 Node 都是独立的,需要有个机制协调 Node 间的数据。 我们很容易想到,可以像 kafka 那样引入一个中心节点 Zookeeper,但如果不想引入新节点,还有其他更轻量的方案吗? 有,去中心化。 我们可以在 Node 间引入协调模块,用类似一致性算法 Raft 的方式,在节点间互相同步数据,让所有 Node 看到的集群数据状态都是一致的。这样,集群内的 Node 就能参与选主过程,还能了解到集群内某个 Node 是不是挂了等信息。
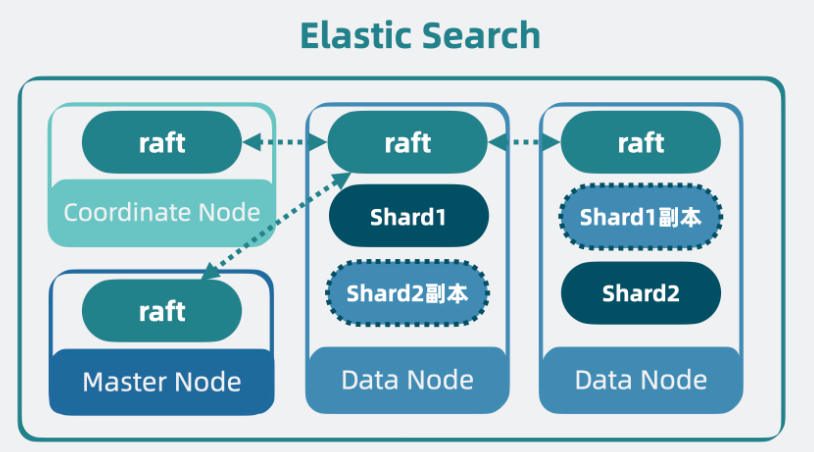
到这里,当初那个简陋的 lucene,就成了一个高性能,高扩展性,高可用,支持持久化的分布式搜索引擎,它就是我们常说的 ElasticSearch,简称 ES。它对外提供 HTTP 接口,任何语言的客户端都可以通过 HTTP 接口接入 es,实现对数据的增删改查。 从架构角度来看,ES 给了一套方案,告诉我们如何让一个单机系统 lucene 变成一个分布式系统。
按这个思路,是不是也可以将 lucene 改成其他单机系统,比如 mysql 数据库,或者专门做向量检索的单机引擎 faiss? 那以后再来个 elastic mysql 或者 elastic faiss 是不是就不那么意外了,大厂内卷晋升或者下一个明星开源大项目的小提示就给到这里了。
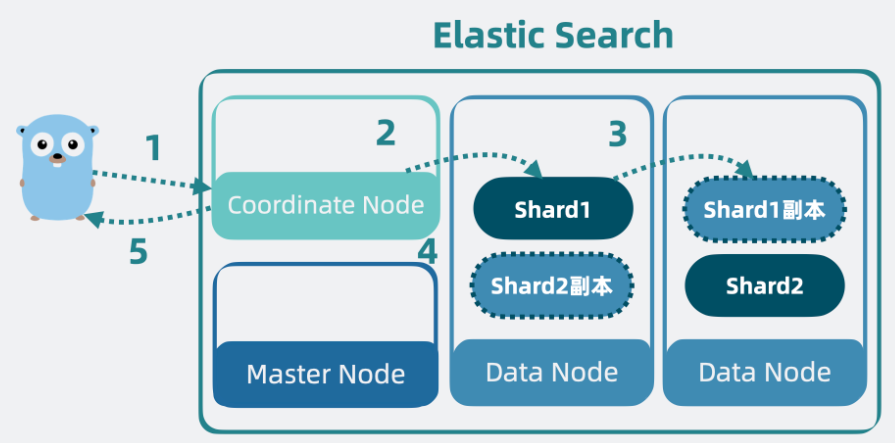
ES 的写入流程
- 当客户端应用发起数据写入请求,请求会先发到集群中协调节点。
- 协调节点根据 hash 路由,判断数据该写入到哪个数据节点里的哪个分片(Shard),找到主分片并写入。分片底层是 lucene,所以最终是将数据写入到 lucene 库里的 segment 内,将数据固化为倒排索引和 Stored Fields 以及 Doc Values 等多种结构。
- 主分片 写入成功后会将数据同步给 副本分片。
- 副本分片 写入完成后,主分片会响应协调节点一个 ACK,意思是写入完成。
- 最后,协调节点响应客户端应用写入完成。
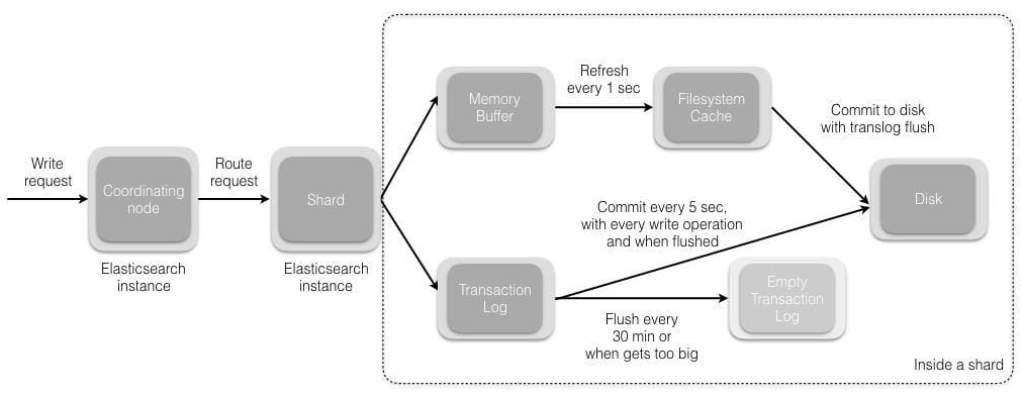
数据刷盘流程
先写入 Memory Buffer 并且同时记录 translog,然后定时(默认是1秒)把 Memory Buffer 的数据写入 Filesystem Cache(这个过程叫做 refresh),接下来会定时触发 flush(默认是30分钟可以调整该参数,或者 translog 变得太大默认 512M)将 Filsystem Cache 的数据写入磁盘中并且清空内存中的缓存删除旧的 translog 创建一个新的。
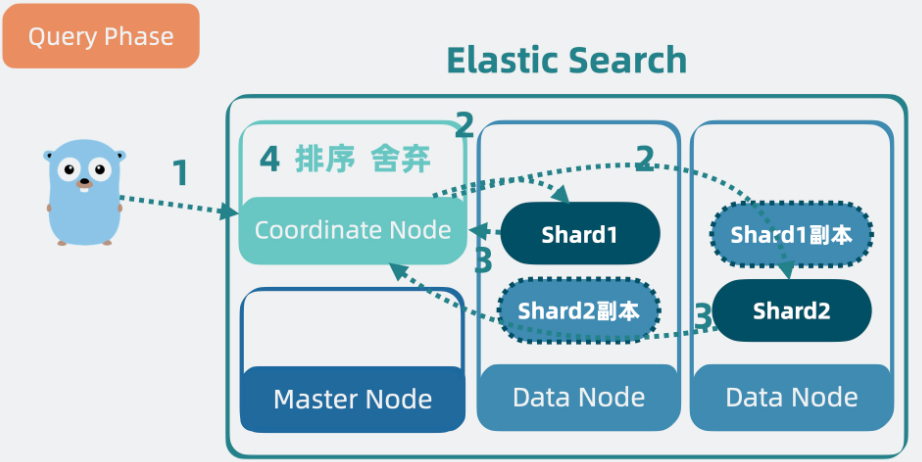
ES 的搜索流程
Elasticsearch 的搜索流程分为 查询阶段(Query Phase) 和 获取阶段(Fetch Phase),核心设计目标是减少网络传输并提升性能。
查询阶段(Query Phase)
目标:快速筛选候选文档 ID 并排序,不返回原始数据。
流程细节
协调节点(Coordinating Node)接收请求
- 客户端请求首先到达协调节点(通常是接收请求的任意节点)。
- 协调节点解析请求,确定目标索引的分片分布(主分片或副本分片)。
分片并行搜索
- 协调节点向所有相关分片(Shard)广播搜索请求。
- 每个分片独立执行以下操作:
- 使用 Lucene 的倒排索引(Inverted Index)快速匹配查询条件。
- 结合
Doc Values(列式存储)进行排序、聚合等操作。 - 根据相关性评分(或自定义排序规则)生成 本地排序结果。
- 仅返回文档 ID + 排序值(如
_score),而非完整文档数据。 - 默认返回 Top N 结果(由
size参数控制),避免传输过多数据。
协调节点合并结果
- 收集所有分片返回的 Top N 结果(可能有
number_of_shards * size条数据)。 - 对所有分片结果进行全局排序,截断最终的 Top N 结果(由
size参数决定)。 - 记录最终入选的文档 ID 及其所属分片。
- 收集所有分片返回的 Top N 结果(可能有
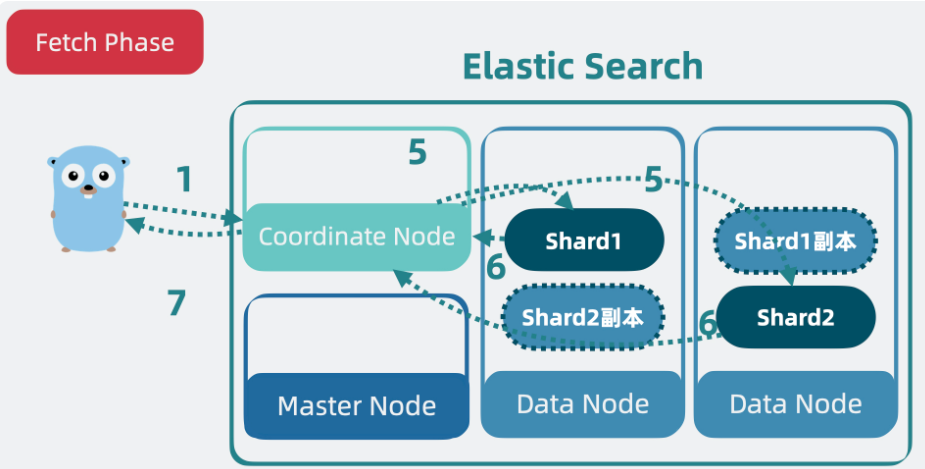
获取阶段(Fetch Phase)
目标:根据查询阶段筛选的文档 ID,获取完整文档内容。
流程细节
协调节点发起 Fetch 请求
- 协调节点向持有最终入选文档的分片发送
Multi-Get请求。 - 请求中携带文档 ID 和分片路由信息。
- 协调节点向持有最终入选文档的分片发送
分片返回完整文档
- 每个分片执行以下操作:
- 通过 Lucene 的
Stored Fields获取文档原始内容。 - 检查文档是否已被删除或更新(通过
_version验证)。 - 返回完整文档数据(包括
_source字段)。
- 通过 Lucene 的
- 每个分片执行以下操作:
协调节点返回最终结果
- 合并所有分片返回的文档数据。
- 若启用了高亮(Highlighting)或字段过滤,在此阶段处理。
- 将最终结果组装后返回给客户端。
实例查询
{
"query": {
"bool": {
"must": [
{ "match": { "title": "elasticsearch" }},
{ "range": { "price": { "gte": 100 }}}
],
"filter": [
{ "term": { "status": "active" }}
]
}
}
}
查询阶段(Query Phase)
1. 协调节点(Coordinating Node)
- 解析查询:将 JSON 查询拆解为:
must子句(影响评分):match(title)+range(price)filter子句(不评分):term(status)
- 路由请求:确定目标索引的分片位置,广播请求到相关分片(主/副本)。
2. 数据分片(Shard)
- Lucene 处理逻辑:
- 倒排索引匹配:
match(title: "elasticsearch"):分词后检索倒排索引,获取匹配文档 ID。term(status: "active"):直接过滤精确匹配的文档。
- Doc Values 过滤:
range(price >= 100):通过列式存储快速筛选数值符合条件的文档。
- 合并结果:
- 计算
must子句的相关性评分(_score)。 - 使用
filter子句进行硬过滤(不参与评分)。
- 计算
- 返回候选集:每个分片返回本地 Top N 的文档 ID + 评分。
- 倒排索引匹配:
3. 协调节点聚合
- 全局排序:合并所有分片结果,按
_score降序排列。 - 截断结果:保留全局 Top N(由
size参数控制)。
获取阶段(Fetch Phase)
1. 协调节点
- 发起 Multi-Get:根据最终入选的文档 ID 列表,向对应分片请求完整数据。
2. 数据分片(Shard)
- 读取存储字段:
- 通过
Stored Fields获取文档原始内容(_source字段)。 - 验证文档有效性(未被删除/更新)。
- 通过
3. 协调节点返回
- 组装结果:合并文档内容,返回最终响应给客户端。
核心组件协作
| 组件 | 关键动作 |
|---|---|
| 协调节点 | 查询解析、路由、结果聚合 |
| 数据分片 | 倒排索引匹配、Doc Values 过滤、评分计算 |
| Lucene | 底层索引检索、文档存储管理 |
| Stored Fields | 存储原始文档内容(用于 Fetch 阶段) |
总结
lucene 是 es 底层的单机文本检索库,它由多个 segment 组成,每个 segment 其实是由倒排索引、Term Index、Stored Fields 和 Doc Values 组成的具备完整搜索功能的最小单元。
将数据分类,存储在 es 内不同的 Index Name 中。
为了防止 Index Name 内数据过多,引入了 Shard 的概念对数据进行分片。提升了性能。
将多个 shard 分布在多个 Node 上,根据需要对 Node 进行扩容,提升扩展性。
将 shard 分为主分片和副本分片,主分片挂了之后由副本分片顶上,提升系统的可用性。
对 Node 进行角色分化,提高系统的性能和资源利用率,同时简化扩展和维护。
es 和 kafka 的架构非常像,可以类比学习。
- shard = hash(routing) % number_of_primary_shards,计算文档在哪个分片,routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID
ES 一旦创建好索引后,就无法调整分片的设置,而在 ES 中,一个分片实际上对应一个 lucene 索引,而 lucene 索引的读写会占用很多的系统资源,因此,分片数不能设置过大;所以,在创建索引时,合理配置分片数是非常重要的。一般来说,我们遵循一些原则:
控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32 G,参考上面的 JVM 内存设置原则),因此,如果索引的总容量在 500 G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以,一般都设置分片数不超过节点数的 3 倍。