
IO流
IO
Java IO(输入/输出)是指用于读取和写入数据的API,包括处理文件、网络连接、内部存储等。Java IO API 提供了广泛的类和接口来处理不同类型的输入输出操作。
1、文件
File 类
java.io.File,使用该类的构造函数就可以创建文件对象,将硬盘中的一个具体的文件以 Java 对象的形式来表示。
| 方法 | 描述 |
|---|---|
| public File(String pathname) | 根据路径创建对象 |
| public String getName() | 获取文件名 |
| public String getParent() | 获取文件所在的目录 |
| public File getParentFile() | 获取文件所在目录对应的File对象 |
| public String getPath() | 获取文件路径 |
| public boolean exists() | 判断文件是否存在 |
| public boolean isDirectory() | 判断对象是否为目录 |
| public boolean isFile() | 判断对象是否为文件 |
| public long length() | 获取文件的大小 |
| public boolean createNewFile() | 根据当前对象创建新文件 |
| public boolean delete() | 删除对象 |
| public boolean mkdir() | 根据当前对象创建目录 |
| public boolean renameTo(File file) | 为已存在的对象重命名 |
IO
Input 输入流(将外部文件读入到 Java 程序中)
Output 输出流(将 Java 程序中的数据输出到外部)

Java 中的流有很多种不同的分类。
- 按照方向分,
输入流和输出流 - 按照单位分,可以分为
字节流和字符流(字节流是指每次处理数据以字节为单位,字符流是指每次处理数据以字符为单位) - 按照功能分,可以分为
节点流和处理流。
方法定义时的异常如果直接继承自 Exception,实际调用的时候需要手动处理(捕获异常/丢给虚拟机去处理)
方法定义时的异常如果继承自 RuntimeException,调用的时候不需要处理。
2、IO流
- 按照方向分,可以分为输入流和输出流。
- 按照单位分,可以分为字节流和字符流。
- 按照功能分,可以分为节点流和处理流。
3、字节流
按照方向可以分为输入字节流和输出字节流。
InputStream、OutputStream
1 byte = 8 位二进制数 01010101
InputStream常用方法
| 方法 | 描述 |
|---|---|
| int read() | 以字节为单位读取数据 |
| int read(byte b[]) | 将数据存入 byte 类型的数组中,返回数组中有效数据的长度 |
| int read(byte b[],int off,int len) | 将数据存入 byte 数组的指定区间内,返回数组长度 |
| byte[] readAllBytes() | 将所有数据存入 byte 数组并返回 |
| int available() | 返回当前数据流未读取的数据个数 |
| void close() | 关闭数据流 |
OutputStream
| 方法 | 描述 |
|---|---|
| void write(int b) | 以字节为单位输出数据 |
| void write(byte b[]) | 将byte数组中的数据输出 |
| void write(byte b[],int off,int len) | 将byte数组中指定区间的数据输出 |
| void close() | 关闭数据流 |
| void flush() | 将缓冲流中的数据同步到输出流中 |
4、字符流
字节流是单位时间内处理一个字节的数据(输入+输出)
字符流是单位时间内处理一个字符的数据(输入+输出)
字符流:
- 输入字符流 Reader
- 输出字符流 Writer
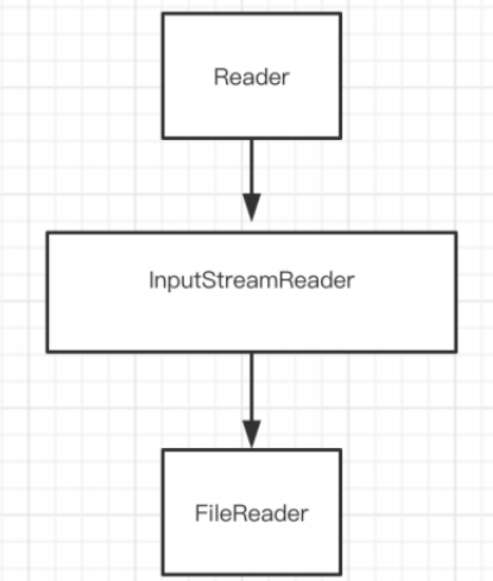
5、Reader

是一个抽象类
Readable 接口的作用?
可以将数据以字符的形式读入到缓冲区
- 方向:输入+输出
- 单位:字节+字符
- 功能:节点流(字节流) + 处理流(对节点流进行处理,生成其他类型的流)
InputStream(字节输入流) —> Reader(字符输入流)
InputStreamReader 的功能是将字节输入流转换为字符输入流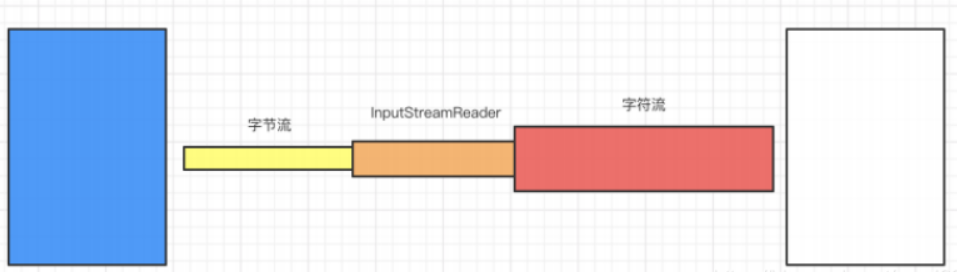
英文、数字、符号
1 个字节 = 1 个字符
如:a 1 个字符、1 个字节
汉字
1 个字符 = 3 个字节
如:好 1个字符、3 个字节
public class Test {
public static void main(String[] args) throws Exception {
//字符流
Reader reader = new FileReader("/Users/du/Desktop/test.txt");
int temp = 0;
System.out.println("*******字符流读取********");
while ((temp = reader.read())!=-1){
System.out.println(temp);
}
reader.close();
//字节流
InputStream inputStream = new FileInputStream("/Users/du/Desktop/test.txt");
temp = 0;
System.out.println("*******字节流读取********");
while ((temp = inputStream.read())!=-1){
System.out.println(temp);
}
inputStream.close();
}
}
read() 返回的是 int ,直接将字符转成字节(1-1,1-3)
read(char[] chars) 返回的是char数组,直接就返回字符,不会转成字节的。
6、Writer

Appendable 接口可以将 char 类型的数据读入到数据缓冲区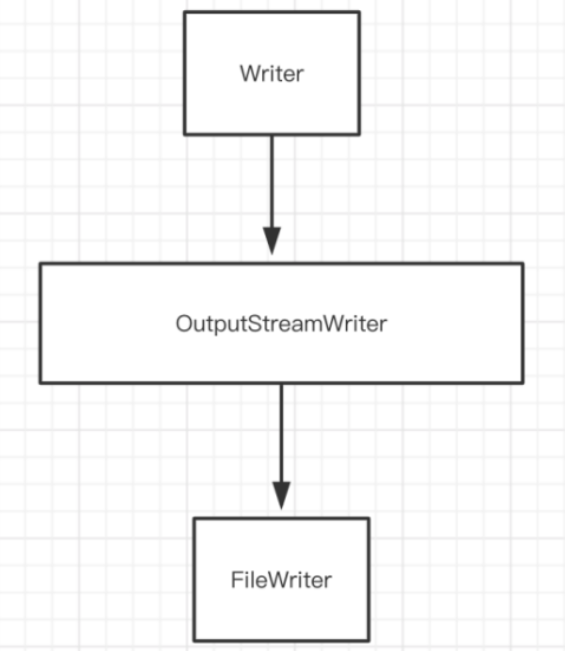
OutputStreamWriter 处理流
OutputStreamWriter 的功能是将输出字节流转成输出字符流,与 InputStreamReader 相对应的,将输入字节流转成输入字符流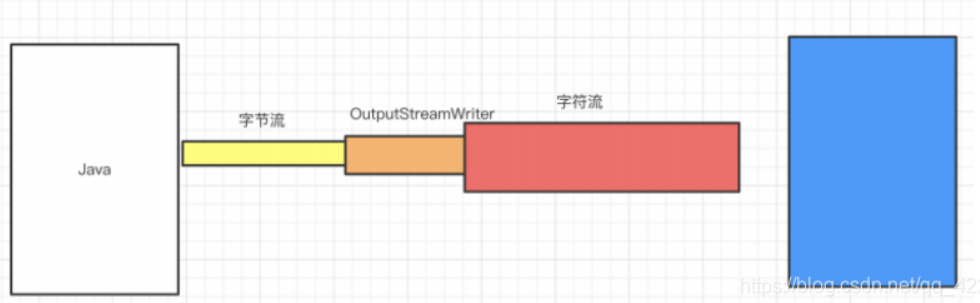
public class Test {
public static void main(String[] args) throws Exception {
Writer writer = new FileWriter("/Users/du/Desktop/copy.txt");
//writer.write("你好");
// char[] chars = {'你','好','世','界'};
// writer.write(chars,2,2);
String str = "Hello World,你好世界";
writer.write(str,10,6);
writer.flush();
writer.close();
}
}
7、处理
1、读文件
public class Test {
public static void main(String[] args) throws Exception {
//基础管道
InputStream inputStream = new FileInputStream("/Users/du/Desktop/test.txt");
//处理流
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
char[] chars = new char[1024];
int length = inputStreamReader.read(chars);
inputStreamReader.close();
String result = new String(chars,0,length);
System.out.println(result);
}
}
2、写文件
public class Test2 {
public static void main(String[] args) throws Exception {
String str = "你好 世界";
OutputStream outputStream = new FileOutputStream("/Users/du/Desktop/copy.txt");
OutputStreamWriter writer = new OutputStreamWriter(outputStream);
writer.write(str,2,1);
writer.flush();
writer.close();
}
}
8、缓冲流
无论是字节流还是字符流,使用的时候都会频繁访问硬盘,对硬盘是一种损伤,同时效率不高,如何解决?
可以使用缓冲流,缓冲流自带缓冲区,可以一次性从硬盘中读取部分数据存入缓冲区,再写入内存,这样就可以有效减少对硬盘的直接访问。
缓冲流属于处理流,如何来区分节点流和处理流?
1、节点流使用的时候可以直接对接到文件对象File
2、处理流使用的时候不可以直接对接到文件对象 File,必须要建立在字节流的基础上才能创建。

缓冲流又可以分为字节缓冲流和字符缓冲流,按照方向再细分,又可以分为字节输入缓冲流和字节输出缓冲流,以及字符输入缓冲流和字符输出缓冲流。
字节输入缓冲流
public class Test {
public static void main(String[] args) throws Exception {
//1、创建节点流
InputStream inputStream = new FileInputStream("/Users/du/Desktop/test.txt");
//2、创建缓冲流
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
// int temp = 0;
// while ((temp = bufferedInputStream.read())!=-1){
// System.out.println(temp);
// }
byte[] bytes = new byte[1024];
int length = bufferedInputStream.read(bytes,10,10);
System.out.println(length);
for (byte aByte : bytes) {
System.out.println(aByte);
}
bufferedInputStream.close();
inputStream.close();
}
}
字符输入缓冲流
readLine 方法
public class Test2 {
public static void main(String[] args) throws Exception {
//1、创建字符流(节点流)
Reader reader = new FileReader("/Users/du/Desktop/test.txt");
//2、创建缓冲流(处理流)
BufferedReader bufferedReader = new BufferedReader(reader);
String str = null;
int num = 0;
System.out.println("***start***");
while ((str = bufferedReader.readLine())!=null){
System.out.println(str);
num++;
}
System.out.println("***end***,共读取了"+num+"次");
bufferedReader.close();
reader.close();
}
}
字节输出缓冲流
public class Test {
public static void main(String[] args) throws Exception {
OutputStream outputStream = new FileOutputStream("/Users/du/Desktop/test2.txt");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(outputStream);
String str = "由于在开发Oak语言时,尚且不存在运行字节码的硬件平台,所以为了在开发时可以对这种语言进行实验研究,他们就在已有的硬件和软件平台基础上,按照自己所指定的规范,用软件建设了一个运行平台,整个系统除了比C++更加简单之外,没有什么大的区别。";
byte[] bytes = str.getBytes();
// for (byte aByte : bytes) {
// bufferedOutputStream.write(aByte);
// }
bufferedOutputStream.write(bytes,9,9);
bufferedOutputStream.flush();
bufferedOutputStream.close();
outputStream.close();
}
}
字符输出缓冲流
public class Test2 {
public static void main(String[] args) throws Exception {
Writer writer = new FileWriter("/Users/du/Desktop/test2.txt");
BufferedWriter bufferedWriter = new BufferedWriter(writer);
// String str = "由于在开发语言时尚且不存在运行字节码的硬件平台,所以为了在开发时可以对这种语言进行实验研究,他们就在已有的硬件和软件平台基础上,按照自己所指定的规范,用软件建设了一个运行平台,整个系统除了比C++更加简单之外,没有什么大的区别。";
// bufferedWriter.write(str,5,10);
char[] chars = {'J','a','v','a'};
// bufferedWriter.write(chars,2,1);
bufferedWriter.write(22902);
bufferedWriter.flush();
bufferedWriter.close();
writer.close();
}
}
输入流没有 flush 方法,但不代表它没有缓冲流,输出流是有 flush 方法的,实际开发中在关闭输出缓冲流之前,需要调用 flush 方法。
9、序列化和反序列化
序列化就是将内存中的对象输出到硬盘文件中保存。
反序列化就是相反的操作,从文件中读取数据并还原成内存中的对象。
序列化
1、实体类需要实现序列化接口,Serializable
public class User implements Serializable {
private Integer id;
private String name;
private Integer age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
public User(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
}
2、实体类对象进行序列化处理,通过数据流写入到文件中,ObjectOutputStream。
package com.du.demo3;
import com.du.entity.User;
import java.io.File;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
public class Test {
public static void main(String[] args) throws Exception {
User user = new User(1,"张三",22);
OutputStream outputStream = new FileOutputStream("/Users/du/Desktop/obj.txt");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(user);
objectOutputStream.flush();
objectOutputStream.close();
outputStream.close();
}
}
反序列化
public class Test2 {
public static void main(String[] args) throws Exception {
InputStream inputStream = new FileInputStream("/Users/du/Desktop/obj.txt");
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
User user = (User) objectInputStream.readObject();
System.out.println(user);
objectInputStream.close();
inputStream.close();
}
}
10、IO 流的应用
IO 流就是完成文件传输(上传文件:发朋友圈、换头像,文件下载:CSDN 下载源代码、文档)
字符 a 你好
文本类型的数据(txt、word、Excel、MD)可以使用字符去读取(当然也可以用字节)
public class Test3 {
public static void main(String[] args) throws Exception {
Reader reader = new FileReader("/Users/du/Desktop/test.txt");
BufferedReader bufferedReader = new BufferedReader(reader);
Writer writer = new FileWriter("/Users/du/myjava/test.txt");
BufferedWriter bufferedWriter = new BufferedWriter(writer);
String str = "";
int num = 0;
while ((str = bufferedReader.readLine())!=null){
bufferedWriter.write(str);
num++;
}
System.out.println("传输完毕,共读取了"+num+"次");
bufferedWriter.flush();
bufferedWriter.close();
writer.close();
bufferedReader.close();
reader.close();
}
}
非文本类型的数据(图片、音频、视频)不能用字符去读取,只能用字节去读。
public class Test {
public static void main(String[] args) throws Exception {
//1、通过输入流将文件读入到 Java
InputStream inputStream = new FileInputStream("/Users/du/Desktop/1.png");
//2、通过输出流将文件从 Java 中写入到 myjava
OutputStream outputStream = new FileOutputStream("/Users/du/myjava/1.png");
int temp = 0;
int num = 0;
long start = System.currentTimeMillis();
while((temp = inputStream.read())!=-1){
num++;
outputStream.write(temp);
}
long end = System.currentTimeMillis();
System.out.println("传输完毕,共耗时"+(end-start));
outputStream.flush();
outputStream.close();
inputStream.close();
}
}
11、网络编程
文章
深入学习IO多路复用 select/poll/epoll 实现原理
DES
网络编程
网络编程,就是在一定的协议下,实现两台计算机的通信的技术
通信一定是基于软件结构实现的:
- C/S 结构 :全称为 Client/Server 结构,是指客户端和服务器结构,常见程序有 QQ、IDEA 等软件
- B/S 结构 :全称为 Browser/Server 结构,是指浏览器和服务器结构
两种架构各有优势,但是无论哪种架构,都离不开网络的支持
网络通信的三要素:
- 协议:计算机网络客户端与服务端通信必须约定和彼此遵守的通信规则,HTTP、FTP、TCP、UDP、SMTP
- IP 地址:互联网协议地址(Internet Protocol Address),用来给一个网络中的计算机设备做唯一的编号
IPv4:4 个字节,32 位组成,192.168.1.1
IPv6:可以实现为所有设备分配 IP,128 位
ipconfig:查看本机的 IP
ping 检查本机与某个 IP 指定的机器是否联通,或者说是检测对方是否在线。
ping 空格 IP地址 :ping 220.181.57.216,ping www.baidu.com
特殊的IP地址: 本机IP地址,127.0.0.1 == localhost,回环测试
- 端口:端口号就可以唯一标识设备中的进程(应用程序)。端口号是用两个字节表示的整数,取值范围是 0-65535,0-1023 之间的端口号用于一些知名的网络服务和应用普通的应用程序需要使用 1024 以上的端口号。如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败,报出端口被占用异常
利用协议+IP 地址+端口号三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互
参考视频:https://www.bilibili.com/video/BV1kT4y1M7vt
通信协议
网络通信协议:对计算机必须遵守的规则,只有遵守这些规则,计算机之间才能进行通信
通信是进程与进程之间的通信,不是主机与主机之间的通信
TCP/IP协议:传输控制协议 (Transmission Control Protocol)
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流,每一条 TCP 连接只能是点对点的(一对一)
- 在通信之前必须确定对方在线并且连接成功才可以通信
- 例如下载文件、浏览网页等(要求可靠传输)
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,不可靠,没有拥塞控制,面向报文,支持一对一、一对多、多对一和多对多的交互通信
- 直接发消息给对方,不管对方是否在线,发消息后也不需要确认
- 无线(视频会议,通话),性能好,可能丢失一些数据
Java模型
相关概念:
- 同步:当前线程要自己进行数据的读写操作(自己去银行取钱)
- 异步:当前线程可以去做其他事情(委托别人拿银行卡到银行取钱,然后给你)
- 阻塞:在数据没有的情况下,还是要继续等待着读(排队等待)
- 非阻塞:在数据没有的情况下,会去做其他事情,一旦有了数据再来获取(柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理)
Java 中的通信模型:
- BIO 表示同步阻塞式通信,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过线程池机制改善 同步阻塞式性能极差:大量线程,大量阻塞
- 伪异步通信:引入线程池,不需要一个客户端一个线程,实现线程复用来处理很多个客户端,线程可控 高并发下性能还是很差:线程数量少,数据依然是阻塞的,数据没有来线程还是要等待
- NIO 表示同步非阻塞 IO,服务器实现模式为请求对应一个线程,客户端发送的连接会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理 工作原理:1 个主线程专门负责接收客户端,1 个线程轮询所有的客户端,发来了数据才会开启线程处理 同步:线程还要不断的接收客户端连接,以及处理数据 非阻塞:如果一个管道没有数据,不需要等待,可以轮询下一个管道是否有数据
- AIO 表示异步非阻塞 IO,AIO 引入异步通道的概念,采用了 Proactor 模式,有效的请求才启动线程,特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用 异步:服务端线程接收到了客户端管道以后就交给底层处理 IO 通信,线程可以做其他事情 非阻塞:底层也是客户端有数据才会处理,有了数据以后处理好通知服务器应用来启动线程进行处理
各种模型应用场景:
- BIO 适用于连接数目比较小且固定的架构,该方式对服务器资源要求比较高,并发局限于应用中,程序简单
- NIO 适用于连接数目多且连接比较短(轻操作)的架构,如聊天服务器,并发局限于应用中,编程复杂,JDK 1.4 开始支持
- AIO 适用于连接数目多且连接比较长(重操作)的架构,如相册服务器,充分调用操作系统参与并发操作,JDK 1.7 开始支持
I/O
IO模型
五种模型
对于一个套接字上的输入操作,第一步是等待数据从网络中到达,当数据到达时被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区
Linux 有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
五种模型对比:
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段,非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞
同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞
异步 I/O:第二阶段应用进程不会阻塞
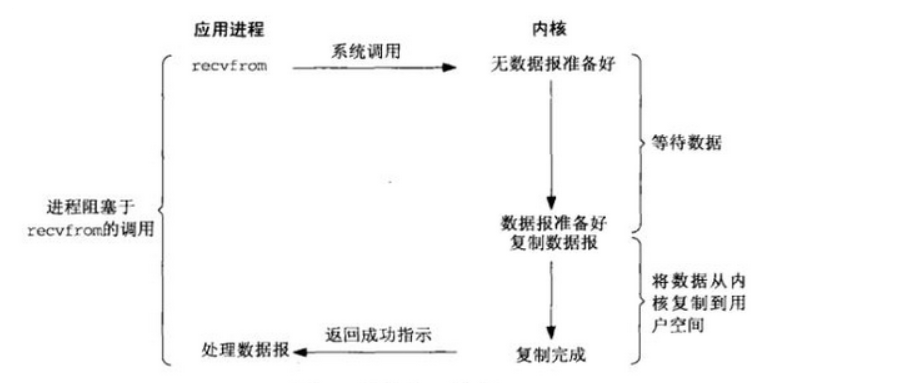
阻塞式IO
应用进程通过系统调用 recvfrom 接收数据,会被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。阻塞不意味着整个操作系统都被阻塞,其它应用进程还可以执行,只是当前阻塞进程不消耗 CPU 时间,这种模型的 CPU 利用率会比较高
recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中,把 recvfrom() 当成系统调用
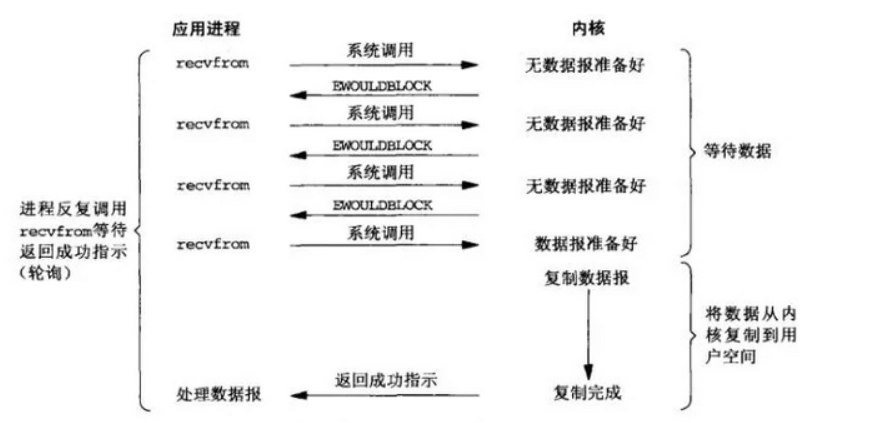
非阻塞式
应用进程通过 recvfrom 调用不停的去和内核交互,直到内核准备好数据。如果没有准备好数据,内核返回一个错误码,过一段时间应用进程再执行 recvfrom 系统调用,在两次发送请求的时间段,进程可以进行其他任务,这种方式称为轮询(polling)
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低
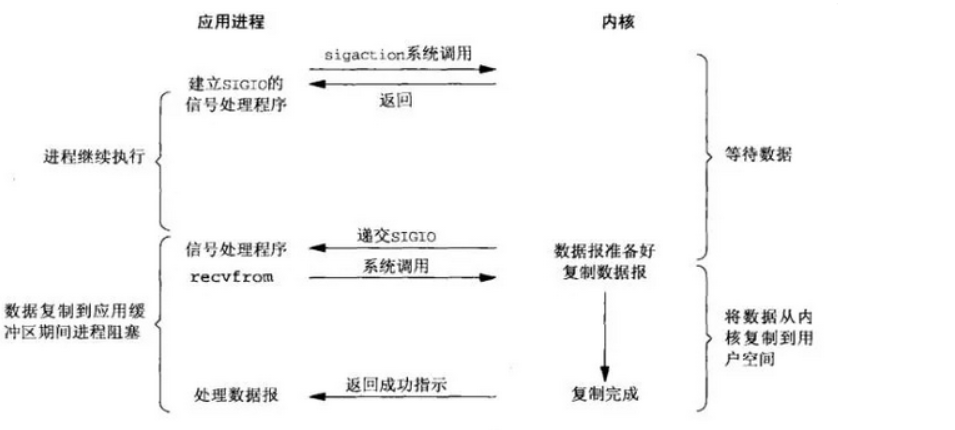
信号驱动
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,等待数据阶段应用进程是非阻塞的。当内核数据准备就绪时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高
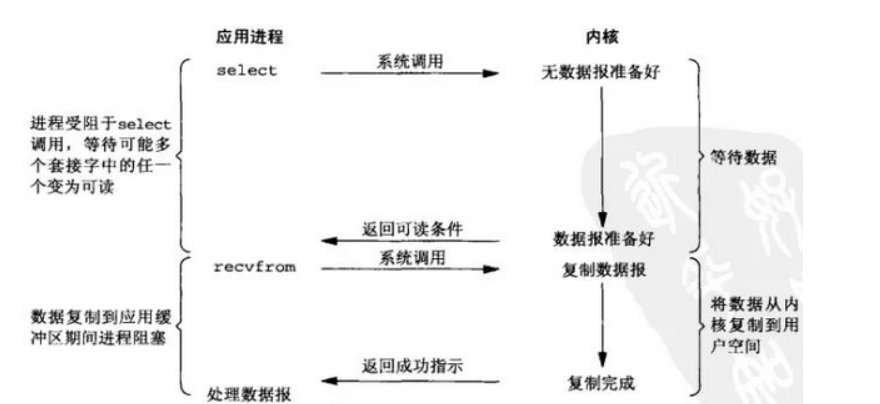
IO 复用
IO 复用模型使用 select 或者 poll 函数等待数据,select 会监听所有注册好的 IO,等待多个套接字中的任何一个变为可读,等待过程会被阻塞,当某个套接字准备好数据变为可读时 select 调用就返回,然后调用 recvfrom 把数据从内核复制到进程中
IO 复用让单个进程具有处理多个 I/O 事件的能力,又被称为 Event Driven I/O,即事件驱动 I/O
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都要创建一个线程去处理,如果同时有几万个连接,就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小
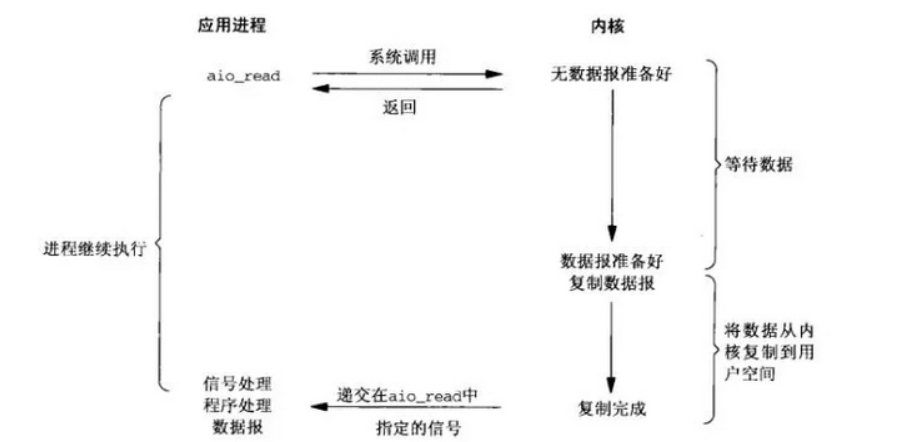
异步 IO
应用进程执行 aio_read 系统调用会立即返回,给内核传递描述符、缓冲区指针、缓冲区大小等。应用进程可以继续执行不会被阻塞,内核会在所有操作完成之后向应用进程发送信号
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O
多路复用
select
函数
Socket 不是文件,只是一个标识符,但是 Unix 操作系统把所有东西都看作是文件,所以 Socket 说成 file descriptor,也就是 fd
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- fd_set 使用 bitmap 数组实现,数组大小用 FD_SETSIZE 定义,单进程只能监听少于 FD_SETSIZE 数量的描述符,32 位机默认是 1024 个,64 位机默认是 2048,可以对进行修改,然后重新编译内核
- fd_set 有三种类型的描述符:readset、writeset、exceptset,对应读、写、异常条件的描述符集合
- n 是监测的 socket 的最大数量
- timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout
struct timeval{
long tv_sec; //秒
long tv_usec; //微秒
}
timeout == null:等待无限长的时间
tv_sec == 0 && tv_usec == 0:获取后直接返回,不阻塞等待
tv_sec != 0 || tv_usec != 0:等待指定时间
方法成功调用返回结果为就绪的文件描述符个数,出错返回结果为 -1,超时返回结果为 0
Linux 提供了一组宏为 fd_set 进行赋值操作:
int FD_ZERO(fd_set *fdset); // 将一个 fd_set 类型变量的所有值都置为 0
int FD_CLR(int fd, fd_set *fdset); // 将一个 fd_set 类型变量的 fd 位置为 0
int FD_SET(int fd, fd_set *fdset); // 将一个 fd_set 类型变量的 fd 位置为 1
int FD_ISSET(int fd, fd_set *fdset);// 判断 fd 位是否被置为 1
示例:
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof(addr)));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd, (struct sockaddr*)&addr, sizeof(addr));//绑定连接
listen(sockfd, 5);//监听5个端口
for(i = 0; i < 5; i++) {
memset(&client, e, sizeof(client));
addrlen = sizeof(client);
fds[i] = accept(sockfd, (struct sockaddr*)&client, &addrlen);
//将监听的对应的文件描述符fd存入fds:[3,4,5,6,7]
if(fds[i] > max)
max = fds[i];
}
while(1) {
FD_ZERO(&rset);//置为0
for(i = 0; i < 5; i++) {
FD_SET(fds[i], &rset);//对应位置1 [0001 1111 00.....]
}
print("round again");
select(max + 1, &rset, NULL, NULL, NULL);//监听
for(i = 0; i <5; i++) {
if(FD_ISSET(fds[i], &rset)) {//判断监听哪一个端口
memset(buffer, 0, MAXBUF);
read(fds[i], buffer, MAXBUF);//进入内核态读数据
print(buffer);
}
}
}
参考视频:https://www.bilibili.com/video/BV19D4y1o797
流程
select 调用流程图:

- 使用 copy_from_user 从用户空间拷贝 fd_set 到内核空间,进程阻塞
- 注册回调函数 _pollwait
- 遍历所有 fd,调用其对应的 poll 方法判断当前请求是否准备就绪,对于 socket,这个 poll 方法是 sock_poll,sock_poll 根据情况会调用到 tcp_poll、udp_poll 或者 datagram_poll,以 tcp_poll 为例,其核心实现就是 _pollwait
- _pollwait 把 **current(调用 select 的进程)**挂到设备的等待队列,不同设备有不同的等待队列,对于 tcp_poll ,其等待队列是 sk → sk_sleep(把进程挂到等待队列中并不代表进程已经睡眠),在设备收到消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时 current 便被唤醒,进入就绪队列
- poll 方法返回时会返回一个描述读写操作是否就绪的 mask 掩码,根据这个 mask 掩码给 fd_set 赋值
- 如果遍历完所有的 fd,还没有返回一个可读写的 mask 掩码,则会调用 schedule_timeout 让 current 进程进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程,如果超过一定的超时时间(schedule_timeout)没有其他线程唤醒,则调用 select 的进程会重新被唤醒获得 CPU,进而重新遍历 fd,判断有没有就绪的 fd
- 把 fd_set 从内核空间拷贝到用户空间,阻塞进程继续执行
参考文章:https://www.cnblogs.com/anker/p/3265058.html
其他流程图:https://www.processon.com/view/link/5f62b9a6e401fd2ad7e5d6d1
poll
poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态
int poll(struct pollfd *fds, unsigned int nfds, int timeout);
poll 中的描述符是 pollfd 类型的数组,pollfd 的定义如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
select 和 poll 对比:
select 会修改描述符,而 poll 不会
select 的描述符类型使用数组实现,有描述符的限制;而 poll 使用链表实现,没有描述符数量的限制
poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高
select 和 poll 速度都比较慢,每次调用都需要将全部描述符数组 fd 从应用进程缓冲区复制到内核缓冲区,同时每次都需要在内核遍历传递进来的所有 fd ,这个开销在 fd 很多时会很大
几乎所有的系统都支持 select,但是只有比较新的系统支持 poll
select 和 poll 的时间复杂度 O(n),对 socket 进行扫描时是线性扫描,即采用轮询的方法,效率较低,因为并不知道具体是哪个 socket 具有事件,所以随着 fd 数量的增加会造成遍历速度慢的线性下降性能问题
poll 还有一个特点是水平触发,如果报告了 fd 后,没有被处理,那么下次 poll 时会再次报告该 fd
如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Socket.md
epoll
函数
epoll 使用事件的就绪通知方式,通过 epoll_ctl() 向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,一旦该 fd 就绪,内核通过 callback 回调函数将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件就绪的描述符
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epall_create:一个系统函数,函数将在内核空间内创建一个 epoll 数据结构,可以理解为 epoll 结构空间,返回值为 epoll 的文件描述符编号,以后有 client 连接时,向该 epoll 结构中添加监听,所以 epoll 使用一个文件描述符管理多个描述符
epall_ctl:epoll 的事件注册函数,select 函数是调用时指定需要监听的描述符和事件,epoll 先将用户感兴趣的描述符事件注册到 epoll 空间。此函数是非阻塞函数,用来增删改 epoll 空间内的描述符,参数解释:
epfd:epoll 结构的进程 fd 编号,函数将依靠该编号找到对应的 epoll 结构
op:表示当前请求类型,有三个宏定义:
EPOLL_CTL_ADD:注册新的 fd 到 epfd 中
EPOLL_CTL_MOD:修改已经注册的 fd 的监听事件
EPOLL_CTI_DEL:从 epfd 中删除一个 fd
fd:需要监听的文件描述符,一般指 socket_fd
event:告诉内核对该 fd 资源感兴趣的事件,epoll_event 的结构:
struct epoll_event {
_uint32_t events; /*epoll events*/
epoll_data_t data; /*user data variable*/
}
events 可以是以下几个宏集合:EPOLLIN、EPOLOUT、EPOLLPRI、EPOLLERR、EPOLLHUP(挂断)、EPOLET(边缘触发)、EPOLLONESHOT(只监听一次,事件触发后自动清除该 fd,从 epoll 列表)
epoll_wait:等待事件的产生,类似于 select() 调用,返回值为本次就绪的 fd 个数,直接从就绪链表获取,时间复杂度 O(1)
epfd:指定感兴趣的 epoll 事件列表
events:指向一个 epoll_event 结构数组,当函数返回时,内核会把就绪状态的数据拷贝到该数组
maxevents:标明 epoll_event 数组最多能接收的数据量,即本次操作最多能获取多少就绪数据
timeout:单位为毫秒
0:表示立即返回,非阻塞调用
-1:阻塞调用,直到有用户感兴趣的事件就绪为止
大于 0:阻塞调用,阻塞指定时间内如果有事件就绪则提前返回,否则等待指定时间后返回
epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger):
- LT 模式:当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程,是默认的一种模式,并且同时支持 Blocking 和 No-Blocking
- ET 模式:通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高;只支持 No-Blocking,以避免由于一个 fd 的阻塞读/阻塞写操作把处理多个文件描述符的任务饥饿
// 创建 epoll 描述符,每个应用程序只需要一个,用于监控所有套接字
int pollingfd = epoll_create(0xCAFE);
if ( pollingfd < 0 )// report error
// 初始化 epoll 结构
struct epoll_event ev = { 0 };
// 将连接类实例与事件相关联,可以关联任何想要的东西
ev.data.ptr = pConnection1;
// 监视输入,并且在事件发生后不自动重新准备描述符
ev.events = EPOLLIN | EPOLLONESHOT;
// 将描述符添加到监控列表中,即使另一个线程在epoll_wait中等待,描述符将被正确添加
if ( epoll_ctl( epollfd, EPOLL_CTL_ADD, pConnection1->getSocket(), &ev) != 0 )
// report error
// 最多等待 20 个事件
struct epoll_event pevents[20];
// 等待10秒,检索20个并存入epoll_event数组
int ready = epoll_wait(pollingfd, pevents, 20, 10000);
// 检查epoll是否成功
if ( ret == -1)// report error and abort
else if ( ret == 0)// timeout; no event detected
else
{
for (int i = 0; i < ready; i+ )
{
if ( pevents[i].events & EPOLLIN )
{
// 获取连接指针
Connection * c = (Connection*) pevents[i].data.ptr;
c->handleReadEvent();
}
}
}
流程图:https://gitee.com/seazean/images/blob/master/Java/IO-epoll原理图.jpg
参考视频:https://www.bilibili.com/video/BV19D4y1o797
特点
epoll 的特点:
- epoll 仅适用于 Linux 系统
- epoll 使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表(个人理解成哑元节点)
- 没有最大描述符数量(并发连接)的限制,打开 fd 的上限远大于1024(1G 内存能监听约 10 万个端口)
- epoll 的时间复杂度 O(1),epoll 理解为 event poll,不同于忙轮询和无差别轮询,调用 epoll_wait 只是轮询就绪链表。当监听列表有设备就绪时调用回调函数,把就绪 fd 放入就绪链表中,并唤醒在 epoll_wait 中阻塞的进程,所以 epoll 实际上是事件驱动(每个事件关联上fd)的,降低了 system call 的时间复杂度
- epoll 内核中根据每个 fd 上的 callback 函数来实现,只有活跃的 socket 才会主动调用 callback,所以使用 epoll 没有前面两者的线性下降的性能问题,效率提高
- epoll 注册新的事件是注册到到内核中 epoll 句柄中,不需要每次调用 epoll_wait 时重复拷贝,对比前面两种只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,也可以利用 mmap() 文件映射内存加速与内核空间的消息传递(只是可以用,并没有用)
- 前面两者要把 current 往设备等待队列中挂一次,epoll 也只把 current 往等待队列上挂一次,但是这里的等待队列并不是设备等待队列,只是一个 epoll 内部定义的等待队列,这样可以节省开销
- epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符,也不会产生像 select 和 poll 的不确定情况
参考文章:https://www.jianshu.com/p/dfd940e7fca2
参考文章:https://www.cnblogs.com/anker/p/3265058.html
应用
应用场景:
select 应用场景:
select 的 timeout 参数精度为微秒,poll 和 epoll 为毫秒,因此 select 适用实时性要求比较高的场景,比如核反应堆的控制
select 可移植性更好,几乎被所有主流平台所支持
poll 应用场景:poll 没有最大描述符数量的限制,适用于平台支持并且对实时性要求不高的情况
epoll 应用场景:
运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接
需要同时监控小于 1000 个描述符,没必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势
需要监控的描述符状态变化多,而且是非常短暂的,就没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,每次对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率,并且 epoll 的描述符存储在内核,不容易调试
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Socket.md
系统调用
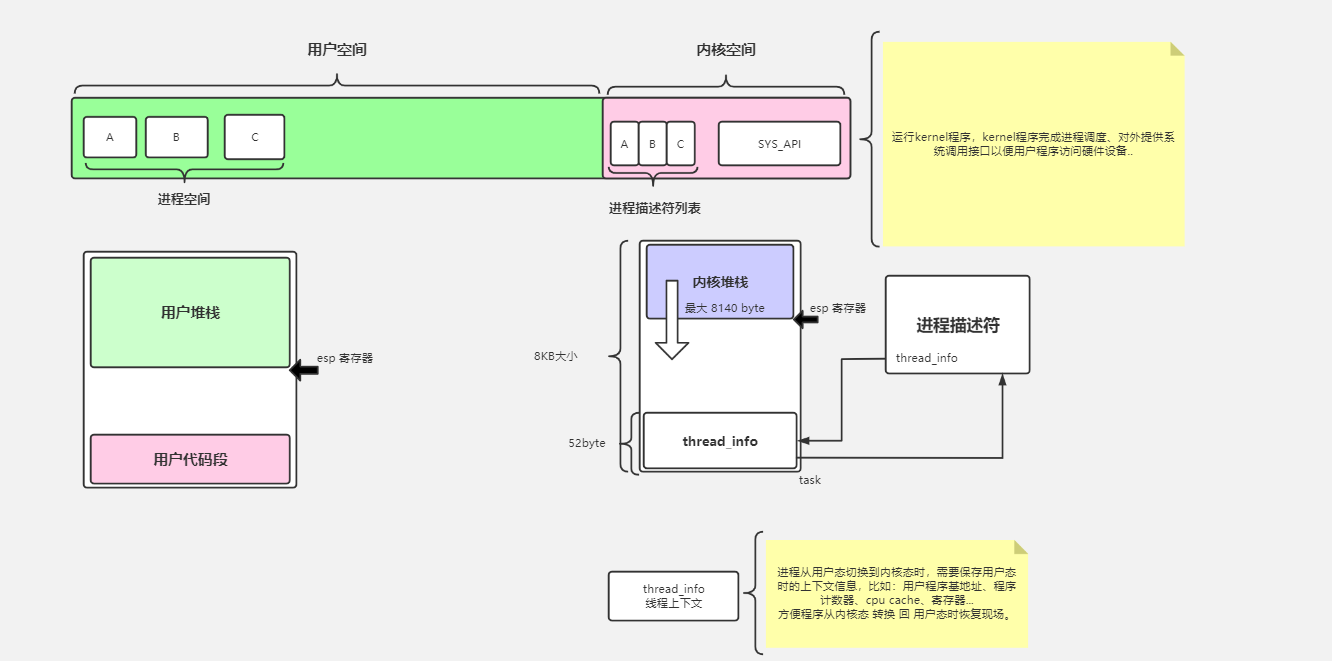
内核态
用户空间:用户代码、用户堆栈
内核空间:内核代码、内核调度程序、进程描述符(内核堆栈、thread_info 进程描述符)
- 进程描述符和用户的进程是一一对应的
- SYS_API 系统调用:如 read、write,系统调用就是 0X80 中断
- 进程描述符 pd:进程从用户态切换到内核态时,需要保存用户态时的上下文信息在 PCB 中
- 线程上下文:用户程序基地址,程序计数器、cpu cache、寄存器等,方便程序切回用户态时恢复现场
- 内核堆栈:**系统调用函数也是要创建变量的,**这些变量在内核堆栈上分配
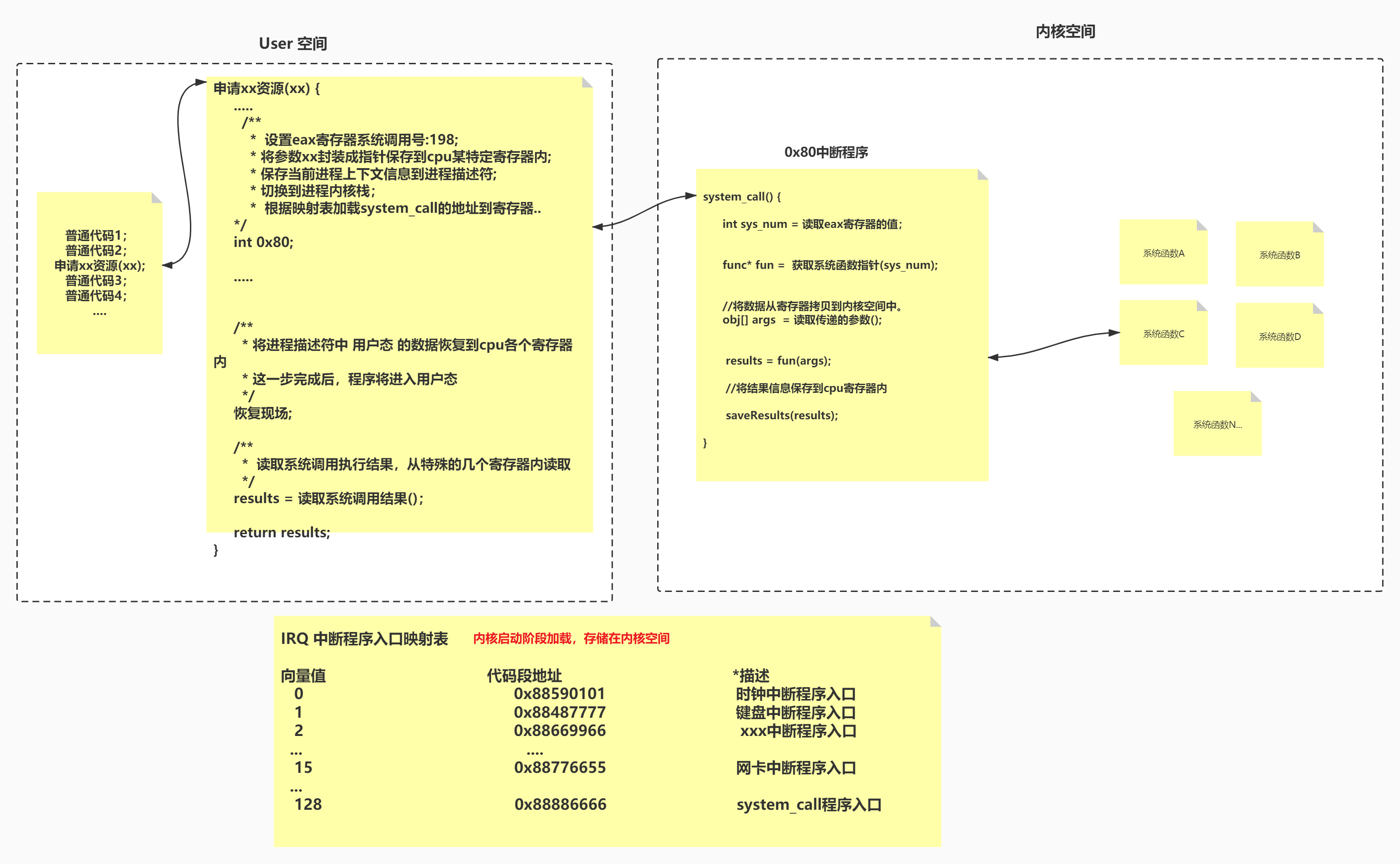
80中断
在用户程序中调用操作系统提供的核心态级别的子功能,为了系统安全需要进行用户态和内核态转换,状态的转换需要进行 CPU 中断,中断分为硬中断和软中断:
硬中断:如网络传输中,数据到达网卡后,网卡经过一系列操作后发起硬件中断
软中断:如程序运行过程中本身产生的一些中断
发起
0X80中断程序执行碰到除 0 异常
系统调用 system_call 函数所对应的中断指令编号是 0X80(十进制是 8×16=128),而该指令编号对应的就是系统调用程序的入口,所以称系统调用为 80 中断
系统调用的流程:
- 在 CPU 寄存器里存一个系统调用号,表示哪个系统函数,比如 read
- 将 CPU 的临时数据都保存到 thread_info 中
- 执行 80 中断处理程序,找到刚刚存的系统调用号(read),先检查缓存中有没有对应的数据,没有就去磁盘中加载到内核缓冲区,然后从内核缓冲区拷贝到用户空间
- 最后恢复到用户态,通过 thread_info 恢复现场,用户态继续执行
参考视频:https://www.bilibili.com/video/BV19D4y1o797
零拷贝
DMA
DMA (Direct Memory Access) :直接存储器访问,让外部设备不通过 CPU 直接与系统内存交换数据的接口技术
作用:可以解决批量数据的输入/输出问题,使数据的传送速度取决于存储器和外设的工作速度
把内存数据传输到网卡然后发送:
- 没有 DMA:CPU 读内存数据到 CPU 高速缓存,再写到网卡,这样就把 CPU 的速度拉低到和网卡一个速度
- 使用 DMA:把数据读到 Socket 内核缓存区(CPU 复制),CPU 分配给 DMA 开始异步操作,DMA 读取 Socket 缓冲区到 DMA 缓冲区,然后写到网卡。DMA 执行完后中断(就是通知) CPU,这时 Socket 内核缓冲区为空,CPU 从用户态切换到内核态,执行中断处理程序,将需要使用 Socket 缓冲区的阻塞进程移到就绪队列
一个完整的 DMA 传输过程必须经历 DMA 请求、DMA 响应、DMA 传输、DMA 结束四个步骤:
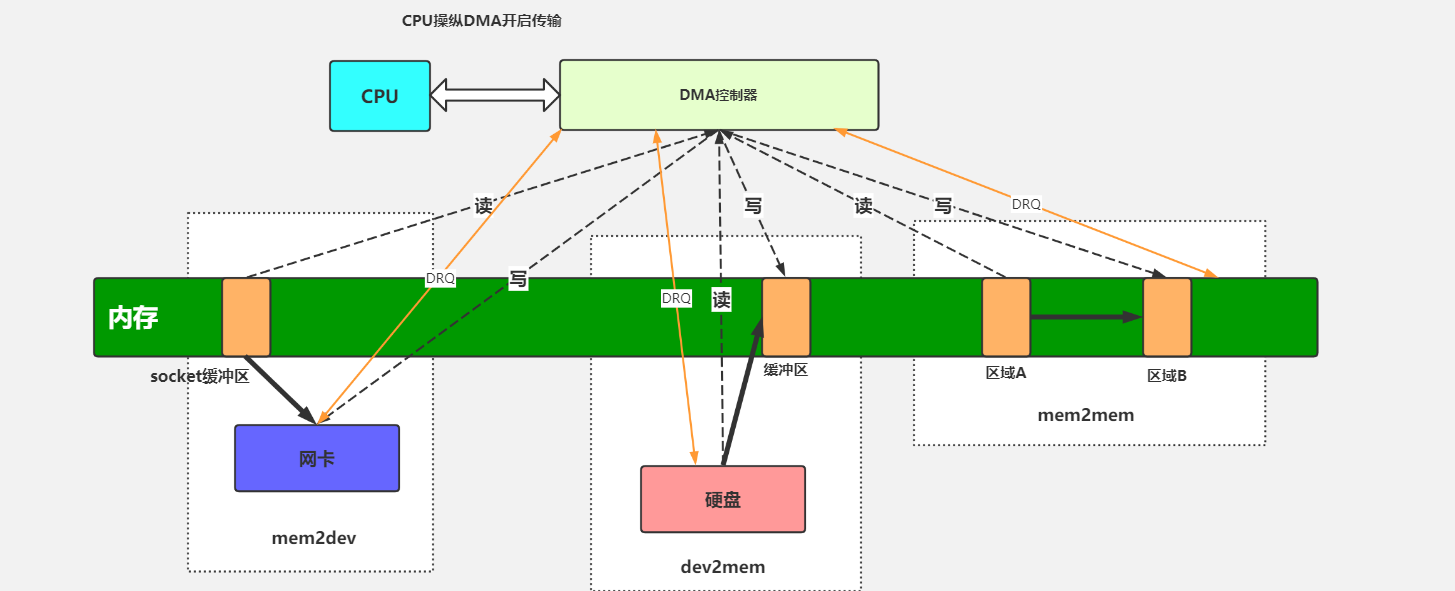
DMA 方式是一种完全由硬件进行信息传送的控制方式,通常系统总线由 CPU 管理,在 DMA 方式中,CPU 的主存控制信号被禁止使用,CPU 把总线(地址总线、数据总线、控制总线)让出来由 DMA 控制器接管,用来控制传送的字节数、判断 DMA 是否结束、以及发出 DMA 结束信号,所以 DMA 控制器必须有以下功能:
- 接受外设发出的 DMA 请求,并向 CPU 发出总线接管请求
- 当 CPU 发出允许接管信号后,进入 DMA 操作周期
- 确定传送数据的主存单元地址及长度,并自动修改主存地址计数和传送长度计数
- 规定数据在主存和外设间的传送方向,发出读写等控制信号,执行数据传送操作
- 判断 DMA 传送是否结束,发出 DMA 结束信号,使 CPU 恢复正常工作状态(中断)
BIO
传统的 I/O 操作进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝:
- JVM 发出 read 系统调用,OS 上下文切换到内核模式(切换 1)并将数据从网卡或硬盘等设备通过 DMA 读取到内核空间缓冲区(拷贝 1),内核缓冲区实际上是磁盘高速缓存(PageCache)
- OS 内核将数据复制到用户空间缓冲区(拷贝 2),然后 read 系统调用返回,又会导致一次内核空间到用户空间的上下文切换(切换 2)
- JVM 处理代码逻辑并发送 write() 系统调用,OS 上下文切换到内核模式(切换3)并从用户空间缓冲区复制数据到内核空间缓冲区(拷贝3)
- 将内核空间缓冲区中的数据写到 hardware(拷贝4),write 系统调用返回,导致内核空间到用户空间的再次上下文切换(切换4)
流程图中的箭头反过来也成立,可以从网卡获取数据
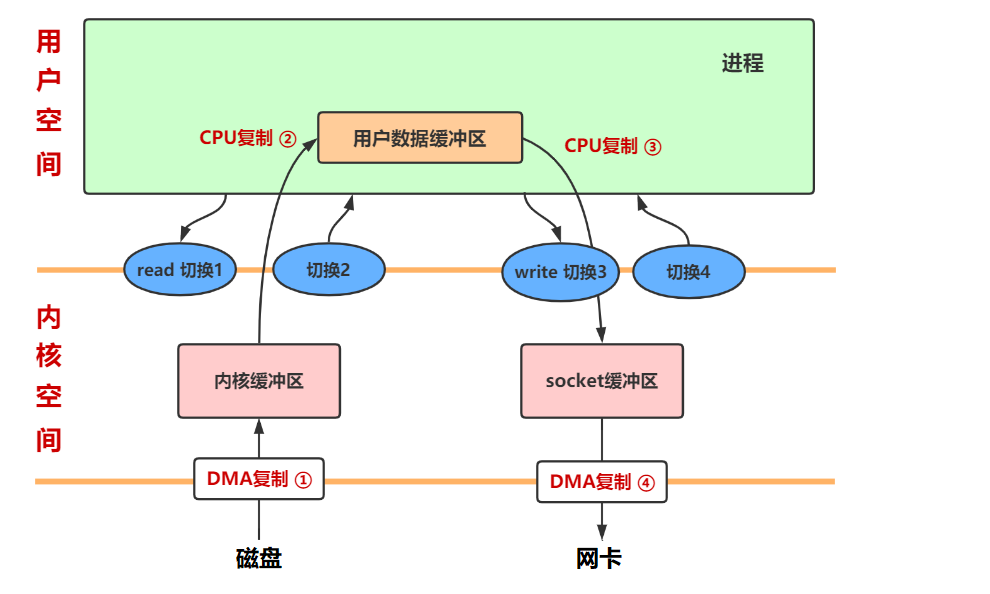
read 调用图示:read、write 都是系统调用指令
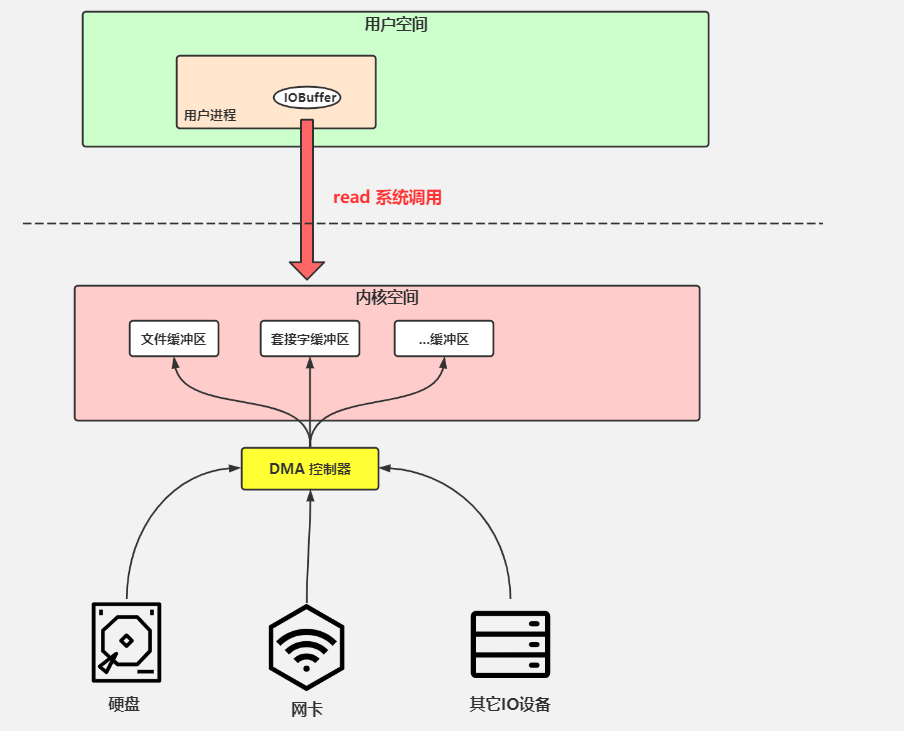
mmap
mmap(Memory Mapped Files)内存映射加 write 实现零拷贝,零拷贝就是没有数据从内核空间复制到用户空间
用户空间和内核空间都使用内存,所以可以共享同一块物理内存地址,省去用户态和内核态之间的拷贝。写网卡时,共享空间的内容拷贝到 Socket 缓冲区,然后交给 DMA 发送到网卡,只需要 3 次复制
进行了 4 次用户空间与内核空间的上下文切换,以及 3 次数据拷贝(2 次 DMA,一次 CPU 复制):
- 发出 mmap 系统调用,DMA 拷贝到内核缓冲区,映射到共享缓冲区;mmap 系统调用返回,无需拷贝
- 发出 write 系统调用,将数据从内核缓冲区拷贝到内核 Socket 缓冲区;write 系统调用返回,DMA 将内核空间 Socket 缓冲区中的数据传递到协议引擎
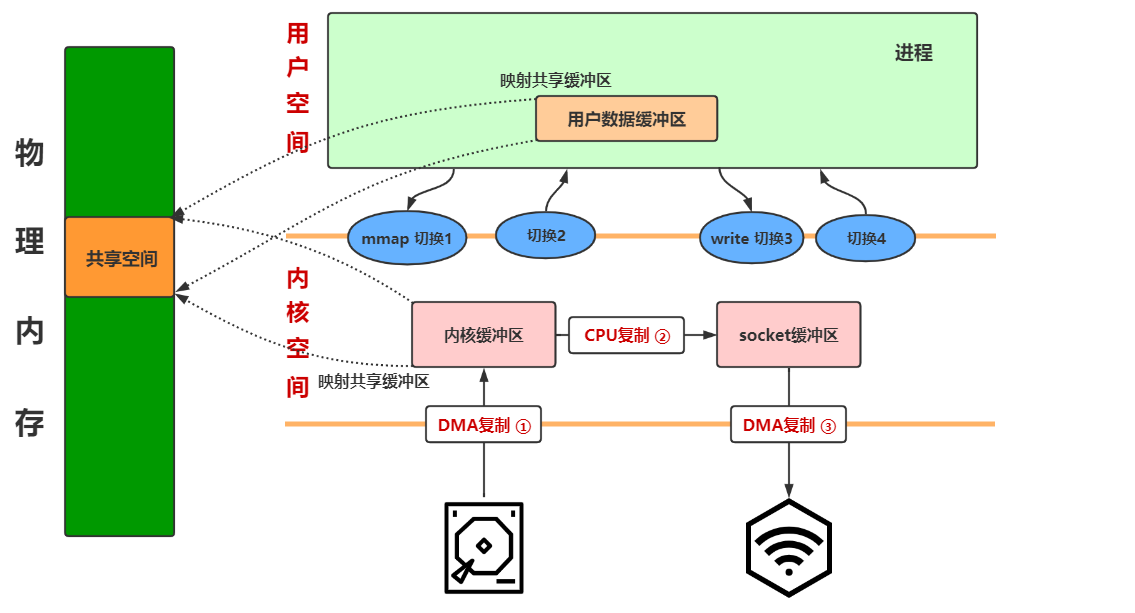
原理:利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射后对物理内存的操作会被同步到硬盘上
缺点:不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘
Java NIO 提供了 MappedByteBuffer 类可以用来实现 mmap 内存映射,MappedByteBuffer 类对象只能通过调用 **FileChannel.map()** 获取
sendfile
sendfile 实现零拷贝,打开文件的文件描述符 fd 和 socket 的 fd 传递给 sendfile,然后经过 3 次复制和 2 次用户态和内核态的切换
原理:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,由于和用户态完全无关,就减少了两次上下文切换
说明:零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送
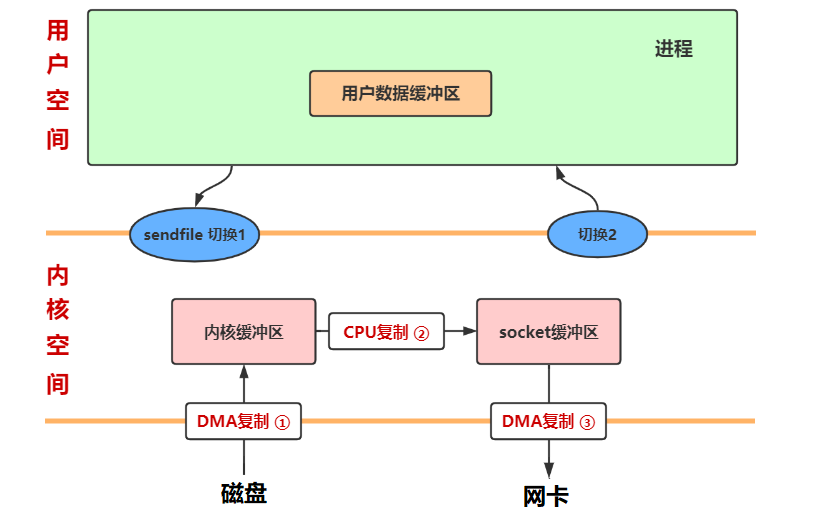
sendfile2.4 之后,sendfile 实现了更简单的方式,文件到达内核缓冲区后,不必再将数据全部复制到 socket buffer 缓冲区,而是只将记录数据位置和长度相关等描述符信息保存到 socket buffer,DMA 根据 Socket 缓冲区中描述符提供的位置和偏移量信息直接将内核空间缓冲区中的数据拷贝到协议引擎上(2 次复制 2 次切换)
Java NIO 对 sendfile 的支持是 FileChannel.transferTo()/transferFrom(),把磁盘文件读取 OS 内核缓冲区后的 fileChannel,直接转给 socketChannel 发送,底层就是 sendfile
参考文章:https://blog.csdn.net/hancoder/article/details/112149121
BIO
Inet
一个 InetAddress 类的对象就代表一个 IP 地址对象
成员方法:
static InetAddress getLocalHost():获得本地主机 IP 地址对象static InetAddress getByName(String host):根据 IP 地址字符串或主机名获得对应的 IP 地址对象String getHostName():获取主机名String getHostAddress():获得 IP 地址字符串
public class InetAddressDemo {
public static void main(String[] args) throws Exception {
// 1.获取本机地址对象
InetAddress ip = InetAddress.getLocalHost();
System.out.println(ip.getHostName());//DESKTOP-NNMBHQR
System.out.println(ip.getHostAddress());//192.168.11.1
// 2.获取域名ip对象
InetAddress ip2 = InetAddress.getByName("www.baidu.com");
System.out.println(ip2.getHostName());//www.baidu.com
System.out.println(ip2.getHostAddress());//14.215.177.38
// 3.获取公网IP对象。
InetAddress ip3 = InetAddress.getByName("182.61.200.6");
System.out.println(ip3.getHostName());//182.61.200.6
System.out.println(ip3.getHostAddress());//182.61.200.6
// 4.判断是否能通: ping 5s之前测试是否可通
System.out.println(ip2.isReachable(5000)); // ping百度
}
}
UDP
基本介绍
UDP(User Datagram Protocol)协议的特点:
- 面向无连接的协议,发送端只管发送,不确认对方是否能收到,速度快,但是不可靠,会丢失数据
- 尽最大努力交付,没有拥塞控制
- 基于数据包进行数据传输,发送数据的包的大小限制 64KB 以内
- 支持一对一、一对多、多对一、多对多的交互通信
UDP 协议的使用场景:在线视频、网络语音、电话
实现UDP
UDP 协议相关的两个类:
- DatagramPacket(数据包对象):用来封装要发送或要接收的数据,比如:集装箱
- DatagramSocket(发送对象):用来发送或接收数据包,比如:码头
DatagramPacket:
DatagramPacket 类:
public new DatagramPacket(byte[] buf, int length, InetAddress address, int port):创建发送端数据包对象buf:要发送的内容,字节数组
length:要发送内容的长度,单位是字节
address:接收端的IP地址对象
port:接收端的端口号
public new DatagramPacket(byte[] buf, int length):创建接收端的数据包对象
buf:用来存储接收到内容
length:能够接收内容的长度
DatagramPacket 类常用方法:
public int getLength():获得实际接收到的字节个数public byte[] getData():返回数据缓冲区
DatagramSocket:
DatagramSocket 类构造方法:
protected DatagramSocket():创建发送端的 Socket 对象,系统会随机分配一个端口号protected DatagramSocket(int port):创建接收端的 Socket 对象并指定端口号DatagramSocket 类成员方法:
public void send(DatagramPacket dp):发送数据包public void receive(DatagramPacket p):接收数据包public void close():关闭数据报套接字
public class UDPClientDemo {
public static void main(String[] args) throws Exception {
System.out.println("===启动客户端===");
// 1.创建一个集装箱对象,用于封装需要发送的数据包!
byte[] buffer = "我学Java".getBytes();
DatagramPacket packet = new DatagramPacket(buffer,bubffer.length,InetAddress.getLoclHost,8000);
// 2.创建一个码头对象
DatagramSocket socket = new DatagramSocket();
// 3.开始发送数据包对象
socket.send(packet);
socket.close();
}
}
public class UDPServerDemo{
public static void main(String[] args) throws Exception {
System.out.println("==启动服务端程序==");
// 1.创建一个接收客户都端的数据包对象(集装箱)
byte[] buffer = new byte[1024*64];
DatagramPacket packet = new DatagramPacket(buffer, bubffer.length);
// 2.创建一个接收端的码头对象
DatagramSocket socket = new DatagramSocket(8000);
// 3.开始接收
socket.receive(packet);
// 4.从集装箱中获取本次读取的数据量
int len = packet.getLength();
// 5.输出数据
// String rs = new String(socket.getData(), 0, len)
String rs = new String(buffer , 0 , len);
System.out.println(rs);
// 6.服务端还可以获取发来信息的客户端的IP和端口。
String ip = packet.getAddress().getHostAdress();
int port = packet.getPort();
socket.close();
}
}
通讯方式
UDP 通信方式:
- 单播:用于两个主机之间的端对端通信
- 组播:用于对一组特定的主机进行通信 IP : 224.0.1.0 Socket 对象 : MulticastSocket
- 广播:用于一个主机对整个局域网上所有主机上的数据通信 IP : 255.255.255.255 Socket 对象 : DatagramSocket
TCP
基本介绍
TCP/IP (Transfer Control Protocol) 协议,传输控制协议
TCP/IP 协议的特点:
- 面向连接的协议,提供可靠交互,速度慢
- 点对点的全双工通信
- 通过三次握手建立连接,连接成功形成数据传输通道;通过四次挥手断开连接
- 基于字节流进行数据传输,传输数据大小没有限制
TCP 协议的使用场景:文件上传和下载、邮件发送和接收、远程登录
注意:TCP 不会为没有数据的 ACK 超时重传
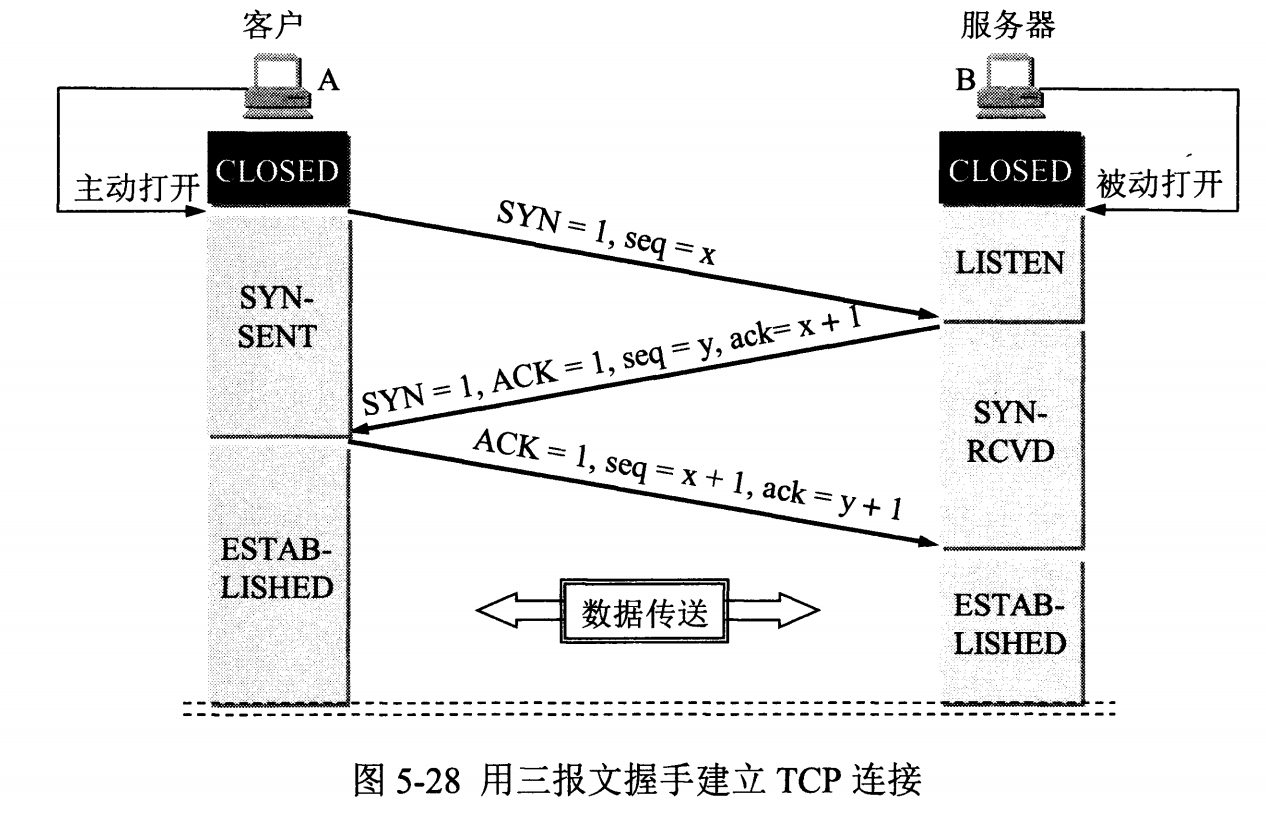
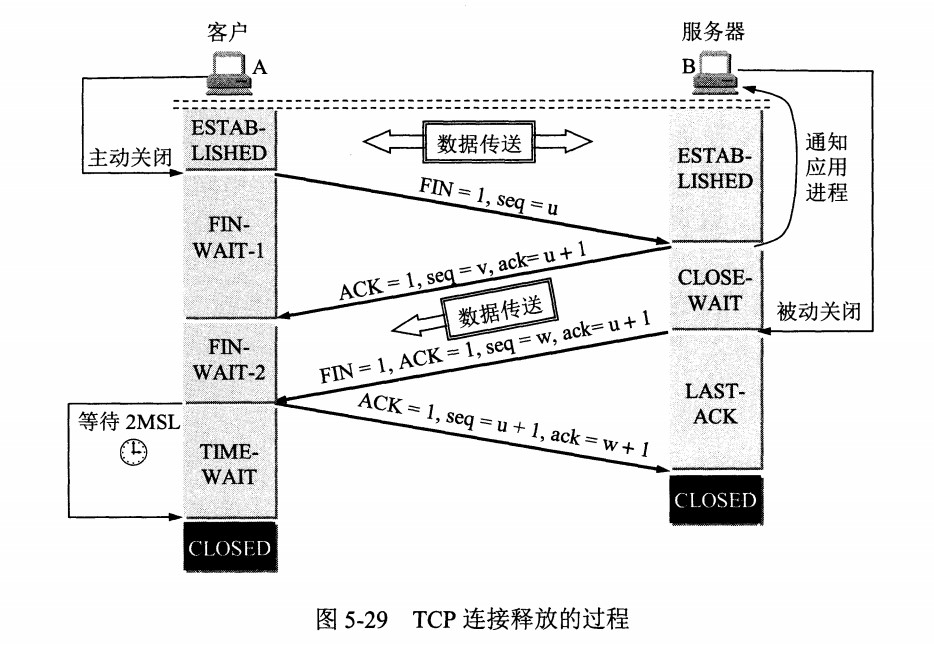
推荐阅读:https://yuanrengu.com/2020/77eef79f.html
Socket
TCP 通信也叫 Socket 网络编程,只要代码基于 Socket 开发,底层就是基于了可靠传输的 TCP 通信
双向通信:Java Socket 是全双工的,在任意时刻,线路上存在 A -> B 和 B -> A 的双向信号传输,即使是阻塞 IO,读和写也是可以同时进行的,只要分别采用读线程和写线程即可,读不会阻塞写、写也不会阻塞读
TCP 协议相关的类:
- Socket:一个该类的对象就代表一个客户端程序。
- ServerSocket:一个该类的对象就代表一个服务器端程序。
Socket 类:
构造方法:
Socket(InetAddress address,int port):创建流套接字并将其连接到指定 IP 指定端口号Socket(String host, int port):根据 IP 地址字符串和端口号创建客户端 Socket 对象 注意事项:执行该方法,就会立即连接指定的服务器,连接成功,则表示三次握手通过,反之抛出异常常用 API:
OutputStream getOutputStream():获得字节输出流对象InputStream getInputStream():获得字节输入流对象void shutdownInput():停止接受void shutdownOutput():停止发送数据,终止通信SocketAddress getRemoteSocketAddress():返回套接字连接到的端点的地址,未连接返回 null
ServerSocket 类:
- 构造方法:
public ServerSocket(int port) - 常用 API:
public Socket accept(),阻塞等待接收一个客户端的 Socket 管道连接请求,连接成功返回一个 Socket 对象 三次握手后 TCP 连接建立成功,服务器内核会把连接从 SYN 半连接队列(一次握手时在服务端建立的队列)中移出,移入 accept 全连接队列,等待进程调用 accept 函数时把连接取出。如果进程不能及时调用 accept 函数,就会造成 accept 队列溢出,最终导致建立好的 TCP 连接被丢弃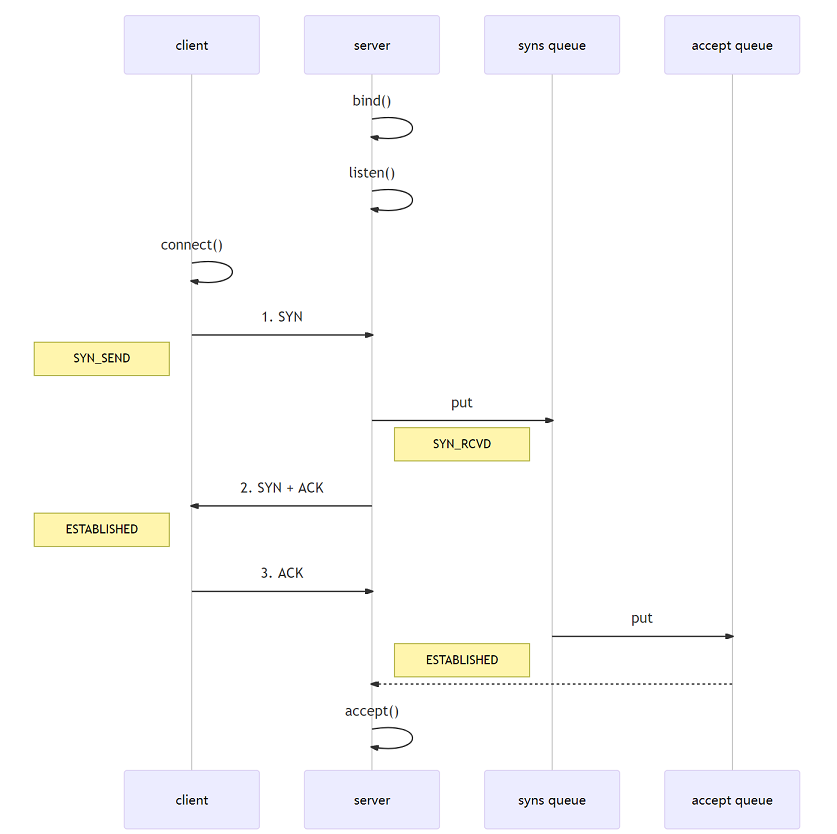
相当于客户端和服务器建立一个数据管道(虚连接,不是真正的物理连接),管道一般不用 close
实现TCP
开发流程
客户端的开发流程:
- 客户端要请求于服务端的 Socket 管道连接
- 从 Socket 通信管道中得到一个字节输出流
- 通过字节输出流给服务端写出数据
服务端的开发流程:
- 用 ServerSocket 注册端口
- 接收客户端的 Socket 管道连接
- 从 Socket 通信管道中得到一个字节输入流
- 从字节输入流中读取客户端发来的数据
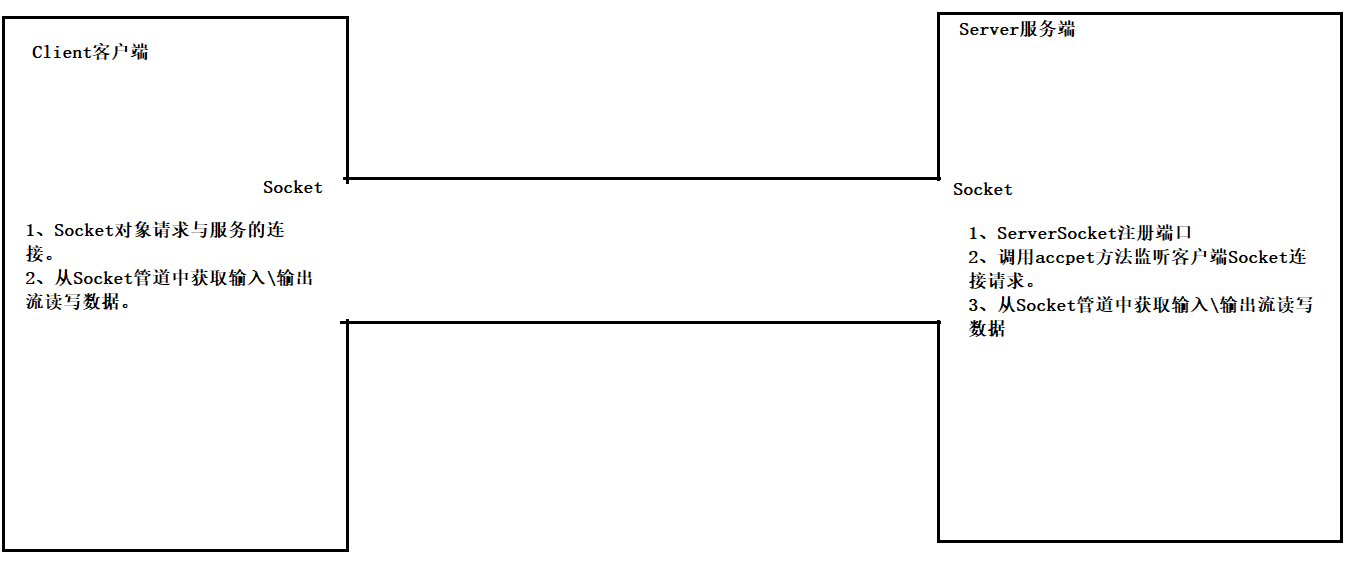

- 如果输出缓冲区空间不够存放主机发送的数据,则会被阻塞,输入缓冲区同理
- 缓冲区不属于应用程序,属于内核
- TCP 从输出缓冲区读取数据会加锁阻塞线程
实现通信
需求一:客户端发送一行数据,服务端接收一行数据
public class ClientDemo {
public static void main(String[] args) throws Exception {
// 1.客户端要请求于服务端的socket管道连接。
Socket socket = new Socket("127.0.0.1", 8080);
// 2.从socket通信管道中得到一个字节输出流
OutputStream os = socket.getOutputStream();
// 3.把低级的字节输出流包装成高级的打印流。
PrintStream ps = new PrintStream(os);
// 4.开始发消息出去
ps.println("我是客户端");
ps.flush();//一般不关闭IO流
System.out.println("客户端发送完毕~~~~");
}
}
public class ServerDemo{
public static void main(String[] args) throws Exception {
System.out.println("----服务端启动----");
// 1.注册端口: public ServerSocket(int port)
ServerSocket serverSocket = new ServerSocket(8080);
// 2.开始等待接收客户端的Socket管道连接。
Socket socket = serverSocket.accept();
// 3.从socket通信管道中得到一个字节输入流。
InputStream is = socket.getInputStream();
// 4.把字节输入流转换成字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 6.按照行读取消息 。
String line;
if((line = br.readLine()) != null){
System.out.println(line);
}
}
}
需求二:客户端可以反复发送数据,服务端可以反复数据
public class ClientDemo {
public static void main(String[] args) throws Exception {
// 1.客户端要请求于服务端的socket管道连接。
Socket socket = new Socket("127.0.0.1",8080);
// 2.从socket通信管道中得到一个字节输出流
OutputStream os = socket.getOutputStream();
// 3.把低级的字节输出流包装成高级的打印流。
PrintStream ps = new PrintStream(os);
// 4.开始发消息出去
while(true){
Scanner sc = new Scanner(System.in);
System.out.print("请说:");
ps.println(sc.nextLine());
ps.flush();
}
}
}
public class ServerDemo{
public static void main(String[] args) throws Exception {
System.out.println("----服务端启动----");
// 1.注册端口: public ServerSocket(int port)
ServerSocket serverSocket = new ServerSocket(8080);
// 2.开始等待接收客户端的Socket管道连接。
Socket socket = serverSocket.accept();
// 3.从socket通信管道中得到一个字节输入流。
InputStream is = socket.getInputStream();
// 4.把字节输入流转换成字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 6.按照行读取消息 。
String line;
while((line = br.readLine()) != null){
System.out.println(line);
}
}
}
需求三:实现一个服务端可以同时接收多个客户端的消息
public class ClientDemo {
public static void main(String[] args) throws Exception {
Socket socket = new Socket("127.0.0.1",8080);
OutputStream os = new socket.getOutputStream();
PrintStream ps = new PrintStream(os);
while(true){
Scanner sc = new Scanner(System.in);
System.out.print("请说:");
ps.println(sc.nextLine());
ps.flush();
}
}
}
public class ServerDemo{
public static void main(String[] args) throws Exception {
System.out.println("----服务端启动----");
ServerSocket serverSocket = new ServerSocket(8080);
while(true){
// 开始等待接收客户端的Socket管道连接。
Socket socket = serverSocket.accept();
// 每接收到一个客户端必须为这个客户端管道分配一个独立的线程来处理与之通信。
new ServerReaderThread(socket).start();
}
}
}
class ServerReaderThread extends Thread{
privat Socket socket;
public ServerReaderThread(Socket socket){this.socket = socket;}
@Override
public void run() {
try(InputStream is = socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is))
){
String line;
while((line = br.readLine()) != null){
sout(socket.getRemoteSocketAddress() + ":" + line);
}
}catch(Exception e){
sout(socket.getRemoteSocketAddress() + "下线了~~~~~~");
}
}
}
伪异步
一个客户端要一个线程,并发越高系统瘫痪的越快,可以在服务端引入线程池,使用线程池来处理与客户端的消息通信
- 优势:不会引起系统的死机,可以控制并发线程的数量
- 劣势:同时可以并发的线程将受到限制
public class BIOServer {
public static void main(String[] args) throws Exception {
//线程池机制
//创建一个线程池,如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
//创建ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
System.out.println("服务器启动了");
while (true) {
System.out.println("线程名字 = " + Thread.currentThread().getName());
//监听,等待客户端连接
System.out.println("等待连接....");
final Socket socket = serverSocket.accept();
System.out.println("连接到一个客户端");
//创建一个线程,与之通讯
newCachedThreadPool.execute(new Runnable() {
public void run() {
//可以和客户端通讯
handler(socket);
}
});
}
}
//编写一个handler方法,和客户端通讯
public static void handler(Socket socket) {
try {
System.out.println("线程名字 = " + Thread.currentThread().getName());
byte[] bytes = new byte[1024];
//通过socket获取输入流
InputStream inputStream = socket.getInputStream();
int len;
//循环的读取客户端发送的数据
while ((len = inputStream.read(bytes)) != -1) {
System.out.println("线程名字 = " + Thread.currentThread().getName());
//输出客户端发送的数据
System.out.println(new String(bytes, 0, read));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("关闭和client的连接");
try {
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
文件传输
字节流
客户端:本地图片: E:\seazean\图片资源\beautiful.jpg 服务端:服务器路径:E:\seazean\图片服务器
UUID. randomUUID() : 方法生成随机的文件名
socket.shutdownOutput():这个必须执行,不然服务器会一直循环等待数据,最后文件损坏,程序报错
//常量包
public class Constants {
public static final String SRC_IMAGE = "D:\\seazean\\图片资源\\beautiful.jpg";
public static final String SERVER_DIR = "D:\\seazean\\图片服务器\\";
public static final String SERVER_IP = "127.0.0.1";
public static final int SERVER_PORT = 8888;
}
public class ClientDemo {
public static void main(String[] args) throws Exception {
Socket socket = new Socket(Constants.ERVER_IP,Constants.SERVER_PORT);
BufferedOutputStream bos=new BufferedOutputStream(socket.getOutputStream());
//提取本机的图片上传给服务端。Constants.SRC_IMAGE
BufferedInputStream bis = new BufferedInputStream(new FileInputStream());
byte[] buffer = new byte[1024];
int len ;
while((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0 ,len);
}
bos.flush();// 刷新图片数据到服务端!!
socket.shutdownOutput();// 告诉服务端我的数据已经发送完毕,不要在等我了!
bis.close();
//等待着服务端的响应数据!!
BufferedReader br = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
System.out.println("收到服务端响应:"+br.readLine());
}
}
public class ServerDemo {
public static void main(String[] args) throws Exception {
System.out.println("----服务端启动----");
// 1.注册端口:
ServerSocket serverSocket = new ServerSocket(Constants.SERVER_PORT);
// 2.定义一个循环不断的接收客户端的连接请求
while(true){
// 3.开始等待接收客户端的Socket管道连接。
Socket socket = serverSocket.accept();
// 4.每接收到一个客户端必须为这个客户端管道分配一个独立的线程来处理与之通信。
new ServerReaderThread(socket).start();
}
}
}
class ServerReaderThread extends Thread{
private Socket socket ;
public ServerReaderThread(Socket socket){this.socket = socket;}
@Override
public void run() {
try{
InputStream is = socket.getInputStream();
BufferedInputStream bis = new BufferedInputStream(is);
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream
(Constants.SERVER_DIR+UUID.randomUUID().toString()+".jpg"));
byte[] buffer = new byte[1024];
int len;
while((len = bis.read(buffer)) != -1){
bos.write(buffer,0,len);
}
bos.close();
System.out.println("服务端接收完毕了!");
// 4.响应数据给客户端
PrintStream ps = new PrintStream(socket.getOutputStream());
ps.println("您好,已成功接收您上传的图片!");
ps.flush();
Thread.sleep(10000);
}catch (Exception e){
sout(socket.getRemoteSocketAddress() + "下线了");
}
}
}
数据流
构造方法:
DataOutputStream(OutputStream out): 创建一个新的数据输出流,以将数据写入指定的底层输出流DataInputStream(InputStream in): 创建使用指定的底层 InputStream 的 DataInputStream
常用API:
final void writeUTF(String str): 使用机器无关的方式使用 UTF-8 编码将字符串写入底层输出流final String readUTF(): 读取以 modified UTF-8 格式编码的 Unicode 字符串,返回 String 类型
public class Client {
public static void main(String[] args) {
InputStream is = new FileInputStream("path");
// 1、请求与服务端的Socket链接
Socket socket = new Socket("127.0.0.1" , 8888);
// 2、把字节输出流包装成一个数据输出流
DataOutputStream dos = new DataOutputStream(socket.getOutputStream());
// 3、先发送上传文件的后缀给服务端
dos.writeUTF(".png");
// 4、把文件数据发送给服务端进行接收
byte[] buffer = new byte[1024];
int len;
while((len = is.read(buffer)) > 0 ){
dos.write(buffer , 0 , len);
}
dos.flush();
Thread.sleep(10000);
}
}
public class Server {
public static void main(String[] args) {
ServerSocket ss = new ServerSocket(8888);
Socket socket = ss.accept();
// 1、得到一个数据输入流读取客户端发送过来的数据
DataInputStream dis = new DataInputStream(socket.getInputStream());
// 2、读取客户端发送过来的文件类型
String suffix = dis.readUTF();
// 3、定义一个字节输出管道负责把客户端发来的文件数据写出去
OutputStream os = new FileOutputStream("path"+
UUID.randomUUID().toString()+suffix);
// 4、从数据输入流中读取文件数据,写出到字节输出流中去
byte[] buffer = new byte[1024];
int len;
while((len = dis.read(buffer)) > 0){
os.write(buffer,0, len);
}
os.close();
System.out.println("服务端接收文件保存成功!");
}
}
NIO
基本介绍
NIO的介绍:
Java NIO(New IO、Java non-blocking IO),从 Java 1.4 版本开始引入的一个新的 IO API,可以替代标准的 Java IO API,NIO 支持面向缓冲区的、基于通道的 IO 操作,以更加高效的方式进行文件的读写操作
- NIO 有三大核心部分:Channel(通道),Buffer(缓冲区),Selector(选择器)
- NIO 是非阻塞 IO,传统 IO 的 read 和 write 只能阻塞执行,线程在读写 IO 期间不能干其他事情,比如调用 socket.accept(),如果服务器没有数据传输过来,线程就一直阻塞,而 NIO 中可以配置 Socket 为非阻塞模式
- NIO 可以做到用一个线程来处理多个操作的。假设有 1000 个请求过来,根据实际情况可以分配 20 或者 80 个线程来处理,不像之前的阻塞 IO 那样分配 1000 个
NIO 和 BIO 的比较:
- BIO 以流的方式处理数据,而 NIO 以块的方式处理数据,块 I/O 的效率比流 I/O 高很多
- BIO 是阻塞的,NIO 则是非阻塞的
- BIO 基于字节流和字符流进行操作,而 NIO 基于 Channel 和 Buffer 进行操作,数据从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector 用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道
| NIO | BIO |
|---|---|
| 面向缓冲区(Buffer) | 面向流(Stream) |
| 非阻塞(Non Blocking IO) | 阻塞IO(Blocking IO) |
| 选择器(Selectors) |
实现原理
NIO 三大核心部分:Channel (通道)、Buffer (缓冲区)、Selector (选择器)
- Buffer 缓冲区 缓冲区本质是一块可以写入数据、读取数据的内存,底层是一个数组,这块内存被包装成 NIO Buffer 对象,并且提供了方法用来操作这块内存,相比较直接对数组的操作,Buffer 的 API 更加容易操作和管理
- Channel 通道 Java NIO 的通道类似流,不同的是既可以从通道中读取数据,又可以写数据到通道,流的读写通常是单向的,通道可以非阻塞读取和写入通道,支持读取或写入缓冲区,也支持异步地读写
- Selector 选择器 Selector 是一个 Java NIO 组件,能够检查一个或多个 NIO 通道,并确定哪些通道已经准备好进行读取或写入,这样一个单独的线程可以管理多个 channel,从而管理多个网络连接,提高效率
NIO 的实现框架:
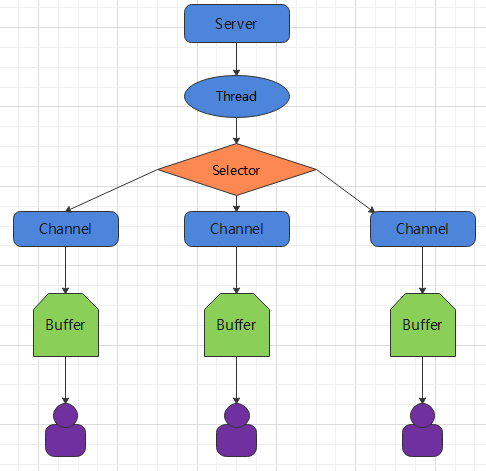
- 每个 Channel 对应一个 Buffer
- 一个线程对应 Selector , 一个 Selector 对应多个 Channel(连接)
- 程序切换到哪个 Channel 是由事件决定的,Event 是一个重要的概念
- Selector 会根据不同的事件,在各个通道上切换
- Buffer 是一个内存块 , 底层是一个数组
- 数据的读取写入是通过 Buffer 完成的 , BIO 中要么是输入流,或者是输出流,不能双向,NIO 的 Buffer 是可以读也可以写, flip() 切换 Buffer 的工作模式
Java NIO 系统的核心在于:通道和缓冲区,通道表示打开的 IO 设备(例如:文件、 套接字)的连接。若要使用 NIO 系统,获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区,然后操作缓冲区,对数据进行处理。简而言之,Channel 负责传输, Buffer 负责存取数据
缓冲区
基本介绍
缓冲区(Buffer):缓冲区本质上是一个可以读写数据的内存块,用于特定基本数据类型的容器,用于与 NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的
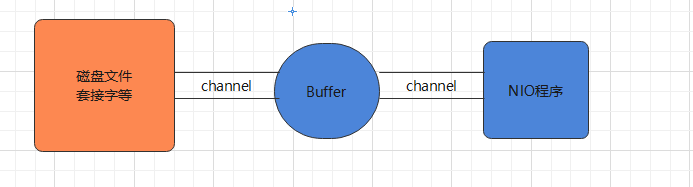
Buffer 底层是一个数组,可以保存多个相同类型的数据,根据数据类型不同 ,有以下 Buffer 常用子类:ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer
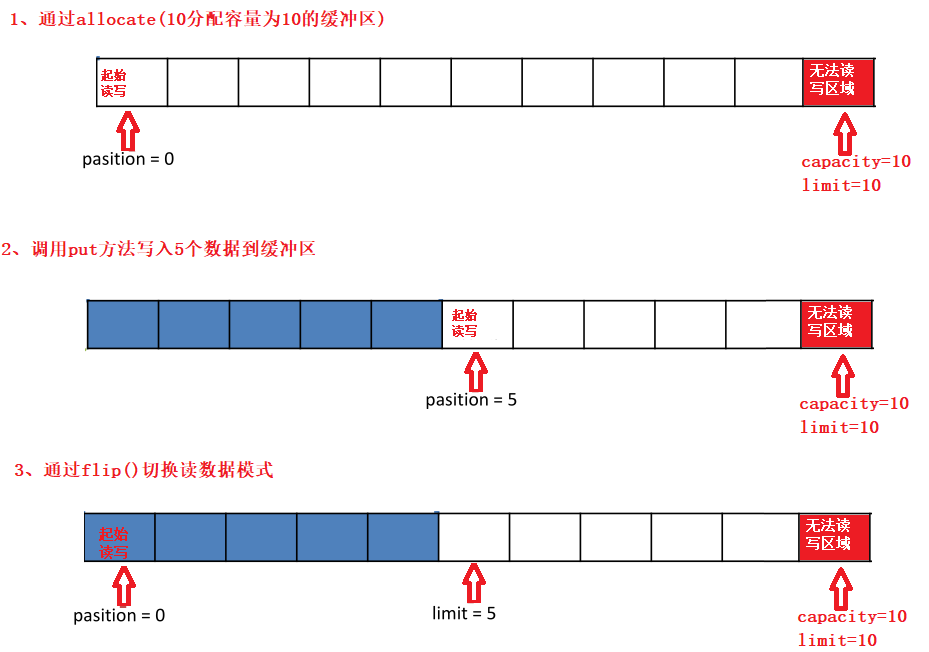
基本属性
- 容量(capacity):作为一个内存块,Buffer 具有固定大小,缓冲区容量不能为负,并且创建后不能更改
- 限制 (limit):表示缓冲区中可以操作数据的大小(limit 后数据不能进行读写),缓冲区的限制不能为负,并且不能大于其容量。写入模式,limit 等于 buffer 的容量;读取模式下,limit 等于写入的数据量
- 位置(position):下一个要读取或写入的数据的索引,缓冲区的位置不能为负,并且不能大于其限制
- 标记(mark)与重置(reset):标记是一个索引,通过 Buffer 中的 mark() 方法指定 Buffer 中一个特定的位置,可以通过调用 reset() 方法恢复到这个 position
- 位置、限制、容量遵守以下不变式: 0 <= position <= limit <= capacity
常用API
static XxxBuffer allocate(int capacity):创建一个容量为 capacity 的 XxxBuffer 对象
Buffer 基本操作:
| 方法 | 说明 |
|---|---|
| public Buffer clear() | 清空缓冲区,不清空内容,将位置设置为零,限制设置为容量 |
| public Buffer flip() | 翻转缓冲区,将缓冲区的界限设置为当前位置,position 置 0 |
| public int capacity() | 返回 Buffer的 capacity 大小 |
| public final int limit() | 返回 Buffer 的界限 limit 的位置 |
| public Buffer limit(int n) | 设置缓冲区界限为 n |
| public Buffer mark() | 在此位置对缓冲区设置标记 |
| public final int position() | 返回缓冲区的当前位置 position |
| public Buffer position(int n) | 设置缓冲区的当前位置为n |
| public Buffer reset() | 将位置 position 重置为先前 mark 标记的位置 |
| public Buffer rewind() | 将位置设为为 0,取消设置的 mark |
| public final int remaining() | 返回当前位置 position 和 limit 之间的元素个数 |
| public final boolean hasRemaining() | 判断缓冲区中是否还有元素 |
| public static ByteBuffer wrap(byte[] array) | 将一个字节数组包装到缓冲区中 |
| abstract ByteBuffer asReadOnlyBuffer() | 创建一个新的只读字节缓冲区 |
| public abstract ByteBuffer compact() | 缓冲区当前位置与其限制(如果有)之间的字节被复制到缓冲区的开头 |
Buffer 数据操作:
| 方法 | 说明 |
|---|---|
| public abstract byte get() | 读取该缓冲区当前位置的单个字节,然后位置 + 1 |
| public ByteBuffer get(byte[] dst) | 读取多个字节到字节数组 dst 中 |
| public abstract byte get(int index) | 读取指定索引位置的字节,不移动 position |
| public abstract ByteBuffer put(byte b) | 将给定单个字节写入缓冲区的当前位置,position+1 |
| public final ByteBuffer put(byte[] src) | 将 src 字节数组写入缓冲区的当前位置 |
| public abstract ByteBuffer put(int index, byte b) | 将指定字节写入缓冲区的索引位置,不移动 position |
提示:"\n",占用两个字节
读写数据
使用 Buffer 读写数据一般遵循以下四个步骤:
- 写入数据到 Buffer
- 调用 flip()方法,转换为读取模式
- 从 Buffer 中读取数据
- 调用 buffer.clear() 方法清除缓冲区(不是清空了数据,只是重置指针)
public class TestBuffer {
@Test
public void test(){
String str = "seazean";
//1. 分配一个指定大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
System.out.println("-----------------allocate()----------------");
System.out.println(bufferf.position());//0
System.out.println(buffer.limit());//1024
System.out.println(buffer.capacity());//1024
//2. 利用 put() 存入数据到缓冲区中
buffer.put(str.getBytes());
System.out.println("-----------------put()----------------");
System.out.println(bufferf.position());//7
System.out.println(buffer.limit());//1024
System.out.println(buffer.capacity());//1024
//3. 切换读取数据模式
buffer.flip();
System.out.println("-----------------flip()----------------");
System.out.println(buffer.position());//0
System.out.println(buffer.limit());//7
System.out.println(buffer.capacity());//1024
//4. 利用 get() 读取缓冲区中的数据
byte[] dst = new byte[buffer.limit()];
buffer.get(dst);
System.out.println(dst.length);
System.out.println(new String(dst, 0, dst.length));
System.out.println(buffer.position());//7
System.out.println(buffer.limit());//7
//5. clear() : 清空缓冲区. 但是缓冲区中的数据依然存在,但是处于“被遗忘”状态
System.out.println(buffer.hasRemaining());//true
buffer.clear();
System.out.println(buffer.hasRemaining());//true
System.out.println("-----------------clear()----------------");
System.out.println(buffer.position());//0
System.out.println(buffer.limit());//1024
System.out.println(buffer.capacity());//1024
}
}
粘包拆包
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔,但这些数据在接收时,被进行了重新组合
// Hello,world\n
// I'm zhangsan\n
// How are you?\n
------ > 黏包,半包
// Hello,world\nI'm zhangsan\nHo
// w are you?\n
public static void main(String[] args) {
ByteBuffer source = ByteBuffer.allocate(32);
// 11 24
source.put("Hello,world\nI'm zhangsan\nHo".getBytes());
split(source);
source.put("w are you?\nhaha!\n".getBytes());
split(source);
}
private static void split(ByteBuffer source) {
source.flip();
int oldLimit = source.limit();
for (int i = 0; i < oldLimit; i++) {
if (source.get(i) == '\n') {
// 根据数据的长度设置缓冲区
ByteBuffer target = ByteBuffer.allocate(i + 1 - source.position());
// 0 ~ limit
source.limit(i + 1);
target.put(source); // 从source 读,向 target 写
// debugAll(target); 访问 buffer 的方法
source.limit(oldLimit);
}
}
// 访问过的数据复制到开头
source.compact();
}
直接内存
基本介绍
Byte Buffer 有两种类型,一种是基于直接内存(也就是非堆内存),另一种是非直接内存(也就是堆内存)
Direct Memory 优点:
- Java 的 NIO 库允许 Java 程序使用直接内存,使用 native 函数直接分配堆外内存
- 读写性能高,读写频繁的场合可能会考虑使用直接内存
- 大大提高 IO 性能,避免了在 Java 堆和 native 堆来回复制数据
直接内存缺点:
- 不能使用内核缓冲区 Page Cache 的缓存优势,无法缓存最近被访问的数据和使用预读功能
- 分配回收成本较高,不受 JVM 内存回收管理
- 可能导致 OutOfMemoryError 异常:OutOfMemoryError: Direct buffer memory
- 回收依赖 System.gc() 的调用,但这个调用 JVM 不保证执行、也不保证何时执行,行为是不可控的。程序一般需要自行管理,成对去调用 malloc、free
应用场景:
- 传输很大的数据文件,数据的生命周期很长,导致 Page Cache 没有起到缓存的作用,一般采用直接 IO 的方式
- 适合频繁的 IO 操作,比如网络并发场景
数据流的角度:
- 非直接内存的作用链:本地 IO → 内核缓冲区→ 用户(JVM)缓冲区 →内核缓冲区 → 本地 IO
- 直接内存是:本地 IO → 直接内存 → 本地 IO
JVM 直接内存图解:
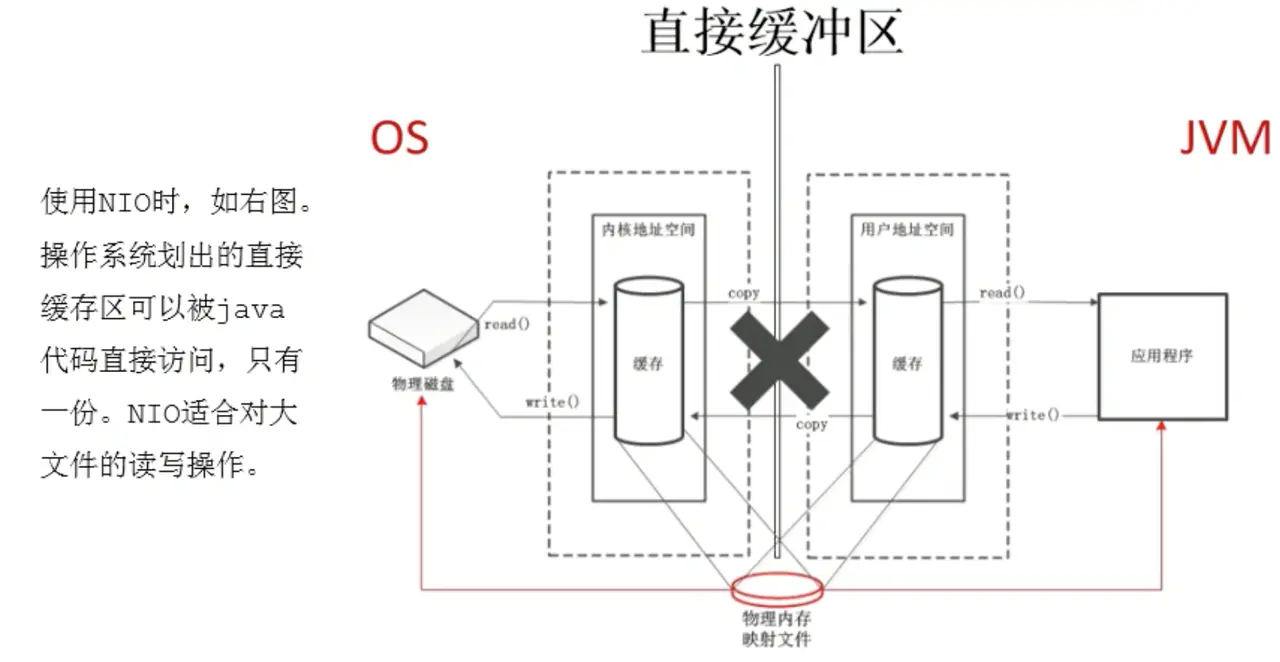
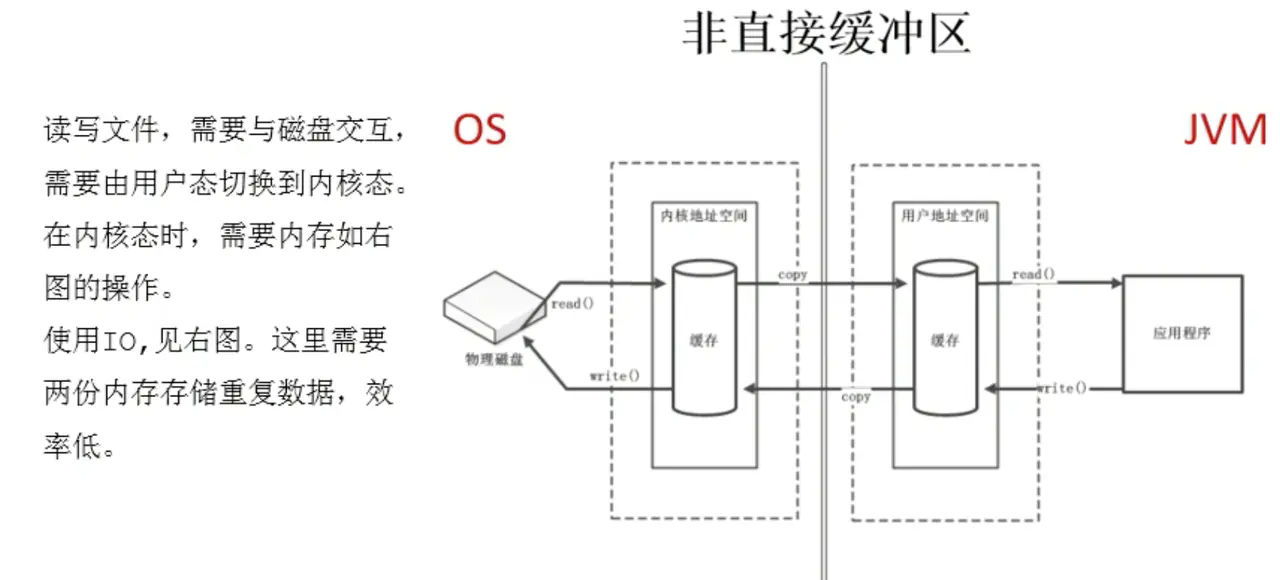
通信原理
堆外内存不受 JVM GC 控制,可以使用堆外内存进行通信,防止 GC 后缓冲区位置发生变化的情况
NIO 使用的 SocketChannel 也是使用的堆外内存,源码解析:
- SocketChannel#write(java.nio.ByteBuffer) → SocketChannelImpl#write(java.nio.ByteBuffer)
public int write(ByteBuffer var1) throws IOException {
do {
var3 = IOUtil.write(this.fd, var1, -1L, nd);
} while(var3 == -3 && this.isOpen());
}
- IOUtil#write(java.io.FileDescriptor, java.nio.ByteBuffer, long, sun.nio.ch.NativeDispatcher)
static int write(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) {
// 【判断是否是直接内存,是则直接写出,不是则封装到直接内存】
if (var1 instanceof DirectBuffer) {
return writeFromNativeBuffer(var0, var1, var2, var4);
} else {
//....
// 从堆内buffer拷贝到堆外buffer
ByteBuffer var8 = Util.getTemporaryDirectBuffer(var7);
var8.put(var1);
//...
// 从堆外写到内核缓冲区
int var9 = writeFromNativeBuffer(var0, var8, var2, var4);
}
}
- 读操作相同
分配回收
直接内存创建 Buffer 对象:static XxxBuffer allocateDirect(int capacity)
DirectByteBuffer 源码分析:
DirectByteBuffer(int cap) {
//....
long base = 0;
try {
// 分配直接内存
base = unsafe.allocateMemory(size);
}
// 内存赋值
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 创建回收函数
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
}
private static class Deallocator implements Runnable {
public void run() {
unsafe.freeMemory(address);
//...
}
}
分配和回收原理:
- 使用了 Unsafe 对象的 allocateMemory 方法完成直接内存的分配,setMemory 方法完成赋值
- ByteBuffer 的实现类内部,使用了 Cleaner(虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 Deallocator 的 run方法,最后通过 freeMemory 来释放直接内存
/**
* 直接内存分配的底层原理:Unsafe
*/
public class Demo1_27 {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = getUnsafe();
// 分配内存
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe;
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
共享内存
FileChannel 提供 map 方法返回 MappedByteBuffer 对象,把文件映射到内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射,完成映射后对物理内存的操作会被同步到硬盘上
FileChannel 中的成员属性:
MapMode.mode:内存映像文件访问的方式,共三种:
MapMode.READ_ONLY:只读,修改得到的缓冲区将导致抛出异常MapMode.READ_WRITE:读/写,对缓冲区的更改最终将写入文件,但此次修改对映射到同一文件的其他程序不一定是可见MapMode.PRIVATE:私用,可读可写,但是修改的内容不会写入文件,只是 buffer 自身的改变public final FileLock lock():获取此文件通道的排他锁
MappedByteBuffer,可以让文件在直接内存(堆外内存)中进行修改,这种方式叫做内存映射,可以直接调用系统底层的缓存,没有 JVM 和 OS 之间的复制操作,提高了传输效率,作用:
- 可以用于进程间的通信,能达到共享内存页的作用,但在高并发下要对文件内存进行加锁,防止出现读写内容混乱和不一致性,Java 提供了文件锁 FileLock,但在父/子进程中锁定后另一进程会一直等待,效率不高
- 读写那些太大而不能放进内存中的文件,分段映射
MappedByteBuffer 较之 ByteBuffer 新增的三个方法:
final MappedByteBuffer force():缓冲区是 READ_WRITE 模式下,对缓冲区内容的修改强制写入文件final MappedByteBuffer load():将缓冲区的内容载入物理内存,并返回该缓冲区的引用final boolean isLoaded():如果缓冲区的内容在物理内存中,则返回真,否则返回假
public class MappedByteBufferTest {
public static void main(String[] args) throws Exception {
// 读写模式
RandomAccessFile ra = new RandomAccessFile("1.txt", "rw");
// 获取对应的通道
FileChannel channel = ra.getChannel();
/**
* 参数1 FileChannel.MapMode.READ_WRITE 使用的读写模式
* 参数2 0: 文件映射时的起始位置
* 参数3 5: 是映射到内存的大小(不是索引位置),即将 1.txt 的多少个字节映射到内存
* 可以直接修改的范围就是 0-5
* 实际类型 DirectByteBuffer
*/
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 5);
buffer.put(0, (byte) 'H');
buffer.put(3, (byte) '9');
buffer.put(5, (byte) 'Y'); //IndexOutOfBoundsException
ra.close();
System.out.println("修改成功~~");
}
}
从硬盘上将文件读入内存,要经过文件系统进行数据拷贝,拷贝操作是由文件系统和硬件驱动实现。通过内存映射的方法访问硬盘上的文件,拷贝数据的效率要比 read 和 write 系统调用高:
- read() 是系统调用,首先将文件从硬盘拷贝到内核空间的一个缓冲区,再将这些数据拷贝到用户空间,实际上进行了两次数据拷贝
- mmap() 也是系统调用,但没有进行数据拷贝,当缺页中断发生时,直接将文件从硬盘拷贝到共享内存,只进行了一次数据拷贝
注意:mmap 的文件映射,在 Full GC 时才会进行释放,如果需要手动清除内存映射文件,可以反射调用 sun.misc.Cleaner 方法
参考文章:https://www.jianshu.com/p/f90866dcbffc
通道
基本介绍
通道(Channel):表示 IO 源与目标打开的连接,Channel 类似于传统的流,只不过 Channel 本身不能直接访问数据,Channel 只能与 Buffer 进行交互
- NIO 的通道类似于流,但有些区别如下:
- 通道可以同时进行读写,而流只能读或者只能写
- 通道可以实现异步读写数据
- 通道可以从缓冲读数据,也可以写数据到缓冲
- BIO 中的 Stream 是单向的,NIO 中的 Channel 是双向的,可以读操作,也可以写操作
- Channel 在 NIO 中是一个接口:
public interface Channel extends Closeable{}
Channel 实现类:
FileChannel:用于读取、写入、映射和操作文件的通道,只能工作在阻塞模式下
通过 FileInputStream 获取的 Channel 只能读
通过 FileOutputStream 获取的 Channel 只能写
通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
DatagramChannel:通过 UDP 读写网络中的数据通道
SocketChannel:通过 TCP 读写网络中的数据
ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel 提示:ServerSocketChanne 类似 ServerSocket、SocketChannel 类似 Socket
常用API
获取 Channel 方式:
- 对支持通道的对象调用
getChannel()方法 - 通过通道的静态方法
open()打开并返回指定通道 - 使用 Files 类的静态方法
newByteChannel()获取字节通道
Channel 基本操作:读写都是相对于内存来看,也就是缓冲区
| 方法 | 说明 |
|---|---|
| public abstract int read(ByteBuffer dst) | 从 Channel 中读取数据到 ByteBuffer,从 position 开始储存 |
| public final long read(ByteBuffer[] dsts) | 将 Channel 中的数据分散到 ByteBuffer[] |
| public abstract int write(ByteBuffer src) | 将 ByteBuffer 中的数据写入 Channel,从 position 开始写出 |
| public final long write(ByteBuffer[] srcs) | 将 ByteBuffer[] 到中的数据聚集到 Channel |
| public abstract long position() | 返回此通道的文件位置 |
| FileChannel position(long newPosition) | 设置此通道的文件位置 |
| public abstract long size() | 返回此通道的文件的当前大小 |
SelectableChannel 的操作 API:
| 方法 | 说明 |
|---|---|
| SocketChannel accept() | 如果通道处于非阻塞模式,没有请求连接时此方法将立即返回 NULL,否则将阻塞直到有新的连接或发生 I/O 错误,通过该方法返回的套接字通道将处于阻塞模式 |
| SelectionKey register(Selector sel, int ops) | 将通道注册到选择器上,并指定监听事件 |
| SelectionKey register(Selector sel, int ops, Object att) | 将通道注册到选择器上,并在当前通道绑定一个附件对象,Object 代表可以是任何类型 |
文件读写
public class ChannelTest {
@Test
public void write() throws Exception{
// 1、字节输出流通向目标文件
FileOutputStream fos = new FileOutputStream("data01.txt");
// 2、得到字节输出流对应的通道 【FileChannel】
FileChannel channel = fos.getChannel();
// 3、分配缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put("hello,黑马Java程序员!".getBytes());
// 4、把缓冲区切换成写出模式
buffer.flip();
channel.write(buffer);
channel.close();
System.out.println("写数据到文件中!");
}
@Test
public void read() throws Exception {
// 1、定义一个文件字节输入流与源文件接通
FileInputStream fis = new FileInputStream("data01.txt");
// 2、需要得到文件字节输入流的文件通道
FileChannel channel = fis.getChannel();
// 3、定义一个缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 4、读取数据到缓冲区
channel.read(buffer);
buffer.flip();
// 5、读取出缓冲区中的数据并输出即可
String rs = new String(buffer.array(),0,buffer.remaining());
System.out.println(rs);
}
}
文件复制
Channel 的方法:sendfile 实现零拷贝
abstract long transferFrom(ReadableByteChannel src, long position, long count):从给定的可读字节通道将字节传输到该通道的文件中src:源通道
position:文件中要进行传输的位置,必须是非负的
count:要传输的最大字节数,必须是非负的
abstract long transferTo(long position, long count, WritableByteChannel target):将该通道文件的字节传输到给定的可写字节通道。position:传输开始的文件中的位置; 必须是非负的
count:要传输的最大字节数; 必须是非负的
target:目标通道
文件复制的两种方式:
- Buffer
- 使用上述两种方法

public class ChannelTest {
@Test
public void copy1() throws Exception {
File srcFile = new File("C:\\壁纸.jpg");
File destFile = new File("C:\\Users\\壁纸new.jpg");
// 得到一个字节字节输入流
FileInputStream fis = new FileInputStream(srcFile);
// 得到一个字节输出流
FileOutputStream fos = new FileOutputStream(destFile);
// 得到的是文件通道
FileChannel isChannel = fis.getChannel();
FileChannel osChannel = fos.getChannel();
// 分配缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
while(true){
// 必须先清空缓冲然后再写入数据到缓冲区
buffer.clear();
// 开始读取一次数据
int flag = isChannel.read(buffer);
if(flag == -1){
break;
}
// 已经读取了数据 ,把缓冲区的模式切换成可读模式
buffer.flip();
// 把数据写出到
osChannel.write(buffer);
}
isChannel.close();
osChannel.close();
System.out.println("复制完成!");
}
@Test
public void copy02() throws Exception {
// 1、字节输入管道
FileInputStream fis = new FileInputStream("data01.txt");
FileChannel isChannel = fis.getChannel();
// 2、字节输出流管道
FileOutputStream fos = new FileOutputStream("data03.txt");
FileChannel osChannel = fos.getChannel();
// 3、复制
osChannel.transferFrom(isChannel,isChannel.position(),isChannel.size());
isChannel.close();
osChannel.close();
}
@Test
public void copy03() throws Exception {
// 1、字节输入管道
FileInputStream fis = new FileInputStream("data01.txt");
FileChannel isChannel = fis.getChannel();
// 2、字节输出流管道
FileOutputStream fos = new FileOutputStream("data04.txt");
FileChannel osChannel = fos.getChannel();
// 3、复制
isChannel.transferTo(isChannel.position() , isChannel.size() , osChannel);
isChannel.close();
osChannel.close();
}
}
分散聚集
分散读取(Scatter ):是指把 Channel 通道的数据读入到多个缓冲区中去
聚集写入(Gathering ):是指将多个 Buffer 中的数据聚集到 Channel
public class ChannelTest {
@Test
public void test() throws IOException{
// 1、字节输入管道
FileInputStream is = new FileInputStream("data01.txt");
FileChannel isChannel = is.getChannel();
// 2、字节输出流管道
FileOutputStream fos = new FileOutputStream("data02.txt");
FileChannel osChannel = fos.getChannel();
// 3、定义多个缓冲区做数据分散
ByteBuffer buffer1 = ByteBuffer.allocate(4);
ByteBuffer buffer2 = ByteBuffer.allocate(1024);
ByteBuffer[] buffers = {buffer1 , buffer2};
// 4、从通道中读取数据分散到各个缓冲区
isChannel.read(buffers);
// 5、从每个缓冲区中查询是否有数据读取到了
for(ByteBuffer buffer : buffers){
buffer.flip();// 切换到读数据模式
System.out.println(new String(buffer.array() , 0 , buffer.remaining()));
}
// 6、聚集写入到通道
osChannel.write(buffers);
isChannel.close();
osChannel.close();
System.out.println("文件复制~~");
}
}
选择器
基本介绍
选择器(Selector) 是 SelectableChannle 对象的多路复用器,Selector 可以同时监控多个通道的状况,利用 Selector 可使一个单独的线程管理多个 Channel,Selector 是非阻塞 IO 的核心
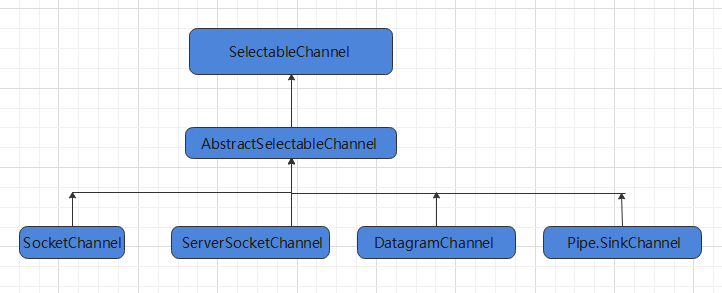
- Selector 能够检测多个注册的通道上是否有事件发生(多个 Channel 以事件的方式可以注册到同一个 Selector),如果有事件发生,就获取事件然后针对每个事件进行相应的处理,就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求
- 只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程
- 避免了多线程之间的上下文切换导致的开销
常用API
创建 Selector:Selector selector = Selector.open();
向选择器注册通道:SelectableChannel.register(Selector sel, int ops, Object att)
参数一:选择器,指定当前 Channel 注册到的选择器
参数二:选择器对通道的监听事件,监听的事件类型用四个常量表示
读 : SelectionKey.OP_READ (1)
写 : SelectionKey.OP_WRITE (4)
连接 : SelectionKey.OP_CONNECT (8)
接收 : SelectionKey.OP_ACCEPT (16)
若不止监听一个事件,使用位或操作符连接:
int interest = SelectionKey.OP_READ | SelectionKey.OP_WRITE参数三:可以关联一个附件,可以是任何对象
Selector API:
| 方法 | 说明 |
|---|---|
| public static Selector open() | 打开选择器 |
| public abstract void close() | 关闭此选择器 |
| public abstract int select() | 阻塞选择一组通道准备好进行 I/O 操作的键 |
| public abstract int select(long timeout) | 阻塞等待 timeout 毫秒 |
| public abstract int selectNow() | 获取一下,不阻塞,立刻返回 |
| public abstract Selector wakeup() | 唤醒正在阻塞的 selector |
| public abstract Set selectedKeys() | 返回此选择器的选择键集 |
SelectionKey API:
| 方法 | 说明 |
|---|---|
| public abstract void cancel() | 取消该键的通道与其选择器的注册 |
| public abstract SelectableChannel channel() | 返回创建此键的通道,该方法在取消键之后仍将返回通道 |
| public final Object attachment() | 返回当前 key 关联的附件 |
| public final boolean isAcceptable() | 检测此密钥的通道是否已准备好接受新的套接字连接 |
| public final boolean isConnectable() | 检测此密钥的通道是否已完成或未完成其套接字连接操作 |
| public final boolean isReadable() | 检测此密钥的频道是否可以阅读 |
| public final boolean isWritable() | 检测此密钥的通道是否准备好进行写入 |
基本步骤:
//1.获取通道
ServerSocketChannel ssChannel = ServerSocketChannel.open();
//2.切换非阻塞模式
ssChannel.configureBlocking(false);
//3.绑定连接
ssChannel.bin(new InetSocketAddress(9999));
//4.获取选择器
Selector selector = Selector.open();
//5.将通道注册到选择器上,并且指定“监听接收事件”
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
NIO实现
常用API
- SelectableChannel_API
| 方法 | 说明 |
|---|---|
| public final SelectableChannel configureBlocking(boolean block) | 设置此通道的阻塞模式 |
| public final SelectionKey register(Selector sel, int ops) | 向给定的选择器注册此通道,并选择关注的的事件 |
- SocketChannel_API:
| 方法 | 说明 |
|---|---|
| public static SocketChannel open() | 打开套接字通道 |
| public static SocketChannel open(SocketAddress remote) | 打开套接字通道并连接到远程地址 |
| public abstract boolean connect(SocketAddress remote) | 连接此通道的到远程地址 |
| public abstract SocketChannel bind(SocketAddress local) | 将通道的套接字绑定到本地地址 |
| public abstract SocketAddress getLocalAddress() | 返回套接字绑定的本地套接字地址 |
| public abstract SocketAddress getRemoteAddress() | 返回套接字连接的远程套接字地址 |
- ServerSocketChannel_API:
| 方法 | 说明 |
|---|---|
| public static ServerSocketChannel open() | 打开服务器套接字通道 |
| public final ServerSocketChannel bind(SocketAddress local) | 将通道的套接字绑定到本地地址,并配置套接字以监听连接 |
| public abstract SocketChannel accept() | 接受与此通道套接字的连接,通过此方法返回的套接字通道将处于阻塞模式 |
- 如果 ServerSocketChannel 处于非阻塞模式,如果没有挂起连接,则此方法将立即返回 null
- 如果通道处于阻塞模式,如果没有挂起连接将无限期地阻塞,直到有新的连接或发生 I/O 错误
代码实现
服务端 :
- 获取通道,当客户端连接服务端时,服务端会通过
ServerSocketChannel.accept得到 SocketChannel - 切换非阻塞模式
- 绑定连接
- 获取选择器
- 将通道注册到选择器上,并且指定监听接收事件
- 轮询式的获取选择器上已经准备就绪的事件
客户端:
- 获取通道:
SocketChannel sc = SocketChannel.open(new InetSocketAddress(HOST, PORT)) - 切换非阻塞模式
- 分配指定大小的缓冲区:
ByteBuffer buffer = ByteBuffer.allocate(1024) - 发送数据给服务端
37 行代码,如果判断条件改为 !=-1,需要客户端 close 一下
public class Server {
public static void main(String[] args){
// 1、获取通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 2、切换为非阻塞模式
serverSocketChannel.configureBlocking(false);
// 3、绑定连接的端口
serverSocketChannel.bind(new InetSocketAddress(9999));
// 4、获取选择器Selector
Selector selector = Selector.open();
// 5、将通道都注册到选择器上去,并且开始指定监听接收事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// 6、使用Selector选择器阻塞等待轮已经就绪好的事件
while (selector.select() > 0) {
System.out.println("----开始新一轮的时间处理----");
// 7、获取选择器中的所有注册的通道中已经就绪好的事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> it = selectionKeys.iterator();
// 8、开始遍历这些准备好的事件
while (it.hasNext()) {
SelectionKey key = it.next();// 提取当前这个事件
// 9、判断这个事件具体是什么
if (key.isAcceptable()) {
// 10、直接获取当前接入的客户端通道
SocketChannel socketChannel = serverSocketChannel.accept();
// 11 、切换成非阻塞模式
socketChannel.configureBlocking(false);
/*
ByteBuffer buffer = ByteBuffer.allocate(16);
// 将一个 byteBuffer 作为附件【关联】到 selectionKey 上
SelectionKey scKey = sc.register(selector, 0, buffer);
*/
// 12、将本客户端通道注册到选择器
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 13、获取当前选择器上的读就绪事件
SelectableChannel channel = key.channel();
SocketChannel socketChannel = (SocketChannel) channel;
// 14、读取数据
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 获取关联的附件
// ByteBuffer buffer = (ByteBuffer) key.attachment();
int len;
while ((len = socketChannel.read(buffer)) > 0) {
buffer.flip();
System.out.println(socketChannel.getRemoteAddress() + ":" + new String(buffer.array(), 0, len));
buffer.clear();// 清除之前的数据
}
}
// 删除当前的 selectionKey,防止重复操作
it.remove();
}
}
}
}
public class Client {
public static void main(String[] args) throws Exception {
// 1、获取通道
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 9999));
// 2、切换成非阻塞模式
socketChannel.configureBlocking(false);
// 3、分配指定缓冲区大小
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 4、发送数据给服务端
Scanner sc = new Scanner(System.in);
while (true){
System.out.print("请说:");
String msg = sc.nextLine();
buffer.put(("Client:" + msg).getBytes());
buffer.flip();
socketChannel.write(buffer);
buffer.clear();
}
}
}
AIO
Java AIO(NIO.2) : AsynchronousI/O,异步非阻塞,采用了 Proactor 模式。服务器实现模式为一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理
AIO异步非阻塞,基于NIO的,可以称之为NIO2.0
BIO NIO AIO
Socket SocketChannel AsynchronousSocketChannel
ServerSocket ServerSocketChannel AsynchronousServerSocketChannel
当进行读写操作时,调用 API 的 read 或 write 方法,这两种方法均为异步的,完成后会主动调用回调函数:
- 对于读操作,当有流可读取时,操作系统会将可读的流传入 read 方法的缓冲区
- 对于写操作,当操作系统将 write 方法传递的流写入完毕时,操作系统主动通知应用程序
在 JDK1.7 中,这部分内容被称作 NIO.2,主要在 Java.nio.channels 包下增加了下面四个异步通道: AsynchronousSocketChannel、AsynchronousServerSocketChannel、AsynchronousFileChannel、AsynchronousDatagramChannel