GC
GC
垃圾判别算法
判断一个对象是否是一个垃圾的算法
引用计数算法:对于一个对象A,只要任何一个对象引用了A,那么的A的引用计数器则+1,当引用失效时,引用计数器-1。如果A的引用计数器=0了,则表示对象A不可能再被使用,可进行回收。
优点:实现简单,垃圾对象便于辨识;判断效率高,回收没有延迟性
缺点:
- 需要单独的字段存储计数器,增加了内存开销
- 每次赋值都需要更新计数器,需要加减法操作,增加了时间开销
- 无法处理循环引用,致命缺陷,Java的垃圾回收器没有使用这个算法
可达性分析算法(GC Root 根搜索算法):以根对象集合为起始点,按照从上至下的方法搜索被根对象集合所连接的目标对象是否可达。使用可达性分析算法后,内存中的存活对象都会被根对象集合直接或间接连接,搜索所走过的路径称为引用链。如果目标对象没有任何引用链相连,则是不可达标记为垃圾对象。只有能够被根集合直接或者间接连接的对象才是存活对象。
优点:实现简单,执行高效,有效的解决循环引用的问题,防止内存泄露。
GC Roots:
- 虚拟机栈中引用的对象:各个线程被调用的方法中使用到的参数、局部变量等。
- 本地方法栈内JNI (通常说的本地方法)引用的对象
- 类静态属性引用的对象:比如: Java类的引用类型静态变量
- 方法区中常量引用的对象:字符串常量池(String Table)里的引用
- 所有被同步锁synchronized持有的对象
- Java虚拟机内部的引用:基本数据类型对应的Class对象,一些常驻的异常对象( 如: NullPointerException、OutOfMemoryError),系统加载类
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
- 除了这些固定的GCRoots集合以外,根据用户所选用的垃圾收集器以及当前回收的内存区域不同,还可以有其他对象“临时性”地加入,共同构成完整GC Roots集合。比如:分代收集和局部回收(Partial GC)
可达性分析算法必须在一个能保证一致性的快照中进行,因为你的一个对象当前可能是可达的,但是下一秒可能不可达,所以判断必须是某一个快照时刻去判断,现在的虚拟机常用的是可达性分析算法。
垃圾清除算法
当一个对象被判别为一个垃圾对象,如何清除的算法
标记-清除算法(Mark-Sweep)
- 过程:首先标记所有需要回收的对象,然后统一回收
- 优点:实现简单
- 缺点:效率低,会产生大量内存碎片
标记-整理算法(Mark-Compact)
- 过程:标记后将存活对象向一端移动,然后清理边界以外的内存
- 优点:不会产生内存碎片
- 缺点:移动对象需要更新引用,效率较低
复制算法(Copying)
- 过程:将内存分为两块,只使用一块,当这块用完时,将存活对象复制到另一块
- 优点:高效,不会产生内存碎片
- 缺点:可用内存减少为原来的一半
分代收集算法(Generational Collection)
- 过程:根据对象存活周期,将内存划分为不同的区域,根据各个区域特点使用不同算法
- 优点:结合各种算法优点,提高回收效率
- 缺点:实现复杂
垃圾回收器
1. Serial/Serial Old 回收器
- 执行过程:
- 新生代回收时,Eden区满触发Minor GC
- 单线程执行,完全暂停应用线程(STW)
- 老年代回收时,单线程执行Full GC
- 优缺点:
- 优点: 简单高效,单线程无线程切换开销
- 缺点: 停顿时间长,不适合多核处理器
2. Parallel/Parallel Old 回收器
- 执行过程:
- 新生代回收时,多线程并行执行垃圾回收
- 应用线程仍然完全暂停(STW)
- 注重吞吐量,可通过参数控制最大停顿时间和吞吐量
- 优缺点:
- 优点: 充分利用多核CPU,提高吞吐量
- 缺点: 仍有较长停顿时间,不适合需要低延迟的应用
配置参数
-XX:MaxGCpauseMillis,设置垃圾收集器最大停顿时间(即STW的时间),单位是毫秒
-XX:GCTimeRation,垃圾收集时间占总时间的比例( = 1 / (N + 1)),用于衡量的大小,取值范围(0,100),默认99,垃圾回收时间不超过1%
-XX:+UseAdaptiveSizePolicy,设置Parallel Scavenge收集器具有自适应调节策略
3. CMS 回收器
- 执行过程:
- 初始标记(STW): 仅标记GC Roots能直接关联的对象
- 并发标记: 与用户线程并发执行,进行GC Roots追踪
- 重新标记(STW): 修正并发标记期间用户线程导致的变动
- 并发清除: 与用户线程并发执行,清除垃圾对象
- 优缺点:
- 优点: 并发收集,低停顿
- 缺点:
- CPU资源敏感
- 无法处理浮动垃圾
- 会产生内存碎片
4. G1 回收器
特点:
- 应用于新生代和老年代,在JDK9之后默认使用G1
- 划分成多个区域,每个区域都可以充当eden,survivor,old,humongous,其中humongous专为大对象准备
- 采用复制算法
- 响应时间与吞吐量兼顾
- 分成三个阶段:新生代回收(stw)、并发标记(重新标记stw)、混合收集
- 如果并发失败(即回收速度赶不上创建新对象速度),会触发 FullGC
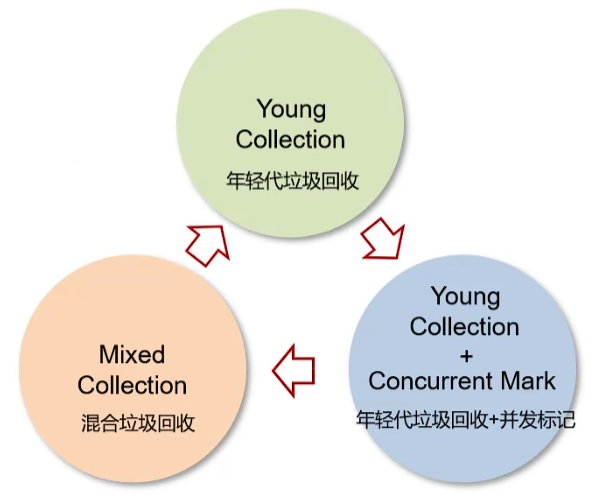
执行过程:
- 初始标记(STW): 标记GC Roots直接关联对象
- 并发标记: 与用户线程并发执行
- 最终标记(STW): 处理并发阶段遗留的标记
- 筛选回收(STW): 对各个Region的回收价值排序,选择回收收益最大的Region
优缺点:
- 优点:
- 可预测的停顿时间模型
- 区域化分配与回收
- 空间整合,不会产生大量碎片
- 缺点:
- 内存占用和额外执行负载比CMS高
- 优点:
总结
- 分代假设驱动堆划分
传统垃圾回收器(如Serial、Parallel Scavenge、CMS)基于分代假设(Generational Hypothesis)设计:
年轻代:对象生命周期短(朝生夕死),适合复制算法(如Eden + Survivor区)。
老年代:对象存活时间长,适合标记-清除或标记-整理算法。
堆的分代划分(Eden/Survivor/老年代)直接服务于分代回收策略,不同代区使用不同的回收算法。
| 回收器 | 算法 | 堆结构 | 分代模型 | 并发/并行 | 特点 |
|---|---|---|---|---|---|
| Serial | - 年轻代:标记-复制 - 老年代:标记-整理 | 固定分代: 年轻代(Eden + 2 Survivor) + 老年代 | 物理分代 | 单线程(STW) | 简单高效,适用于客户端或小内存场景,单CPU环境下的Client模式 |
| Parallel Scavenge | - 年轻代:并行标记-复制 - 老年代:并行标记-整理 | 固定分代: 年轻代(Eden + 2 Survivor) + 老年代 | 物理分代 | 多线程并行(STW) | 吞吐量优先,适合后台计算密集型而不需要太多交互的任务 |
| CMS | - 年轻代:并行标记-复制(ParNew) - 老年代:并发标记-清除 | 固定分代: 年轻代(Eden + 2 Survivor) + 老年代 | 物理分代 | 并发标记(部分阶段并发) | 低停顿老年代回收,但存在内存碎片和并发模式失败风险,集中在互联网站或B/S系统服务端上的Java应用 |
- 非分代堆结构
现代垃圾回收器(如G1、ZGC、Shenandoah)采用区域化堆设计,打破了传统分代模型的物理界限:
- G1(Garbage-First):将堆划分为多个等大小Region(通常2MB~32MB),逻辑上仍分年轻代(Eden/Survivor Region)和老年代(Old Region),但物理上不固定。
- ZGC/Shenandoah:彻底抛弃分代概念,将堆视为连续的内存块,通过着色指针或读屏障实现并发标记-整理。
| 回收器 | 算法 | 堆结构 | 分代模型 | 并发/并行 | 特点 |
|---|---|---|---|---|---|
| G1 (Garbage-First) | - 分Region标记-整理 - 并发标记 + 增量回收 | 动态分区: 堆划分为多个等大小Region(2MB~32MB),逻辑分代(Eden/Survivor/Old) | 逻辑分代 | 并发标记 + 并行回收 | 平衡吞吐与延迟,可预测停顿时间,适合大堆内存,面向服务端应用,将来替换CMS |
| ZGC | - 并发标记-整理 - 基于染色指针(Colored Pointers)和读屏障 | 连续堆内存,无物理分代 | 无分代 | 全阶段并发 | 亚毫秒级停顿,适合超大堆(TB级),但需更高内存开销,适合大内存低延迟应用 |
| Shenandoah | - 并发标记-整理 - 基于转发指针(Brooks Pointer)和读屏障 | 连续堆内存,无物理分代 | 无分代 | 全阶段并发 | 类似ZGC,但通过转发指针减少内存占用,适合中等规模堆。 |
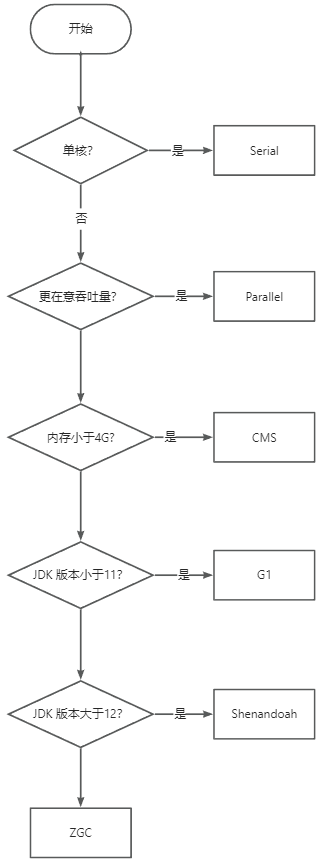
项目中如何选择垃圾回收器:
- 根据机器情况判断,如果是单核机器,或者内存较小的机器,则选择Serial GC。
- 根据业务类型判断,看你的应用更在意的是吞吐量还是 STW 的时长。比如批处理任务的应用,更在意的就是吞吐量,而实时交易系统,更在意的就是 STW 的时长。
- 根据机器分配的堆内存大小进行判断,一把来说,我们认为至少达到4G 以上才可以用 G1、ZGC 等,通常要比如超过8G、16G 这样效果才更好。
- 根据 JDK 版本进行判断,不同的版本支持的垃圾收集器不一样。
GC评估指标:
- 吞吐量:程序的运行时间(程序的运行时间十内存回收的时间)
- 暂停时间(响应时间):执行垃圾收集时,程序的工作线程被暂停的时间
- 垃圾收集开销:吞吐量的补数,垃圾收集器所占时间与总时间的比例。
- 收集频率:相对于应用程序的执行,收集操作发生的频率。
- 内存占用:Java堆区所占的内存大小。
- 快速:一个对象从诞生到被回收所经历的时间。
可以参考以下的选择方式(但是,并不绝对,尤其是 ZGC 和Shenandoah GC 的选择,其实还是要慎重,毕竟他们的稳定性各方面还有待验证):
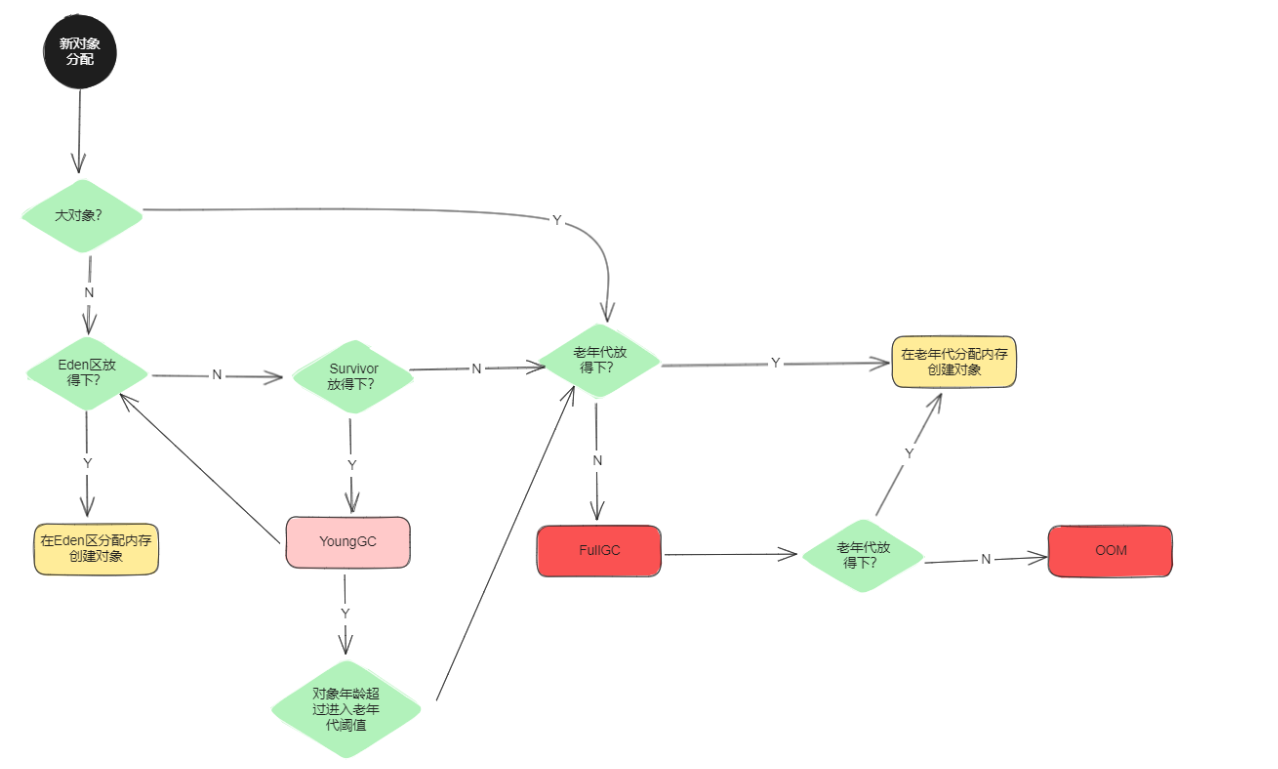
一次完整的GC流程大致如下,基于JDK1.8