
RAG 评估体系与指标
RAG 评估体系与指标
构建 RAG 系统后,真正难的不是“让它能回答”,而是判断它回答得是否正确、可靠、可解释、可持续迭代。
如果没有评估体系,优化 RAG 往往会变成凭感觉调参:换一个 Embedding、改一下 Chunk 大小、加一个 Reranker,然后肉眼看几个 Case。这样很容易出现两个问题:
- 局部样本变好,整体质量变差:几个演示问题答得更顺,但真实用户问题的召回率下降。
- 无法定位问题来源:答案错了,不知道是检索没召回、上下文有噪音,还是 LLM 基于上下文乱发挥。
所以 RAG 评估的目标不是只给系统打一个总分,而是把系统拆成可诊断的链路:
用户问题
-> 检索器召回上下文
-> 生成器基于上下文回答
-> 最终答案被用户消费
对应的评估也可以分成三层:
检索评估:上下文是否找对了
响应评估:答案是否基于上下文、是否回答问题
端到端评估:整个系统是否满足业务目标
1. RAG Triad
RAG 评估中常用的框架是 RAG Triad(三元组)
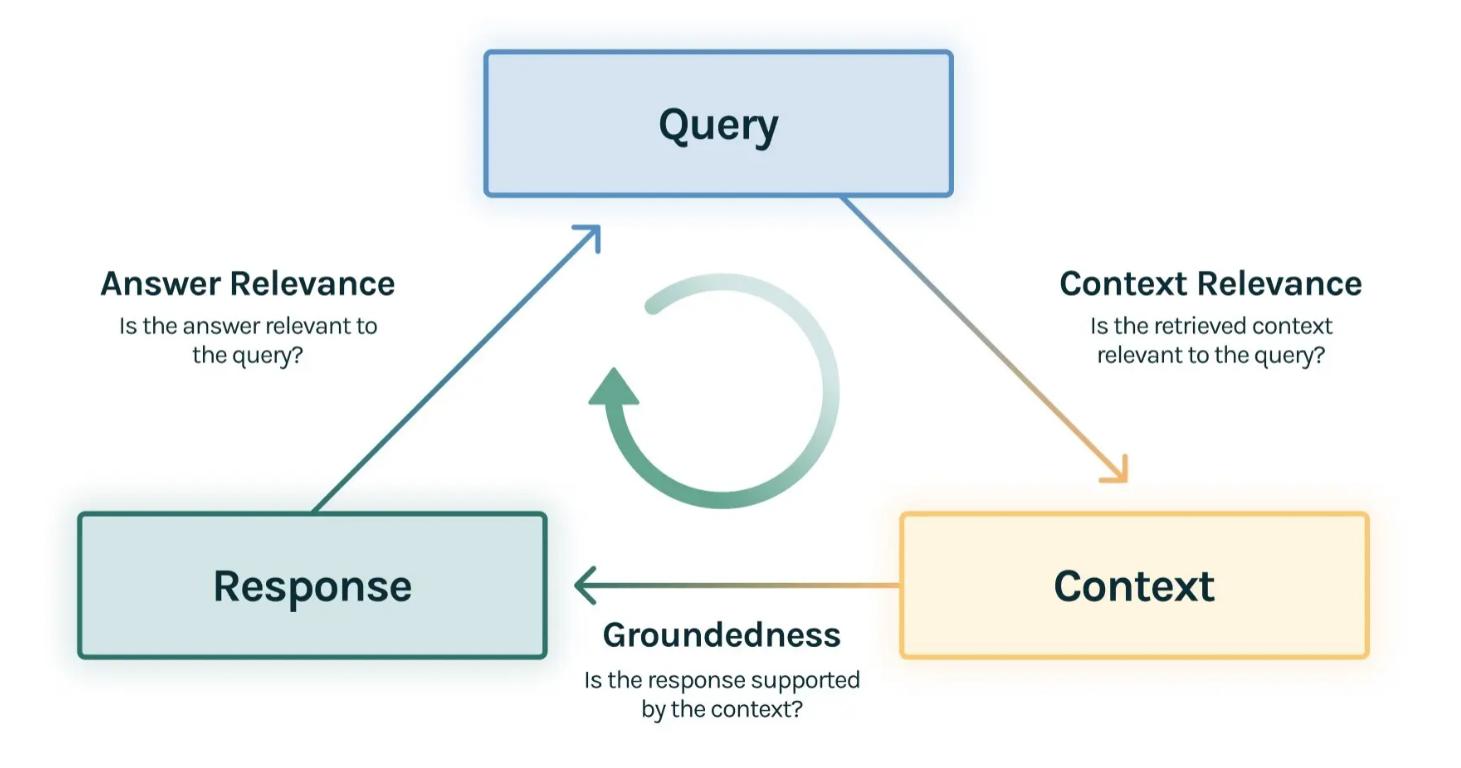
它从三个维度衡量系统质量:
通俗地说,RAG 三元组其实就是在问三个问题:
资料找得准不准?
回答有没有瞎编?
有没有真正解决用户问题?
也可以记成一句话:
找得对、说得真、答得准。
| 维度 | 核心问题 | 主要评估对象 | 典型问题 |
|---|---|---|---|
| Context Relevance | 检索到的上下文是否与问题相关 | Retriever | 召回噪音多、关键文档没进 Top-K |
| Faithfulness / Groundedness | 答案是否完全由上下文支持 | Generator | 模型编造事实、曲解上下文 |
| Answer Relevance | 答案是否直接回答用户问题 | 端到端输出 | 答非所问、只回答了一部分、冗余过多 |
这三个指标分别对应 RAG 的三个常见失败模式:
- 检索失败:知识库里有答案,但没被检索出来。
- 生成失败:上下文里有证据,但模型没有正确使用。
- 交互失败:答案看起来合理,但没有解决用户原始问题。
1.1 Context Relevance:上下文相关性
上下文相关性评估的是检索器。它关心的是:系统拿给 LLM 的材料是否真的和用户问题有关。
换句话说,它判断的是资料有没有找对。
例如用户问:
PF-2048 电源模块故障码 E07 如何处理?
如果系统召回了“PF-2048 的安装说明”和“E07 的通用错误码解释”,但没有召回“PF-2048 故障码 E07 的处理步骤”,那么上下文看似相关,实际上不足以支持可靠答案。
再举一个更生活化的例子:用户问“iPhone 15 怎么换电池?”,系统却检索到了“iPhone 15 怎么换壁纸?”。这些资料都和 iPhone 15 有关,但和“换电池”无关,因此上下文相关性很低。
上下文相关性低会直接导致:
- LLM 被无关内容干扰。
- Token 被噪音占用,真正证据被挤出上下文窗口。
- 模型为了完成回答而补充知识,产生幻觉。
1.2 Faithfulness:忠实度
忠实度评估的是答案是否被上下文支持。
换句话说,它判断的是回答有没有根据资料瞎编。
一个高忠实度答案必须满足:
- 答案中的关键事实都能在检索上下文中找到依据。
- 没有引入上下文之外的外部知识。
- 没有把上下文中的条件、范围、时间、否定关系说错。
低忠实度的典型表现是:
- 上下文只说“可能原因”,答案写成“确定原因”。
- 上下文给出版本 A 的配置,答案套用到版本 B。
- 上下文没有提到价格、时间、限制条件,答案却直接补全。
例如资料里只写了“电池更换需要到官方售后检测”,但模型回答“更换费用是 599 元,30 分钟可以完成”。如果资料里没有费用和时长,这部分就是模型自己补出来的,忠实度就低。
忠实度是 RAG 系统控制幻觉的核心指标。
1.3 Answer Relevance:答案相关性
答案相关性评估的是最终输出是否直接、完整地回答用户问题。
换句话说,它判断的是答案有没有真正解决用户的问题。
它和忠实度不是一回事。一个答案可以完全基于上下文,但仍然不相关。
例如用户问:
法国在哪里,首都是哪里?
答案只说:
法国位于西欧。
这个回答可能忠实于上下文,但没有回答“首都是哪里”,因此答案相关性不高。
再比如用户问“iPhone 15 换电池需要多少钱?”,答案却介绍“iPhone 15 使用的是锂离子电池,日常应避免过度充电”。这段话可能没错,也可能来自资料,但它没有回答“多少钱”,所以答案相关性低。
答案相关性通常关注:
- 是否回答了用户所有子问题。
- 是否避免无关背景介绍。
- 是否给出用户需要的格式、粒度和行动建议。
- 是否在信息不足时明确说明不知道,而不是绕开问题。
1.4 一个生活化比喻
可以把 RAG 系统想象成一个帮你查资料写答案的助理:
| 评估维度 | 对应助理的表现 |
|---|---|
| Context Relevance | 他拿来的资料是不是你要的资料 |
| Faithfulness | 他写答案时有没有严格根据资料写 |
| Answer Relevance | 最后写出来的内容有没有真正回答你的问题 |
如果资料拿错了,后面写得再漂亮也不可靠。如果资料拿对了,但答案里自己脑补,也不可靠。如果资料和事实都没问题,但没有回应用户真正关心的点,体验仍然不好。
2. 评估工作流
RAG 评估可以拆成两个主流程:检索评估和响应评估。
评估数据集
-> 检索评估:Query + 标注相关文档
-> 响应评估:Query + Context + Answer + 可选标准答案
-> 汇总分析:定位瓶颈并指导优化
2.1 检索评估
检索评估更像白盒测试。它要求我们知道每个问题应该命中哪些文档或 Chunk,然后检查检索器是否把它们排在前面。
评估数据通常包含:
| 字段 | 说明 |
|---|---|
| query | 用户问题或测试问题 |
| relevant_doc_ids | 标注的相关文档或 Chunk ID |
| retrieved_doc_ids | 系统实际召回的文档或 Chunk ID |
| rank | 文档在召回结果中的排序 |
| metadata | 文档来源、时间、类别、版本等辅助信息 |
Precision@K
Precision@K 衡量前 K 个检索结果里有多少是相关的。
它关注的是检索结果的信噪比。Precision@K 高,说明送给 LLM 的上下文噪音少。
适用场景:
- 控制上下文窗口成本。
- 评估 Reranker 是否把无关文档压下去了。
- 比较不同 Chunk 策略带来的噪音变化。
Recall@K
Recall@K 衡量系统是否把应该找回的文档找回来了。
它关注的是检索结果的完整性。Recall@K 低,说明知识库里明明有答案,但系统没有找到。
适用场景:
- 评估向量模型、BM25、混合检索的召回能力。
- 判断 Top-K 是否设置过小。
- 检查 Query 改写、HyDE、多查询检索是否提升召回。
F1-Score
F1 是 Precision 和 Recall 的调和平均,用于在准确性和完整性之间取平衡。
如果 Precision 高但 Recall 低,说明结果很干净但漏掉了证据。如果 Recall 高但 Precision 低,说明能找回证据,但噪音也多。
MRR
MRR(Mean Reciprocal Rank)评估第一个相关文档出现得有多靠前。
其中 rank_q 是第 q 个查询中第一个相关文档的排名。
MRR 适合用户通常只需要一个关键证据的场景,例如 FAQ、故障码、API 参数说明。
MAP
MAP(Mean Average Precision)综合考虑多个相关文档的命中和排序。
它比 MRR 更适合多证据问题,例如政策解释、复杂技术方案、多文档综合问答。
2.2 响应评估
响应评估关注的是生成答案本身,通常对应 RAG Triad 中的忠实度和答案相关性。
响应评估数据通常包含:
| 字段 | 说明 |
|---|---|
| question | 用户问题 |
| contexts | 检索到的上下文 |
| answer | RAG 系统生成的答案 |
| ground_truth | 可选的标准答案 |
| reference_docs | 可选的标准证据来源 |
响应评估常见有两类方法。
LLM-as-a-Judge
LLM-as-a-Judge 是当前 RAG 评估中最常用的方法之一。它使用一个较强的模型作为评估器,对答案进行语义判断。
忠实度评估的一般流程:
- 把答案拆成多个独立声明。
- 对每个声明检查是否能被上下文支持。
- 计算被支持声明的比例。
答案相关性评估的一般流程:
- 同时输入用户问题和生成答案。
- 判断答案是否直接回应问题。
- 惩罚答非所问、遗漏子问题、冗余展开和格式不符合要求。
示例 Prompt:
你是 RAG 答案评估器。请根据用户问题、检索上下文和模型答案进行评分。
评分维度:
1. faithfulness:答案中的事实是否都能被上下文支持,0 到 1。
2. answer_relevance:答案是否直接完整回答问题,0 到 1。
3. reason:用一句话说明扣分原因。
要求:
- 只根据给定上下文判断。
- 信息不足时应扣分。
- 只输出 JSON。
用户问题:
{question}
检索上下文:
{contexts}
模型答案:
{answer}
输出示例:
{
"faithfulness": 0.75,
"answer_relevance": 0.9,
"reason": "答案整体切题,但关于处理时限的说法没有上下文证据支持。"
}
LLM 评估的优点是能理解语义、逻辑和同义表达;缺点是成本较高,也会受到评估模型偏见、Prompt 设计和随机性的影响。
词汇重叠指标
如果有标准答案,也可以使用 ROUGE、BLEU、METEOR 等经典指标。
| 指标 | 关注点 | 适用场景 | 局限 |
|---|---|---|---|
| ROUGE | 标准答案中的内容被覆盖了多少 | 摘要、答案完整性评估 | 不擅长判断语义等价 |
| BLEU | 生成答案中的词有多少和标准答案匹配 | 翻译、短文本精确匹配 | 对开放式问答不够友好 |
| METEOR | 同时考虑精确率、召回率和词形变化 | 更细的文本相似度评估 | 中文场景和专业术语需要额外处理 |
这类指标计算快、成本低、稳定,但无法真正理解答案是否事实正确。实践中更适合做大规模粗筛,再配合 LLM 评估和人工抽检。
3. 端到端评估
检索指标和响应指标都很重要,但最终仍要回到业务目标。
一个生产级 RAG 系统通常还需要评估:
| 指标 | 含义 |
|---|---|
| Answer Correctness | 答案是否事实正确、完整 |
| Refusal Accuracy | 无答案时是否正确拒答 |
| Citation Accuracy | 引用来源是否真实支持答案 |
| Latency P50 / P95 | 响应延迟是否可接受 |
| Token Cost | 单次请求成本是否可控 |
| User Satisfaction | 用户是否认为答案有用 |
| Regression Rate | 新版本相对旧版本是否退化 |
端到端评估建议同时保留自动评估分数和人工标注结果。自动评估用于快速回归,人工标注用于校准评估器和判断高风险问题。
4. 评估集构建
评估集的质量决定了评估结果是否可信。一个实用的 RAG 评估集至少应该覆盖下面几类样本:
- 简单事实问题:答案在单个 Chunk 中,验证基础召回和生成。
- 多跳问题:答案需要综合多个文档,验证召回完整性和推理能力。
- 关键词问题:包含型号、编号、人名、API、错误码,验证稀疏检索和混合检索。
- 无答案问题:知识库中没有答案,验证拒答能力。
- 相似实体问题:多个实体名称相近,验证检索是否串对象。
- 时效性问题:政策、价格、版本、接口变更,验证元数据过滤和新旧文档处理。
评估集可以按下面的字段组织:
{
"id": "rag_eval_001",
"question": "PF-2048 电源模块故障码 E07 如何处理?",
"ground_truth": "先检查输入电压,再复位保护开关;若仍报警需更换模块。",
"relevant_doc_ids": ["manual_pf2048_error_e07"],
"must_cite": true,
"answerable": true,
"tags": ["fault-code", "exact-match", "single-hop"]
}
数据来源建议按优先级选择:
- 真实用户日志中的高频问题。
- 客服、售后、运营团队沉淀的标准问答。
- 文档负责人标注的关键问题。
- LLM 从文档中自动生成的问题,再由人工抽样校验。
5. 诊断方法
评估最有价值的地方不是得分,而是定位问题。
可以按下面的方式解读评估结果:
| 现象 | 可能原因 | 优化方向 |
|---|---|---|
| Recall@K 低 | Query 表达和文档不匹配、Chunk 切分不合理、纯向量漏召回 | 查询改写、混合检索、调整 Chunk、扩大候选池 |
| Precision@K 低 | 噪音文档太多、缺少元数据过滤、排序不准 | 元数据过滤、RRF、Reranker、相似文档去重 |
| MRR 低 | 正确文档能召回但排序靠后 | Cross-Encoder、ColBERT、RankLLM |
| Faithfulness 低 | 模型自由发挥、上下文证据不足、Prompt 约束弱 | 强化引用、答案声明校验、C-RAG、拒答策略 |
| Answer Relevance 低 | 没理解用户意图、问题拆解失败、答案模板不合适 | Query 分析、多查询拆分、答案格式约束 |
| Refusal Accuracy 低 | 无答案时强行回答 | 加入无答案样本、检索置信度阈值、评估器分流 |
6. 推荐落地流程
一套可落地的 RAG 评估流程可以这样搭:
1. 准备 50 到 200 条高质量评估问题
2. 为每条问题标注标准答案、相关文档、是否可回答
3. 跑当前 RAG Pipeline,记录检索结果、上下文、答案和引用
4. 计算检索指标:Recall@K、Precision@K、MRR、MAP
5. 计算响应指标:Faithfulness、Answer Relevance、Answer Correctness
6. 人工抽检低分样本,归因到检索、生成、数据或产品需求
7. 针对瓶颈优化 Pipeline
8. 每次改动后跑回归评估,比较新旧版本
工程上建议记录完整链路日志:
{
"query": "...",
"rewritten_query": "...",
"retrieved_docs": [
{
"doc_id": "...",
"rank": 1,
"score": 0.82,
"source": "dense"
}
],
"context": "...",
"answer": "...",
"citations": ["..."],
"eval": {
"context_precision": 0.8,
"context_recall": 1.0,
"faithfulness": 0.75,
"answer_relevance": 0.9
}
}
小结
- RAG 评估的核心是 RAG Triad:上下文相关性、忠实度、答案相关性。
- 用大白话记:Context Relevance 是“找得对”,Faithfulness 是“说得真”,Answer Relevance 是“答得准”。
- 检索评估负责判断“材料找对没”,常用 Precision@K、Recall@K、MRR、MAP。
- 响应评估负责判断“答案靠不靠谱”,常用 Faithfulness、Answer Relevance、Answer Correctness。
- 端到端评估还要加入拒答准确率、引用准确率、延迟、成本和用户满意度。
- 评估不是一次性验收,而是 RAG 系统持续迭代的回归测试基础。