
并发集合
大约 3 分钟
并发集合
集合对比
三种集合:
- HashMap 是线程不安全的,性能好
- Hashtable 线程安全基于 synchronized,综合性能差,已经被淘汰
- ConcurrentHashMap 保证了线程安全,综合性能较好,不止线程安全,而且效率高,性能好
集合对比:
- Hashtable 继承 Dictionary 类,HashMap、ConcurrentHashMap 继承 AbstractMap,均实现 Map 接口
- Hashtable 底层是数组 + 链表,JDK8 以后 HashMap 和 ConcurrentHashMap 底层是数组 + 链表 + 红黑树
- HashMap 线程非安全,Hashtable 线程安全,Hashtable 的方法都加了 synchronized 关来确保线程同步
- ConcurrentHashMap、Hashtable 不允许 null 值,HashMap 允许 null 值
- ConcurrentHashMap、HashMap 的初始容量为 16,Hashtable 初始容量为11,填充因子默认都是 0.75,两种 Map 扩容是当前容量翻倍:capacity 2,Hashtable 扩容时是容量翻倍 + 1:capacity2 + 1
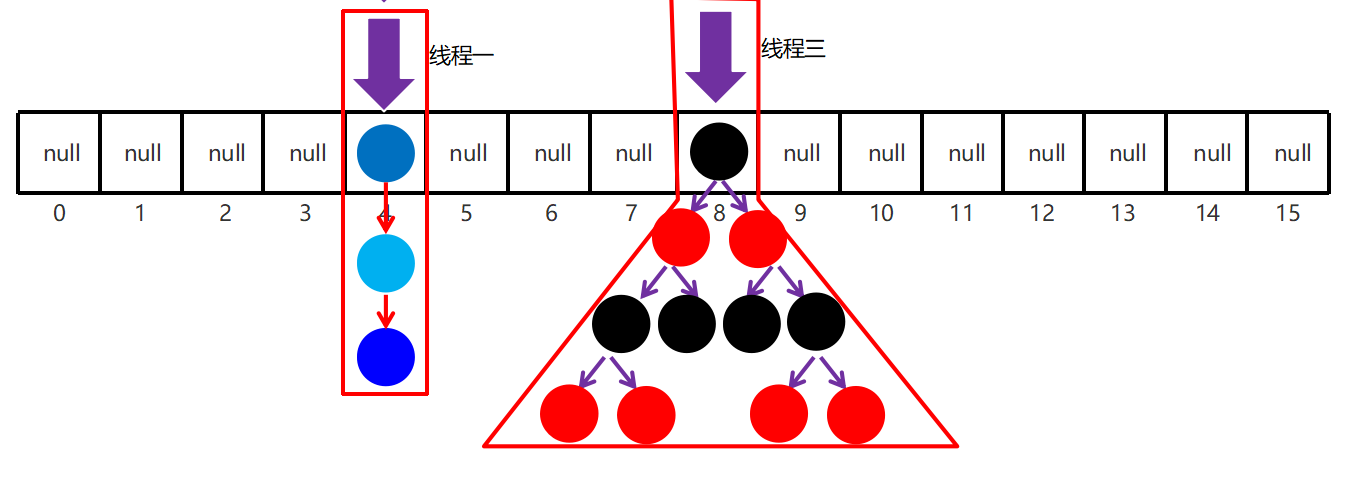
工作步骤:
- 初始化,使用 cas 来保证并发安全,懒惰初始化 table
- 树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头 说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁
- put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
- get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
- 扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容
- size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
//需求:多个线程同时往HashMap容器中存入数据会出现安全问题
public class ConcurrentHashMapDemo{
public static Map\<String,String\> map = new ConcurrentHashMap();
public static void main(String[] args){
new AddMapDataThread().start();
new AddMapDataThread().start();
Thread.sleep(1000 * 5);//休息5秒,确保两个线程执行完毕
System.out.println("Map大小:" + map.size());//20万
}
}
public class AddMapDataThread extends Thread{
@Override
public void run() {
for(int i = 0 ; i < 1000000 ; i++ ){
ConcurrentHashMapDemo.map.put("键:"+i , "值"+i);
}
}
}
并发死链
JDK1.7 的 HashMap 采用的头插法(拉链法)进行节点的添加,HashMap 的扩容长度为原来的 2 倍
resize() 中节点(Entry)转移的源代码:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;//得到新数组的长度
// 遍历整个数组对应下标下的链表,e代表一个节点
for (Entry\<K,V\> e : table) {
// 当e == null时,则该链表遍历完了,继续遍历下一数组下标的链表
while(null != e) {
// 先把e节点的下一节点存起来
Entry\<K,V\> next = e.next;
if (rehash) { //得到新的hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
// 在新数组下得到新的数组下标
int i = indexFor(e.hash, newCapacity);
// 将e的next指针指向新数组下标的位置
e.next = newTable[i];
// 将该数组下标的节点变为e节点
newTable[i] = e;
// 遍历链表的下一节点
e = next;
}
}
}
JDK 8 虽然将扩容算法做了调整,改用了尾插法,但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
B站视频解析:https://www.bilibili.com/video/BV1n541177Ea