
Hash(哈希)
大约 2 分钟
Hash(哈希)
Hash 是一个键值对集合。它是一个 string 类型的 field 和 value 的映射表,特别适用于存储对象,类似 Java 的 Map<String, Object>。
存储对象的几种方式
以"用户 ID 为查找的 key,value 为用户对象(包含姓名、年龄、生日等)"为例,对比常见存储方式:

- 整体序列化:将对象序列化后存储,每次修改对象都需要先反序列化,修改完数据后再序列化回去,存在反复序列化开销
- 平铺键值对:键是
用户 id + 属性标签,值是属性值,id 数据冗余且 key 数量膨胀
第三种方式(推荐):
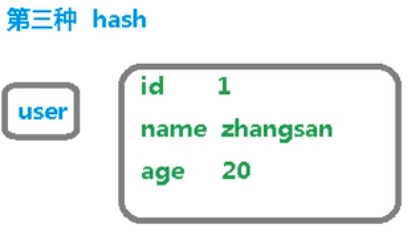
user 为 key,属性标签跟属性值是 value,存储方便,单个属性也可以独立读写。
常用命令
hset <key> <filed> <value> [filed value..] # <key>是hash的键,<filed>是value的键,<value>是值,可以批量设置;如果hash的key不存在则创建新的hash

hget <key> <filed> # 根据filed获取value
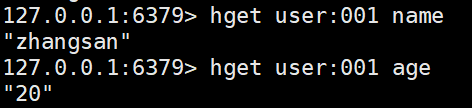
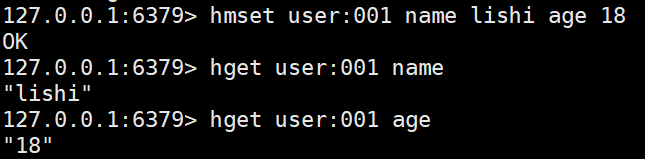
hmset <key> <filed> <value> [filed value ..] # 可以批量设置hash,如果key存在,filed相同则覆盖对应的value,否则创建一个新的hash
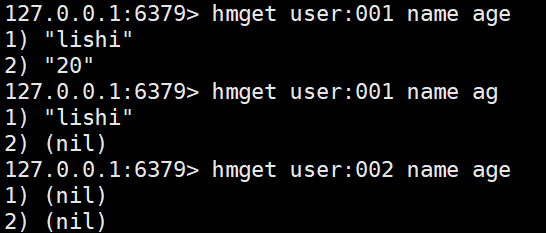
hmget <key> <filed> [filed ..] # 批量获取value,如果filed不存在返回nil,存在返回对应的value
hexists <key> <filed> # 判断对应的key是否存在filed
hkeys <key> # 查询对应的key的所有filed

hvals <key> # 查询对应key的所有value

hincrby <key> <field> <increment> # 为hash的key中的field的值增加或减少increment

hsetnx <key> <field> <value> # 为对应key添加filed和value,只有filed不存在时才会成功

底层结构
Hash 类型对应的数据结构有两种:ziplist(压缩列表) 和 hashtable(哈希表)。
- 当
field-value长度较短且个数较少时,使用ziplist,节省内存 - 否则使用
hashtable,保证 O(1) 的读写性能
Redis 7.0 起
ziplist已被listpack替代,行为基本一致但避免了连锁更新问题。
应用场景
- 存储对象:用户信息、商品信息等结构化数据
- 购物车:以用户 id 为 key,商品 id 为 field,数量为 value
- 配置中心:以业务模块为 key,配置项为 field