
Redis介绍
REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。
概述
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
- Redis是一个
开源的key-value存储系统 - 和Memcached类似,它支持存储的value类型相对更多,包括
string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型) - 这些数据类型都支持push/pop、 add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是
原子性的 - 在此基础上, Redis支持各种不同方式的
排序 - 与memcached一样,为了保证效率,数据都是
缓存在内存中 - 区别的是Redis会
周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件 - 并且在此基础上实现了
master-slave(主从)同步
Redis
单线程+多路IO复用
简单理解就是:一个服务端进程可以同时处理多个套接字描述符。 多路:多个客户端连接(连接就是套接字描述符) 复用:使用单进程就能够实现同时处理多个客户端的连接 以上是通过增加进程和线程的数量来并发处理多个套接字,免不了上下文切换的开销,而 IO 多路复用只需要一个进程就能够处理多个套接字,从而解决了上下文切换的问题。 其发展可以分 select->poll→epoll 三个阶段来描述。
五大数据类型
- 字符串(String)
- 列表(List)
- 集合(Set)
- 哈希(Hash)
- 有序集合(Zset)
命令操作
# redis自带的客户端
redis-cli
如果有给redis设置密码,需要先验证一下才能操作redis
127.0.0.1:6379> auth root
键key
keys * # 查看数据库中所有的key
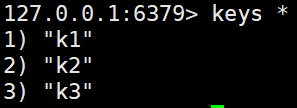
exists (key) # 查看key是否存在,返回值为key的数量
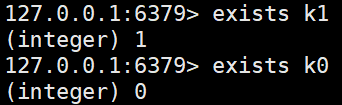
type (key) # 查看key是什么类型

del (key) # 删除key,返回删除个数

unlink (key) # 根据value选择非阻塞删除,先通知删除该key,后续在删除内存中的key,异步执行
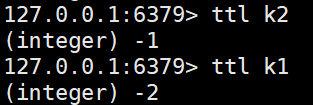
expire (key) (time) # 设置key的过期时间,单位秒

ttl (key) # 查看key过期时间,-1表示永不过期,-2表示已经过期
库
select (库序号) # 切换库,redis有16个库,默认是0
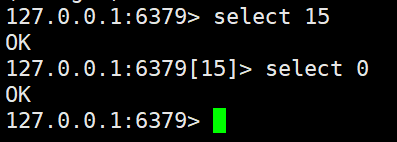
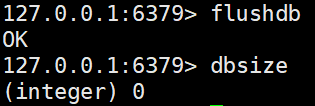
dbsize #查看当前数据库key的数量,返回个数

flushdb #清除当前库
flushall #清除全部库
String(字符串)
String类型是(二进制安全的),可以包含任何数据
Srting类型是Redis最基本的数据类型,一个Redis中字符串的value最多可以是512M
set <key> <value> #设置一个key,value

get <key> #根据key获取value

append <key> <value> #在对应key的value后面追加数据,返回总长度
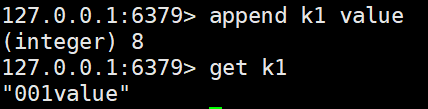
strlen <key> #获取值的长度
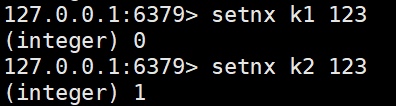
setnx <key> <value> #设置值,当键存在时不进行设置,键不存在才进行设置
incr <key> #将key中存储的值+1,返回增加后的值,只能对数字值进行操作,如果为空,新增值为1

decr <key> #将key中存储的值-1,返回减少后的值,只能对数字值进行操作,如果为空,新增值为-1

incrby/decrby <key> <步长> #将key中的值进行增减,长度为步长

增减操作都是原子性操作:Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。
Redis的操作之所以是原子性的,是因为Redis是单线程的。
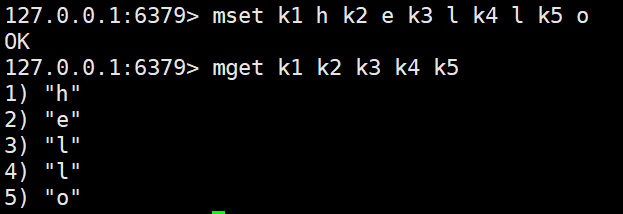
mset <key1> <value1> <key2> <value2> ... #同时对多对k-v进行赋值
mget <key1> <key2> <key3> ... #同时获取多个value
msetnx <key1> <value1> <key2> <value2> ... #同时设置多对值,当值存在时不进行设置,值不存在才进行设置
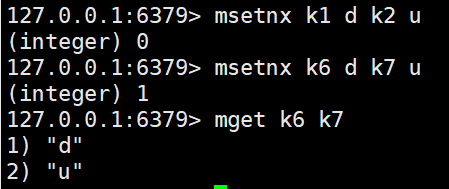
msetnx同时设置多对值时,原子性操作,要么都成功要么都不成功
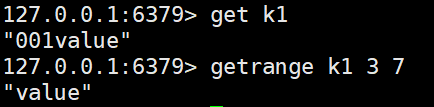
#获取值的范围,类似Java中的substring,前后都为闭区间
getrange <key> <起始位置> <结束位置>
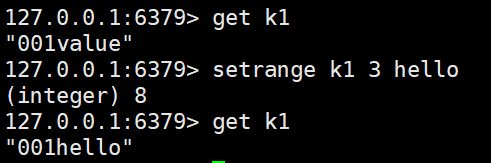
#根据起始位置,将key中的值覆盖为value
setrange <key> <起始位置> <value>
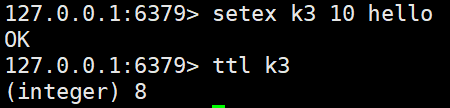
setex <key> <过期时间> <value> #设置k-v的同时设置过期时间,单位s
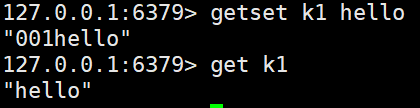
getset <key> <value> #设置新值的同时,获取旧值
String的底层结构为简单的动态字符串,内部结构类似与Java的ArrayList,才用预分配冗余空间的方式,来减少内存的频繁操作

内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间,需要注意的是字符串最大长度为512M
Hash(哈希)
hash是一个键值对集合
hash是一个string类型的field和value的映射表,hash特别适用于存储对象,类似Java的Map<string, object>
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下两种存储方式:

- 将对象系列化,存储序列化过后的对象,每次修改对象需要先反序列化,修改完数据后在序列化回去
- 普通键值对,键是用户id+属性标签,值是属性值,id数据冗余
第三种方式:
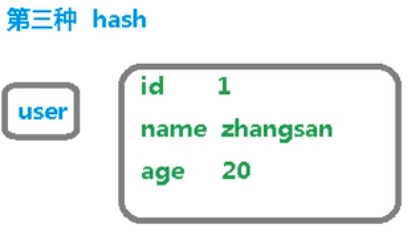
user为key,属性标签跟属性值是value,存储方便,值的操作方便
命令
hset <key> <filed> <value> [filed value..] #<key>是hash的键,<filed>是value的键,<value>是值,可以批量设置,如果hash的key不存在则创建新的hash,如果key存在则创建失败

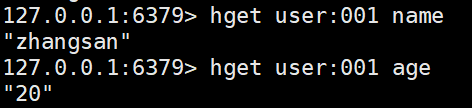
hget <key> <filed> #根据filed获取value
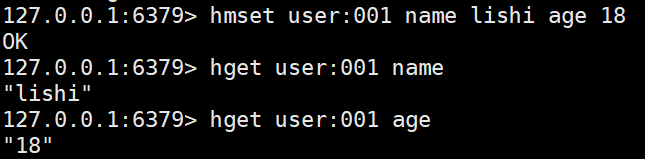
hmset <key> <filed> <value> [filed value ..] #可以批量设置hash,如果key存在,filed相同则覆盖对应的value,否则创建一个新的hash
hmget <key> <filed> [filed ..] #批量获取value,如果filed不存在返回nil,存在返回对应的value
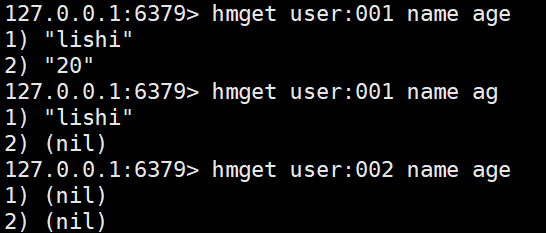
hexists <key> <filed> #判断对应的key是否存在filed
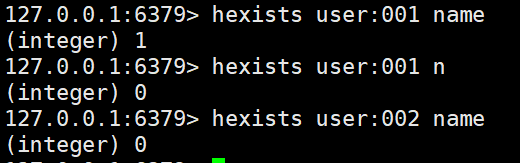
hkeys <key> #查询对应的key的所有filed

hvals <key> #查询对应key的所有value

hincrby <key> <field> <increment> #为hash的key中的field的值增加或减少increment

hsetnx <key> <field> <value> #为对应key添加filed和value,只有filed不存在时才会成功

Hash类型对应的数据结构有两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziphash,否则使用hashtable
List(列表)
单键多值
redis列表是简单的字符串列表,按照插入顺序排序,可以插入一个元素到列表的头部(左边)或者尾部(右边)
列表类型内部使用双向链表实现的,所以向列表两端添加元素的时间复杂度为O(1),获取越接近两端的元素速度越快。但是使用链表的代价是通过索引访问元素比较慢。

命令
| 命令 | 用法 | 描述 |
|---|---|---|
| lpush | lpush key value [value ...] | (1)将一个或多个值插入到列表key的表头; (2)如果有多个value值,则从左到右的顺序依次插入表头; (3)如果key不存在,则会创建一个空列表,然后执行lpush操作;如果key存在,但不是列表类型,则返回错误。 |
| lpushx | lpushx key value | (1)将value值插入到列表key的表头,当且仅当key存在且是一个列表; (2)如果key不存在时,lpushx命令什么都不会做。 |
| lpop | lpop key | (1)移除并返回列表key的头元素。 |
| lrange | lrange key start stop | (1)返回列表key中指定区间内的元素; (2)start大于列表最大下标是,返回空列表; (3)可使用负数下标,-1表示列表最后一个元素,以此类推。 |
| lrem | lrem key count value | (1)count>0表示从头到尾搜索,移除与value相等的元素,数量为count; (2)count<0表示从尾到头搜索,移除与value相等的元素,数量为count; (3)count=0表示移除列表中所有与value相等的元素。 |
| lset | lset key index value | (1)将列表key下标为index的元素值设置为value; (2)当index参数超出范围,或对一个空列表进行lset操作时,返回错误。 |
| lindex | lindex key index | (1)返回列表key中下标为index的元素。 |
| linsert | linsert key BEFORE|AFTER pivot value | (1)将值value插入列表key中,位于pivot前面或者后面; (2)当pivot不存在列表key中,或者key不存在时,不执行任何操作。 |
| llen | len key | (1)返回列表key的长度,当key不存在时,返回0。 |
| rpop | rpop key | (1)移除并返回列表key的尾元素。 |
| rpoplpush | rpoplpush source destination | (1)将列表source中最后一个元素弹出并返回给客户端,并且将该元素插入到列表destincation的头部。 |
| rpush | rpush key value [value ...] | (1)将一个或多个值插入到列表key的尾部。 |
| rpushx | rpushx key value | (1)将value值插入到列表key的表尾,当且仅当key存在且是一个列表; (2)如果key不存在时,lpushx命令什么都不会做。 |
总结:
- 它是一个字符串链表,left 和 right 都可以插入、添加
- 如果键不存在,创建新的链表
- 如果键已存在,新增内容
- 如果值全移除,对应的键也就消失了
- 链表的操作无论是头和尾效率都极高,但假如是对中间元素进行操作,效率就很惨淡了
Set(集合)
Redis中的set类型是string类型的无序集合。集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型在Redis内部是使用值为空的散列表实现的,所以这些操作的时间复杂度都是O(1)。最方便的是多个集合类型键之间还可以进行并集、交集和差集运算。
命令
| 命令 | 用法 | 描述 |
|---|---|---|
| sadd | sadd key member [member ...] | (1)将一个或多个member元素加入key中,已存在在集合中的member将被忽略; (2)如果key不存在,则创建一个只包含member元素的集合; (3)当key不是集合类型时,将返回一个错误。 |
| scard | scard key | (1)返回key对应的集合中的元素数量。 |
| sdiff | sdiff key [key ...] | (1)返回所有key对应的集合的差集。 |
| sdiffstore | sdiffstore destionation key [key ...] | (1)返回所有key对应的集合的差集,并把该差集赋值给destionation; (2)如果destionation已经存在,则直接覆盖。 |
| sinter | sinter key [key ...] | (1)返回所有key对应的集合的交集; (2)不存在的key被视为空集。 |
| sinterstore | sinter destionation key [key ...] | (1)返回所有key对应的集合的交集,并把该交集赋值给destionation; (2)如果destionation已经存在,则直接覆盖。 |
| sismember | sismember key member | (1)判断member元素是否是key的成员,0表示不是,1表示是。 |
| smembers | smember key | (1)返回集合key中的所有成员; (2)不存在的key被视为空集。 |
| srem | srem key member [member ...] | (1)移除集合key中的一个或多个member元素,不存在的member将被忽略。 |
| sunion | sunion key [key ...] | (1)返回所有key对应的集合的并集; (2)不存在的key被视为空集。 |
| sunionstore | sunionstore destionation key [key ...] | (1)返回所有key对应的集合的并集,并把该并集赋值给destionation; (2)如果destionation已经存在,则直接覆盖。 |
Zset(sorted set有序集合)
zset类型也是string类型元素的集合,但是它是有序的。
| 命令 | 用法 | 描述 |
|---|---|---|
| zadd | zadd key score member [score member ...] | (1)将一个或多个member元素及其score值加入集合key中; (2)如果member已经是有序集合的元素,那么更新member对应的score并重新插入member保证member在正确的位置上; (3)score可以是整数也可以是双精度浮点数。 |
| zcard | zcard key | (1)返回有序集的元素个数。 |
| zcount | zcount key min max | (1)返回有序集key中,score值>=min且<=max的成员数量 |
| zrange | zrange key start stop [withscores] | (1)返回有序集key中指定区间内的成员,成员位置按score从小到大排序; (2)如果score值相同,则按字典排序; (3)如果要使成员按score从大到小排序,则使用zrevrange命令。 |
| zrank | zrank key number | (1)返回有序集key中成员member的排名,有序集合按score值从小到大排列; (2)zrevrank命令将按照score值从大到小排序。 |
| zrem | zrem key member [member ...] | (1)移除有序集key中的一个或多个元素,不存在的元素将被忽略; (2)当key存在但不是有序集时,返回错误。 |
| zremrangebyrank | zremrangerank key start stop | (1)移除有序集key中指定排名区间内的所有元素。 |
| zremrangebyscore | zremrangescore key min max | (1)移除有序集key中所有score值>=min且<=max之间的元素。 |