
高级检索技巧
高级检索技巧
在基础的 RAG 流程中,我们通常先把文档切分成 Chunk,再用 Embedding 建立向量索引,最后根据向量相似度召回 Top-K 文档。这套流程简单、通用,但在生产环境里很容易遇到三个问题:
- 召回结果顺序不稳定:向量相似度高,不代表一定最能回答用户问题。
- 上下文噪音太多:检索到的 Chunk 可能只有一两句话有用,其余内容会占用上下文窗口。
- 检索失败不可见:当检索结果不相关、过时或相互冲突时,LLM 仍然可能强行回答。
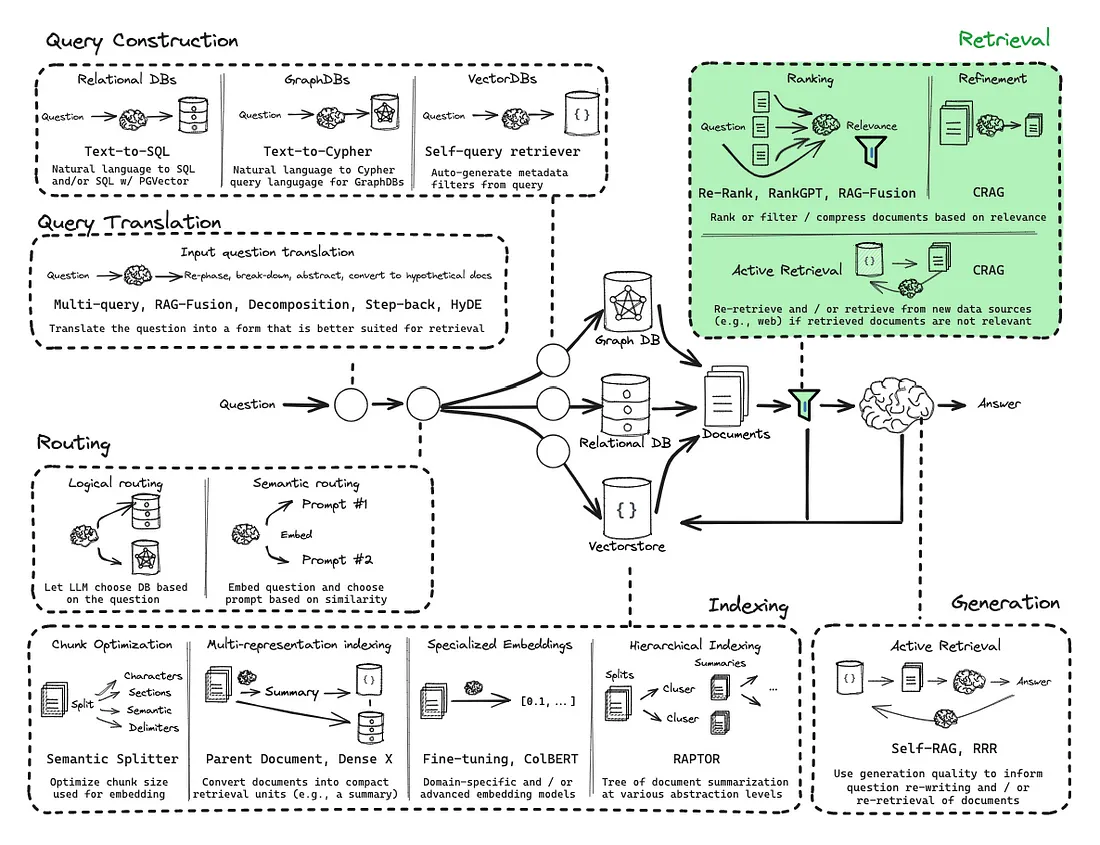
前面已经介绍了查询重构、混合检索等方法,它们主要解决的是“如何召回更多可能相关的候选文档”。本节继续往后走,重点关注召回之后的三类增强技术:
- 重排序(Reranking):从候选文档中挑出最相关的内容,并把它们排到前面。
- 压缩(Compression):从相关文档中抽出真正有用的信息,减少噪音和 Token 成本。
- 校正(Correction):评估检索质量,在检索失败时触发补救动作,避免错误上下文误导生成。
可以把它们理解为生产级 RAG 的后处理流水线:
用户问题
-> 查询重构 / 混合检索
-> 候选召回 Top-50/Top-100
-> 重排序 Top-10/Top-20
-> 上下文压缩 Top-5/Top-8
-> 检索质量校正
-> LLM 生成答案
1. 重排序
向量检索的第一阶段更像是“粗召回”:它要尽可能把相关文档捞出来,但不一定能把最好的文档排到最前面。重排序的目标就是在候选池上再做一次精排,把“最能回答当前 Query 的文档”放到上下文前部。
典型做法是:
- 用向量检索、BM25 或混合检索召回较大的候选池,例如 Top-50。
- 对候选文档进行去重、截断、清洗。
- 用重排序方法重新计算 Query 和文档的相关性。
- 取重排后的 Top-5 到 Top-10 送入后续压缩或生成阶段。
1.1 RRF:倒数排名融合
RRF(Reciprocal Rank Fusion) 是最简单、最稳的重排序/融合方法,尤其适合多路召回结果合并。例如前面混合检索中同时使用 BM25 和稠密向量时,可以用 RRF 把两路结果融合成一个统一列表。
它不依赖原始分数,只关心文档在每个检索器里的排名。对任一文档
其中:
- 文档在多路结果中都靠前时,最终分数会更高。
实施步骤
- 准备多路结果:例如 BM25 Top-50、Dense Top-50、HyDE Top-30。
- 统一文档 ID:按
chunk_id或内容哈希去重,避免同一 Chunk 被重复计算。 - 计算排名贡献:每一路只使用排名,不使用原始相似度分数。
- 求和排序:按 RRF 分数降序排列。
- 截断候选池:通常取 Top-20 或 Top-30,再交给更强的重排模型。
def rrf(result_lists, k: int = 60, top_k: int = 20):
scores = {}
for results in result_lists:
# results: 按相关性降序排列的 doc_id 列表
for rank, doc_id in enumerate(results, start=1):
scores[doc_id] = scores.get(doc_id, 0.0) + 1.0 / (k + rank)
return sorted(scores.items(), key=lambda x: -x[1])[:top_k]
适用场景
- 已经有多路检索结果,例如 BM25 + Dense、Dense + HyDE、多查询检索。
- 各路检索分数尺度不同,难以做归一化。
- 希望用低成本方式提升排序稳定性。
局限
RRF 只看排名,不看分数。如果某一路检索器的第 1 名和第 10 名分数差距极大,RRF 也不会感知这种差距。因此它更适合做融合粗排,不适合替代语义精排模型。
1.2 Cross-Encoder:逐对精排
Cross-Encoder 是最常见的精排模型。它会把 Query 和候选文档拼在一起输入模型,让模型直接判断二者是否相关。
与普通 Embedding 模型的区别是:
| 模型 | 编码方式 | 检索速度 | 精度 | 典型用途 |
|---|---|---|---|---|
| Bi-Encoder | Query 和文档分别编码,再算向量相似度 | 快 | 中 | 大规模召回 |
| Cross-Encoder | Query 和文档一起输入模型,直接输出相关性分数 | 慢 | 高 | 小候选集精排 |
因为 Cross-Encoder 需要对每个 Query-Doc 对都跑一次模型,所以它不能用于全量检索,只适合对召回后的 Top-N 做精排。
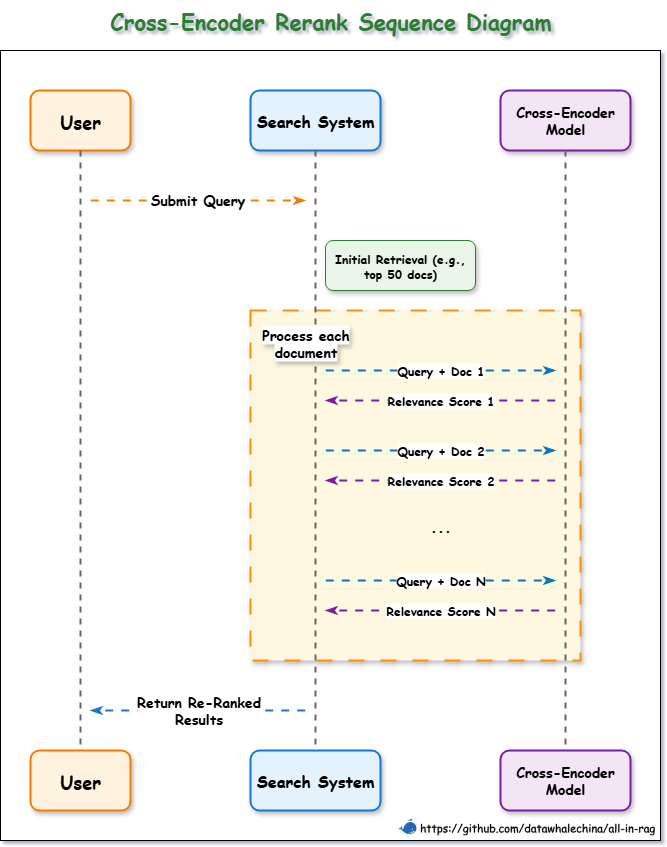
实施步骤
- 召回候选池:先用混合检索拿到 Top-50 或 Top-100。
- 限制文档长度:每个 Chunk 控制在 256 到 512 tokens,过长会增加延迟并稀释相关信息。
- 批量打分:把
(query, chunk)成对输入 reranker 模型。 - 按分数重排:取分数最高的 Top-5 到 Top-10。
- 设置降级策略:如果 reranker 超时,则回退到 RRF 或原始向量排序。
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("BAAI/bge-reranker-base")
def cross_encoder_rerank(query: str, docs: list[dict], top_k: int = 8):
pairs = [(query, doc["content"]) for doc in docs]
scores = reranker.predict(pairs)
ranked = sorted(
zip(docs, scores),
key=lambda x: x[1],
reverse=True,
)
return [doc | {"rerank_score": float(score)} for doc, score in ranked[:top_k]]
选型建议
- 中文或中英混合知识库:优先考虑
bge-reranker-base、bge-reranker-large、bge-reranker-v2-m3。 - 英文问答或 Web 检索:可以考虑 MonoT5、Cohere Rerank、Voyage reranker 等服务化模型。
- 延迟敏感场景:先用小模型精排 Top-30;只有高价值请求才使用大模型精排。
1.3 RankLLM:用大模型做列表级重排
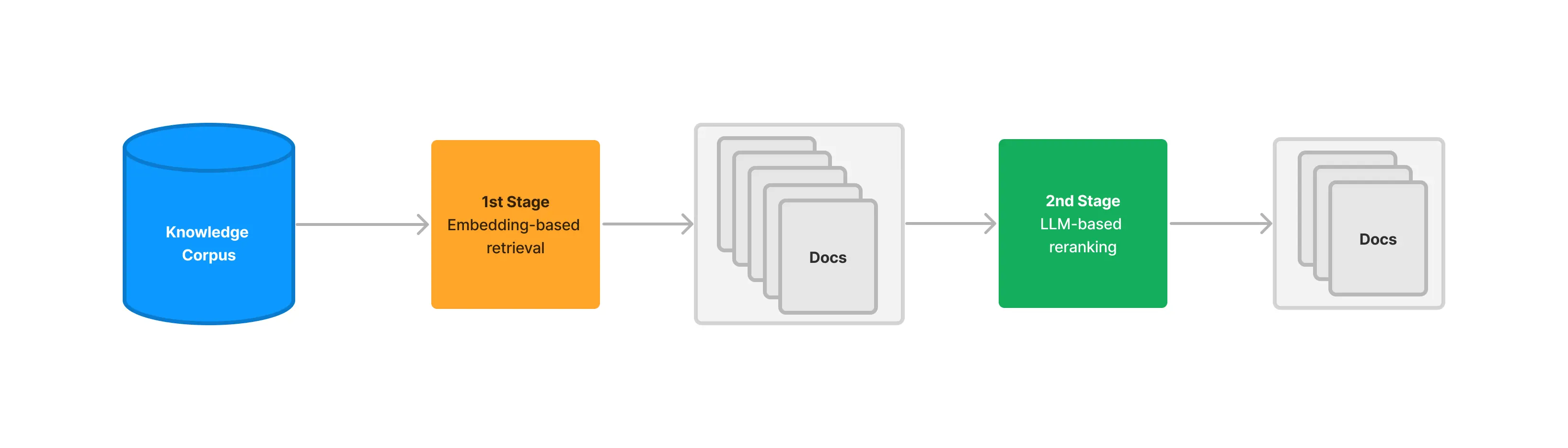
RankLLM 不是单一模型,而是一类用 LLM 进行排序的方法。它的核心思想是:不要让模型只看一个 Query-Doc 对,而是把多个候选文档放在同一个 Prompt 里,让 LLM 直接输出更合理的文档顺序。
这种方法也常被称为 Listwise Reranking。相比 Cross-Encoder 的 pairwise 打分,Listwise 让模型同时比较多个候选,因此更接近人类做排序判断的方式。
Prompt 示例
你是一个搜索排序专家。请根据用户问题,对候选文档按相关性从高到低排序。
要求:
1. 只根据文档内容判断,不要补充外部知识。
2. 优先选择能直接回答问题的文档。
3. 如果文档只提到相关概念但不能回答问题,排序靠后。
4. 只输出文档编号列表,例如:[3, 1, 5, 2, 4]
用户问题:
{query}
候选文档:
[1] {doc_1}
[2] {doc_2}
[3] {doc_3}
...
实施步骤
- 先粗排再分组:不要一次塞入太多文档。通常对 RRF 或 Cross-Encoder 的 Top-20 做处理。
- 窗口化排序:每次让 LLM 排 5 到 10 个文档,避免 Prompt 过长导致排序不稳定。
- 滑动窗口合并:如果候选很多,可以使用
window_size=10、step=5的方式多轮排序。 - 约束输出格式:要求只输出文档 ID 数组,并做 JSON 解析校验。
- 结果校验:如果输出 ID 缺失、重复或越界,重试一次;仍失败则回退到上一阶段排序。
def validate_ranked_ids(ranked_ids: list[int], valid_ids: set[int]) -> bool:
return (
len(ranked_ids) == len(set(ranked_ids))
and set(ranked_ids).issubset(valid_ids)
)
适用场景
- 用户问题复杂,需要综合多个文档判断哪个更能回答问题。
- 文档很短,单个 Cross-Encoder 分数不足以表达整体优先级。
- 对答案质量要求高,能接受额外 LLM 调用成本。
局限
- 延迟和成本明显高于 Cross-Encoder。
- 输出格式需要严格约束,否则容易出现漏编号、重复编号。
- 长列表排序容易出现位置偏置,通常需要窗口化或多轮排序。
1.4 ColBERT:多向量后期交互
ColBERT 介于 Bi-Encoder 和 Cross-Encoder 之间。普通向量检索会把一个 Chunk 压成一个向量,而 ColBERT 会为 Query 和文档中的多个 Token 分别保留向量,再通过后期交互(Late Interaction)计算细粒度相关性。
直观理解:
- Bi-Encoder:一段文档只有一个整体向量,快但细节容易丢。
- Cross-Encoder:Query 和文档完全交互,准但慢。
- ColBERT:文档向量可以提前离线算好,查询时再做 Token 级匹配,兼顾效果和效率。
ColBERT 常用的打分方式是 MaxSim:对 Query 中每个 Token,找到文档 Token 中最相似的一个,再把这些最大相似度求和。
实施步骤
- 文档侧离线编码:为每个 Chunk 生成多向量表示,而不是单一向量。
- 建立多向量索引:使用支持多向量检索的引擎,或使用专门的 ColBERT 检索框架。
- 查询侧实时编码:用户 Query 到来时生成 Query Token 向量。
- 候选检索与打分:通过 MaxSim 计算 Query 和文档的细粒度匹配分。
- 融合其他结果:可以与 BM25、Dense 结果再做 RRF,形成更稳的候选池。
适用场景
- 文档中有大量术语、代码标识符、短语匹配需求。
- 单向量检索召回不稳定,但 Cross-Encoder 成本又太高。
- 希望在召回阶段就引入更强的细粒度语义匹配。
局限
ColBERT 的索引体积通常大于普通稠密向量索引,工程复杂度也更高。对于一般企业知识库,优先级通常是:
Dense + BM25 + RRF
-> Cross-Encoder Rerank
-> ColBERT / 多向量检索
-> RankLLM
这个顺序不是绝对的,但符合多数系统的成本收益曲线。
1.5 重排序选型表
| 方法 | 输入 | 优点 | 缺点 | 推荐位置 |
|---|---|---|---|---|
| RRF | 多路排名列表 | 简单、稳定、无训练、无需分数归一化 | 不理解文本内容 | 多路召回后的融合粗排 |
| Cross-Encoder | Query + 单个文档 | 精度高、工程成熟 | 对每个候选都要打分,延迟较高 | Top-20 到 Top-100 精排 |
| RankLLM | Query + 文档列表 | 能做列表级比较,适合复杂问题 | 成本高,输出需校验 | 高价值请求或最终精排 |
| ColBERT | Query 多向量 + 文档多向量 | 细粒度匹配,兼顾效果和效率 | 索引和部署复杂 | 高质量召回或多向量检索 |
2. 压缩
重排序解决的是“哪些文档更重要”,压缩解决的是“文档里哪些内容真正有用”。
RAG 中常见的 Chunk 往往是按固定长度切出来的,例如 500 到 1000 tokens。它可能整体相关,但真正回答问题的只有其中几句话。如果直接把完整 Chunk 塞给 LLM,会带来三个问题:
- Token 成本增加:上下文越长,推理越贵。
- 噪音干扰生成:LLM 可能关注到不相关片段。
- 关键信息被淹没:长上下文中间的信息容易被忽略。
上下文压缩的目标是:在不损失答案所需证据的前提下,删除无关内容,把输入变短、变准、变可控。
2.1 压缩的三种层级
| 层级 | 做法 | 成本 | 适用场景 |
|---|---|---|---|
| 文档级过滤 | 删除整篇无关 Chunk | 低 | 候选池噪音多 |
| 句子/段落级抽取 | 只保留与 Query 相关的句子或段落 | 中 | Chunk 较长但局部相关 |
| Token/语义级压缩 | 用模型压缩 Prompt 或重写摘要 | 高 | 上下文窗口紧张、成本敏感 |
生产系统里建议按从低到高的顺序做,不要一上来就让 LLM 摘要所有文档。一个更稳的流水线是:
检索 Top-50
-> 重排序 Top-10
-> 文档级过滤 Top-6
-> 句子级抽取
-> 必要时再做摘要压缩
2.2 文档级过滤
文档级过滤是最便宜的压缩方式。本质上是设一个相关性门槛,低于门槛的 Chunk 不进入上下文。
实施步骤
- 对候选 Chunk 做 Cross-Encoder 或 reranker 打分。
- 设置最低分数阈值,例如
score >= 0.35。 - 同时设置最少保留数量,例如至少保留 Top-3,避免阈值过高导致无上下文。
- 对重复 Chunk、同一文档相邻 Chunk 做合并或去重。
def filter_docs(ranked_docs: list[dict], min_score: float = 0.35, min_keep: int = 3):
kept = [doc for doc in ranked_docs if doc.get("rerank_score", 0) >= min_score]
if len(kept) < min_keep:
kept = ranked_docs[:min_keep]
return kept
注意点
- 阈值必须通过评估集调参,不能只凭感觉。
- 不同 reranker 的分数分布不同,换模型后阈值要重新校准。
- 对 FAQ、政策条款、故障码等强事实场景,宁可多保留一点,也不要过早过滤。
2.3 句子级抽取
句子级抽取适合处理“Chunk 整体相关,但只有局部有用”的情况。它不是重写文档,而是从原文中抽出与问题相关的句子,保留可追溯证据。
实施步骤
- 切句:按句号、换行、项目符号、代码块边界切分。
- 句子打分:用 Query 和每个句子计算相似度,也可以用小型 Cross-Encoder。
- 选择证据句:保留 Top-N 句子,或保留超过阈值的句子。
- 保留邻近上下文:对命中句前后各保留一句,避免断章取义。
- 按原文顺序拼回:不要按分数重新排列句子,否则容易破坏逻辑。
def extract_sentences(sentences: list[str], scores: list[float], top_n: int = 5):
selected = sorted(
sorted(range(len(sentences)), key=lambda i: scores[i], reverse=True)[:top_n]
)
return "\n".join(sentences[i] for i in selected)
适用场景
- 技术文档、产品说明、API 文档。
- 用户问题只需要某个步骤、参数、限制条件。
- 需要保留原文证据,不能让模型自由摘要。
2.4 LLM 摘要压缩
摘要压缩是让 LLM 根据用户问题,把检索文档改写成更短的上下文。它比抽取更灵活,但也更容易引入错误,因此必须明确约束。
Prompt 模板
你是 RAG 上下文压缩器。请根据用户问题,从文档中提取能回答问题的关键信息。
要求:
1. 只能使用文档中的信息,不要补充外部知识。
2. 保留关键实体、数字、条件、例外和限制。
3. 如果文档与问题无关,输出:无相关信息。
4. 输出应简洁,但不要丢失回答问题所需的证据。
用户问题:
{query}
文档:
{document}
压缩后的上下文:
实施步骤
- 只对重排后的 Top-5 到 Top-8 做摘要,避免成本失控。
- 给每个文档单独摘要,不要把所有文档一次性混在一起。
- 保留来源信息,例如
source_id、标题、页码、URL。 - 对摘要后的内容再次做长度控制,例如每个文档 100 到 200 字。
- 生成答案时要求引用压缩片段对应的来源。
风险控制
- 摘要可能遗漏细节,尤其是数字、边界条件、否定句。
- 摘要可能把多个文档的信息合并成错误结论。
- 高风险场景建议使用“抽取优先,摘要兜底”的策略。
2.5 Prompt 压缩
Prompt 压缩更关注 Token 级别的成本优化。典型方法如 LLMLingua,会用小模型识别 Prompt 中信息量较低的 Token,在尽量保留语义的情况下压缩输入。
它适合上下文非常长、成本压力明显的场景,但对普通知识库问答不是第一优先级。原因是压缩后的文本对人类不一定可读,排查问题会更困难。
落地建议
- 先做检索侧压缩:过滤、抽取、摘要。
- 如果 Token 仍然超预算,再做 Prompt 压缩。
- 对压缩比例设置上限,例如 2x 到 5x 起步,不要直接追求极限压缩。
- 评估时同时看答案准确率、引用完整性和成本下降比例。
2.6 压缩效果评估
压缩不能只看 Token 省了多少,还要看答案有没有变差。建议同时监控:
- Token Reduction:压缩前后 Token 数下降比例。
- Answer Accuracy:答案是否仍然正确。
- Citation Recall:最终答案引用的证据是否仍在压缩上下文中。
- Faithfulness:答案是否完全由上下文支持。
- Latency:压缩步骤是否抵消了 Token 减少带来的收益。
一个实用原则是:
如果压缩让 Token 降低 50%,但答案准确率下降超过 3% 到 5%,通常不值得上线。
3. 校正
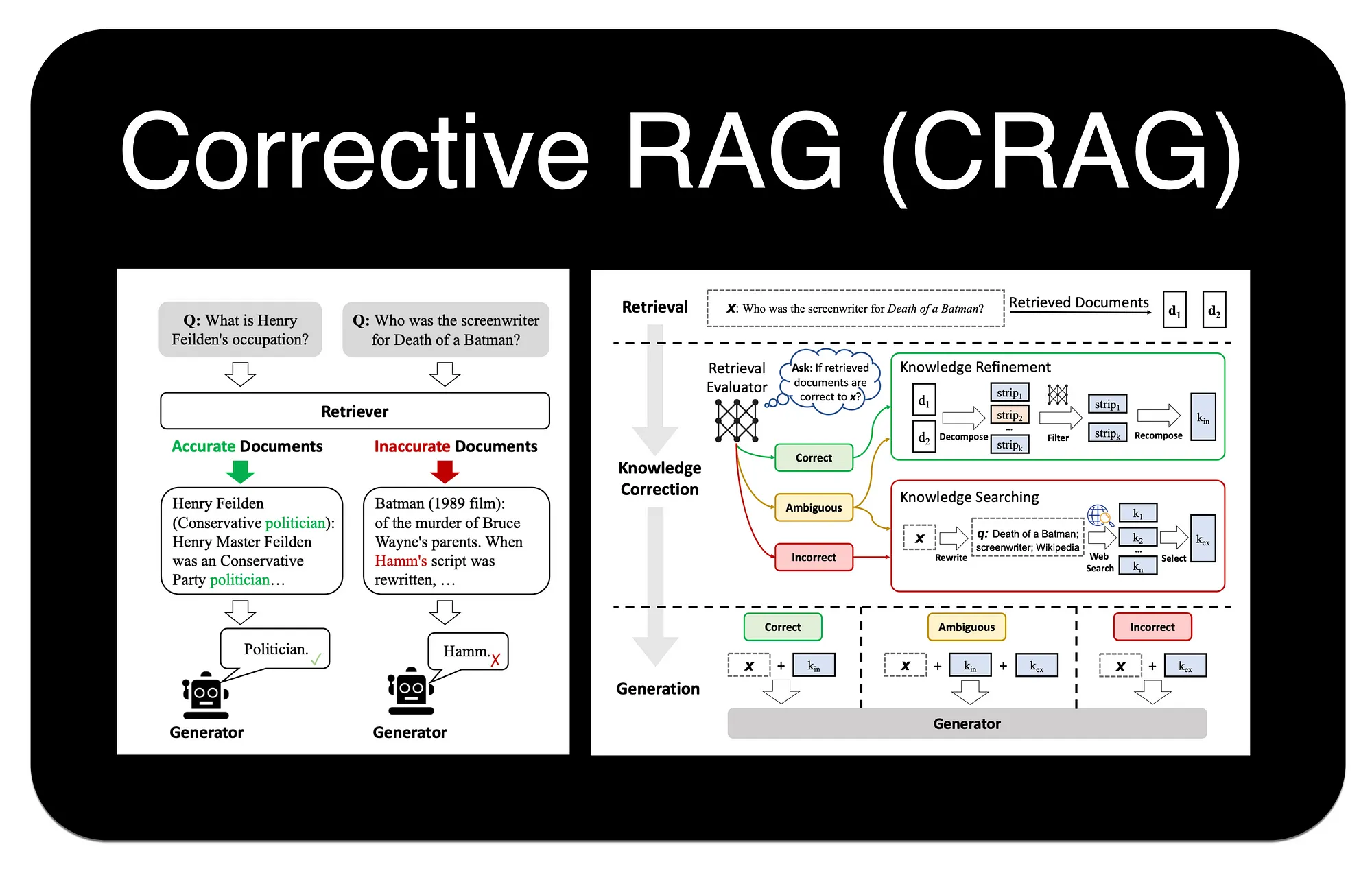
传统的 RAG 流程有一个隐含的假设:检索到的文档总是与问题相关,并且包含正确答案。然而在现实世界中,检索系统可能会失败,返回不相关、过时,甚至完全错误的文档。如果将这些有毒的上下文直接喂给 LLM,就可能导致幻觉(Hallucination)或产生错误回答。
校正检索(Corrective-RAG, C-RAG) 正是为解决这一问题而提出的一种策略。它的思路是在生成答案之前,引入一个“自我反思”或“自我修正”的循环:先评估检索到的文档质量,再根据评估结果采取不同的行动,而不是默认所有检索结果都可以直接用于生成。
C-RAG 的工作流程可以概括为三个阶段:检索 -> 评估 -> 行动。
3.1 检索:先拿到候选证据
第一阶段仍然是普通 RAG 的检索过程,但这里有一个关键差异:检索结果只是候选证据,不是可信证据。系统需要先尽量召回可能相关的内容,后面再判断它们是否真的可用。
一个比较稳的检索入口是:
用户 Query
-> 查询改写
-> Dense 向量检索 Top-50
-> BM25 / 稀疏检索 Top-50
-> RRF 融合 Top-30
-> Cross-Encoder 重排 Top-10
检索阶段要做什么
- 扩大候选池:不要只取向量 Top-5。校正需要有足够候选可判断,通常先召回 Top-30 到 Top-100。
- 保留检索元数据:记录
source_id、标题、时间、相似度分数、rerank 分数、召回来源。 - 多路召回:Dense 负责语义相关,BM25 负责关键词和专有名词,必要时加入 HyDE 或 Step-Back。
- 初步去重:按
chunk_id、URL、内容哈希去重,避免同一段内容重复影响后续判断。 - 保留失败信号:如果 Top-K 分数整体偏低、候选高度重复、来源单一,都应作为后续评估的风险信号。
为什么不能直接生成
向量检索返回的是“语义相近”,不是“事实正确”。例如用户问“产品 A 的退款规则”,系统可能召回“产品 B 的退款规则”;它们在语义上相近,但事实对象不同。如果直接交给 LLM,模型很容易把错误上下文包装成看似合理的答案。
3.2 评估:判断文档质量
第二阶段是 C-RAG 的核心:对检索结果进行质量评估。评估的目标不是回答问题,而是判断当前上下文是否足以支持一个可靠答案。
最简单、也最容易落地的方式,是把检索结果分成三类:
| 标签 | 含义 | 后续动作 |
|---|---|---|
| Correct | 文档能直接支持答案 | 进入压缩和生成 |
| Ambiguous | 文档部分相关,但证据不足、信息不完整或存在冲突 | 补充检索、查询改写、交叉验证 |
| Incorrect | 文档明显不相关、过时或无法回答问题 | 重新检索;仍失败则拒答 |
评估维度
- 相关性:文档是否讨论了用户问题中的核心实体、事件和意图。
- 充分性:文档是否包含回答问题所需的关键事实,而不是只提到相关概念。
- 一致性:多个文档之间是否互相矛盾。
- 时效性:文档是否过期,尤其是政策、价格、版本、接口、规则类内容。
- 可引用性:是否能从文档中摘出明确证据支持答案。
LLM 评估器
如果没有训练专门的检索评估模型,可以先用 LLM 做轻量评估器。
Prompt 模板:
你是 RAG 检索质量评估器。请判断下面的检索文档是否足以回答用户问题。
只输出 JSON,不要输出解释性文字。
评分标准:
- relevant: 文档是否与问题相关,取值 true/false。
- sufficient: 文档是否足以支持完整答案,取值 true/false。
- conflict: 文档是否存在明显冲突,取值 true/false。
- label: 只能是 "correct"、"ambiguous"、"incorrect"。
- reason: 用一句话说明判断依据。
用户问题:
{query}
检索文档:
{context}
输出示例:
{
"relevant": true,
"sufficient": false,
"conflict": false,
"label": "ambiguous",
"reason": "文档解释了错误码含义,但没有给出处理步骤。"
}
实施步骤
- 把重排序和压缩后的上下文交给评估器,不要把 Top-50 原文全部塞进去。
- 要求结构化 JSON 输出,便于程序分流。
- 对
correct、ambiguous、incorrect三类结果设置不同动作。 - 记录评估标签、原因、触发动作,用于后续评估和调参。
- 高风险场景可以加入人工审核,或要求至少两个独立来源互相验证。
3.3 行动:根据评估结果分流
第三阶段是“行动”。评估完成后,系统不应该只有“继续生成”一个动作,而应该根据文档质量分流。
Correct:直接生成
当上下文相关、充分、一致时,可以进入答案生成:
- 将压缩后的上下文送入生成模型。
- 要求答案引用来源。
- 要求模型只基于上下文回答,不确定处明确说明。
Ambiguous:补充检索
当上下文部分相关,但不足以支撑完整答案时,不要立刻生成。可以采取以下补救动作:
- 扩大 Top-K:从 Top-10 扩大到 Top-30。
- 查询重写:把用户问题改写得更明确。
- 多查询拆分:对复合问题拆成多个子问题分别检索。
- 切换检索器:如果 Dense 结果不足,补 BM25;如果 BM25 不足,补 HyDE 或 Step-Back。
- 外部检索:如果业务允许,可以补充 Web 搜索或实时数据库查询。
Incorrect:拒答或重新检索
当文档明显不相关、过时或无法回答问题时,不应该让 LLM 强行回答。建议:
- 用改写后的 Query 重新检索一次。
- 如果第二次仍然失败,回答“当前知识库没有足够信息”。
- 给出缺失信息类型,例如“缺少具体版本号”“缺少错误码说明文档”。
- 记录失败 Query,进入知识库补全或索引优化流程。
3.4 一套可落地的 C-RAG 流程
下面是一套比较稳的生产流程:
1. 用户输入 Query
2. 查询改写,得到 rewritten_query
3. 混合检索:BM25 Top-50 + Dense Top-50
4. RRF 融合,得到 Top-30
5. Cross-Encoder 重排,得到 Top-10
6. 上下文压缩,得到 Top-5 证据片段
7. LLM 检索评估器打标签:correct / ambiguous / incorrect
8. 根据标签采取行动:
- correct:生成答案
- ambiguous:补充检索一次,再重新评估
- incorrect:重新检索一次;仍失败则拒答
9. 记录全链路日志:Query、召回文档、分数、标签、最终答案
伪代码:
def corrective_rag(query: str):
rewritten = rewrite_query(query)
dense_docs = dense_retrieve(rewritten, top_k=50)
sparse_docs = bm25_retrieve(rewritten, top_k=50)
candidates = rrf_fusion([dense_docs, sparse_docs], top_k=30)
ranked_docs = cross_encoder_rerank(rewritten, candidates, top_k=10)
compressed_context = compress_context(query, ranked_docs[:5])
grade = grade_retrieval(query, compressed_context)
if grade["label"] == "correct":
return generate_answer(query, compressed_context)
if grade["label"] == "ambiguous":
extra_docs = expand_retrieve(query, rewritten)
merged_context = compress_context(query, ranked_docs[:5] + extra_docs)
second_grade = grade_retrieval(query, merged_context)
if second_grade["label"] == "correct":
return generate_answer(query, merged_context)
return {
"answer": "当前知识库没有足够信息支持可靠回答。",
"reason": grade["reason"],
}
3.5 校正的工程注意事项
- 最多补救一到两轮:无限循环会导致成本失控,也不一定提高质量。
- 记录失败样本:
incorrect和二次ambiguous是最有价值的索引优化数据。 - 不要让评估器过度乐观:Prompt 中要强调“不足以支持答案就判 ambiguous 或 incorrect”。
- 区分无答案和检索失败:无答案可能是知识库缺失,也可能是切分、索引或 Query 表达问题。
- 高风险答案必须引用证据:没有证据片段支持的结论,不应输出成确定事实。
- 把校正结果用于反哺系统:高频失败 Query 应进入知识库补充、Chunk 重切分、索引策略调整或检索 Prompt 优化流程。
4. 推荐组合方案
不同规模和质量要求的 RAG 系统,可以按下面的顺序逐步增强。
方案一:低成本增强版
适合内部知识库、FAQ、技术文档助手。
Dense 检索 Top-30
-> BM25 检索 Top-30
-> RRF 融合 Top-20
-> Cross-Encoder 重排 Top-8
-> 句子级抽取
-> 生成答案
优点是工程复杂度可控,效果提升明显。大多数 RAG 系统可以先做到这一步。
方案二:高准确率版本
适合客服、售后、法务、医疗辅助等容错率较低的场景。
查询改写
-> 混合检索
-> RRF 融合
-> Cross-Encoder 重排
-> LLM 上下文压缩
-> 检索质量评估
-> C-RAG 分流补救
-> 带引用生成
这个方案成本更高,但能显著减少“检索错了还硬答”的问题。
方案三:复杂问题专家版
适合多跳问答、复杂决策、研究型检索。
查询拆分 / Step-Back / HyDE
-> 多路检索
-> RRF
-> ColBERT 或 Cross-Encoder
-> RankLLM 列表级重排
-> 压缩
-> 校正
-> 分步生成答案
这个方案适合高价值请求,不建议作为所有请求的默认链路。
5. 评估指标
高级检索技巧是否有效,必须靠评估集验证。建议至少准备 50 到 200 条真实问题,每条问题标注:
- 应该命中的文档或 Chunk。
- 标准答案或关键事实点。
- 是否允许回答“不知道”。
- 是否要求引用来源。
常用指标:
| 指标 | 说明 | 用于评估 |
|---|---|---|
| Recall@K | 正确文档是否出现在 Top-K 中 | 召回阶段 |
| MRR | 第一个正确文档排得是否靠前 | 排序阶段 |
| nDCG | 多个相关文档的整体排序质量 | 重排序阶段 |
| Faithfulness | 答案是否被上下文支持 | 生成阶段 |
| Answer Correctness | 答案是否正确完整 | 端到端效果 |
| Refusal Accuracy | 无答案时是否正确拒答 | 校正阶段 |
| Token Cost | 平均输入/输出 Token 成本 | 压缩阶段 |
| Latency P95 | 95 分位延迟 | 工程性能 |
小结
- 重排序负责把最相关的文档排到前面。RRF 适合融合粗排,Cross-Encoder 适合精排,ColBERT 适合细粒度检索,RankLLM 适合高价值复杂排序。
- 压缩负责减少上下文噪音。优先使用文档过滤和句子抽取,高风险场景谨慎使用生成式摘要。
- 校正负责判断检索是否可靠。C-RAG 的关键不是让模型更会回答,而是让系统知道什么时候该补检、重检或拒答。
- 生产级 RAG 的核心不是堆更多模型,而是建立一条可评估、可降级、可观测的检索后处理链路。
参考资料
- Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
- Zero-Shot Listwise Document Reranking with a Large Language Model
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
- Corrective Retrieval Augmented Generation